Update:
2015-12-18 06:20 AM -0500
TIL
Words and their meanings in human languages
word.htm
collection by U Kyaw Tun, M.S. (I.P.S.T., U.S.A.).
Not for sale. No copyright. Free for
everyone. Prepared for students and
staff of TIL Research Station, Yangon,
MYANMAR :
http://www.tuninst.net ,
www.romabama.blogspot.com
index.htm | |Top
lang-mean-indx.htm
From Burmese to Georgian

Human communication
Word :
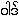 {waad}
{waad}
Content word
Function word
Concordance : principal words in body of
works such as the Bible
Orthography
Morphology
Desinence or suffix used as an inflection
Lexeme vs. morpheme vs. phonemes
: the three ESL devils for
Burmese-speakers
UKT notes
•
clitic
• compound
•
Concordance: Cruden's
•
devoicing (medial formation)
• KWIC :
acronym Key Word In Context
•
lemma (head word)
•
lexis
•
Linguistics of sign
•
Panini
पाणिनि «pāṇini»
 {pa-Ni.ni.}
{pa-Ni.ni.}
• phoneme
•
portmanteau
•
pratibhā
•
pragmatics
• prosody
• root and suffix
• semantics
•
Sabda-brahman
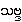
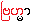 {þûb~da. brah~ma}
{þûb~da. brah~ma}
•
synthetic language (inflectional)
• word stem
• Yaska
यास्क
(= य ा स ् क) «yāska»:
 {yaaþ~ka.}
{yaaþ~ka.}
Noteworthy passages in this file:
(always check with the original section from
which they are taken.)
• Semantics is the study of meaning.
• Dictionaries define the specific
meanings of content words [e.g. nouns, verbs],
but can only describe the general usages of
function words. By contrast, grammars
describe the use of function words in detail,
but treat [content] lexical words [e.g.
articles, pronouns] in general terms only.
• Stems may be roots, e.g.
<run>, or they may be morphologically
complex, as in compound words (cf. the
compound nouns meat ball or bottle
opener) or words with derivational
morphemes (cf. the derived verbs
black-en or standard-ize).
• The exact use of the word 'stem'
depends on the morphology of the
language is question.
Contents of this page
- UKT 151215

I keep myself reminded that
Bur-Myan - but not Pali-Myan - is almost
devoid of inflections found in Eng-Lat
and Skt-Dev, because of which attempts
to analyze the Bur-Myan language through
the traditional use of inflections has
failed.
Now I have a question: What was Magadhi-Asokan like?
UKT 151215: The script on the Asoka inscriptions is now known as
"Brahmi". However since the
 {braah~ma.Na. poaN~Na:} could not decipher it when called upon by their
Muslim emperor to do so, they have no claim to it. I was looking for a
suitable term when I came across the term "Asokan" in
F. Edgerton, Buddhist Hybrid
Sanskrit Grammar and Dictionary,
{braah~ma.Na. poaN~Na:} could not decipher it when called upon by their
Muslim emperor to do so, they have no claim to it. I was looking for a
suitable term when I came across the term "Asokan" in
F. Edgerton, Buddhist Hybrid
Sanskrit Grammar and Dictionary,
-
BHS-indx.htm (link chk 151215)
Let us not forget
that Magadhi-Asokan was introduced into
northern Myanmarpré, particularly to the
Tagaung Kingdom, during the life-time of
Gautama Buddha, and many centuries before,
in the days of King Abhiraza. I am sure
(but still a conjecture) the original
Magadhi-Asokan was given a death blow when
King Anawrahta persecuted the Bur-Myan
speaking Arigyi because of their sexual
misconduct introduced with Tantric Buddhism
from Nalanda University, and introduced the
Mon-Myan speaking monks from Thaton in
southern Myanmarpré.
See Wikipedia for development of Tantric Buddhism at Nalanda University during
the time of Pala Empire (8th c AD - 12th c AD).
-
https://en.wikipedia.org/wiki/Nalanda 151215
UKT 151207: Though Bur-Myan is a phonetic
language, few including those in Myanmar
Language Commission (MLC) in Myanmarpré know
that it is so. They think that
Alphabet-Letter and Abugida-Akshara
 {ak~hka.ra} writing systems are the same. See
{ak~hka.ra} writing systems are the same. See
¤
- n. character, letter of an alphabet;
alphabet - MLC MED2006-619
We should study our own language and its grammar by going back to the
pre-colonial days and see what it was really like. See:
¤ Burmese Grammar and Grammatical
Analysis 1899 by A. W. Lonsdale, Rangoon:
British Burma Press, 1899 xii, 461, in two
parts. Part 1. Orthoepy and orthography;
Part 2. Accidence and syntax
-
BurMyan-indx.htm >
BG1899-indx.htm >
BG1899-1-indx.htm >
ch00.htm (links chk 151215)
The following are what A. W. Lonsdale has
written:
"
• The Burmese language is constructed on
scientific principles, and there is no
reason why its grammar should not be dealt
with also from a scientific standpoint. But
it may be safely said that Burmese grammar
as a science has not received that
attention it deserves.
"
• With regard to the grammatical treatises
by native writers, it is no exaggeration
to say that there is not one which can be
properly called a Burmese grammar. These
writers, not content with merely borrowing
the grammatical nomenclature of the Pali
language, also attempted to assimilate the
grammatical principles of the
uninflected Burmese to those of the
inflected Pali; so that they
produced, not Burmese grammars, but modified
Pali grammars in Burmese dress. The
servile veneration in which they held Pali,
the language they had adopted as the classic,
is, no doubt, directly responsible for the
composition of such works. In their endeavour
to conform strictly to Pali methods, they
often introduced unnecessary terms and
misapplied them, ignoring those grammatical
points in Burmese for which they could find
no parallel in Pali. How futile their
attempts were may be judged by the numerous
difficulties and anomalies they created,
from some of which even now teachers of the
language have not quite extricated themselves
- take, for instance, the case-inflexions."
The Letter is the basic-unit of the writing
system known as the Alphabet. Letter is mute, i.e.
non-pronounceable. It needs a vowel to turn
it into a syllable.
On the other hand, the Akshara
{ak~hka.ra} is the basic-unit of a different
writing system now known as the Abugida. It is
pronounceable by itself because it contains an
inherent vowel. It is a syllable. Applying a
Virama 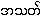 {a.þût} will kill the inherent vowel and
turn it into a Letter.
{a.þût} will kill the inherent vowel and
turn it into a Letter.
An illustrative example of the difference can
be found when we compare Georgian (alphabet)
and Myanmar (abugida) scripts.
Myanmar to Georgian:
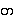 {ta.} + viram
{a.þût}
--> თ (U+10D7, Georgian Letter
Tan)
{ta.} + viram
{a.þût}
--> თ (U+10D7, Georgian Letter
Tan)
Georgian to Myanmar:
თ (U+10D7, Georgian Letter Tan)
+ ა (U+10D0, Georgian
Letter An) -->
{ta.}
Note: ა (U+10D0, Georgian Letter An)
is the inverse of
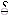 (Myanmar viram sign), e.g.
(Myanmar viram sign), e.g.
ა - the vowel giver
 - the vowel killer
- the vowel killer
Contents of this page
-- UKT 090902, 151214

The problem of communicating among the various
peoples who speak/(do not speak) and write/(sign)
different languages has become very pressing in
this age of rapid communication especially
through electronic means. When a person
communicates with another he uses a
"language". Those who could not speak
nor hear (deaf and dumb) use various sign
languages which are not by any means simple sign
signals. They are languages in their own rights
with their own syntax and lexicon
and there are many all over the world.
However, since my present task is the study of
Pal-Myan and Skt-Dev through Bur-Myan and
Engl-Latin, the problem of communicating in
sign languages is beyond the scope of my study.
But I intend to go into the subject of
presenting the message of the Buddha to
Hearing-Speaking challenged (Deaf-Mutes)
eventually. -
sign.htm
syntax n. 1. a. The
study of the rules whereby words or other
elements of sentence structure are combined
to form grammatical sentences.
b. A publication, such as a book,
that presents such rules.
c. The pattern of formation of
sentences or phrases in a language.
d. Such a pattern in a particular
sentence or discourse.
2. Computer Science The rules
governing construction of a machine language.
3. A systematic, orderly arrangement.
[French syntaxe from Late Latin
syntaxis from Greek suntaxis
from suntassein put in order
sun- syn- tassein tag -- to
arrange] -- AHTD
UKT: In terms of syntax, ASL (American
Sign Language) shares more with spoken
Japanese than it does with English.
-- Wikipedia:
http://en.wikipedia.org/wiki/Sign_language
090902
lexicon n. pl. lexicons
or lexica Abbr. lex.
1. A dictionary. 2. A stock of
terms used in a particular profession,
subject, or style; a vocabulary: the lexicon
of surrealist art. 3. Linguistics
The morphemes of a language considered as a
group. [Medieval Latin from Greek lexiHHon
(biblion) word (book), from neuter of lexikos
of words from lexis word from legein to speak;
See leg- in Indo-European Roots.] -- AHTD
The problem of communicating using sound in a
specific language depend on the pronunciation of
the speaker and the ability of the listener to
interpret the sound-words he has heard. However,
when the written script is used, the
pronunciation does not come in. Yet the speaker
and the listener must have a common grammar and
a common vocabulary for effective transfer of
ideas.
 The problem of understanding the sound-words has
come before the time of the Buddha himself. And
during his life time as recorded in the Cullavagga
The problem of understanding the sound-words has
come before the time of the Buddha himself. And
during his life time as recorded in the Cullavagga
 {su-La.wag~ga.},
V. 33. 1 of the Pali Canon.
I have included this story in a different file,
lang-probl.htm (link chk 151214), and the
reader is advised to read the whole paper by
Chi Hisen-lin, Journal of the Burma Research
Society, XLIII, i, June 1960. The following
is the very first part of that paper:
{su-La.wag~ga.},
V. 33. 1 of the Pali Canon.
I have included this story in a different file,
lang-probl.htm (link chk 151214), and the
reader is advised to read the whole paper by
Chi Hisen-lin, Journal of the Burma Research
Society, XLIII, i, June 1960. The following
is the very first part of that paper:
What language was used by primitive Buddhism?
This is a problem yet unsolved among the
learned circles. Based upon some new materials
I [Chi Hisen-lin] wish to propose my [his]
personal views concerning this problem. In the
Cullavagga, V. 33. 1, there is narrated the
following story:
"Now there were two Bhikkhus surnamed
Yamelutekula, who were brothers born in a
Brahman family. They had good voice and were
expert in conversation. They came to the
presence of the Blessed One, to whom they paid
their homage and sat aside. After having taken
their seat, the two Bhikkhus said to the
Blessed One,
'Bhante, now the Bhikkhus with different
family names and personal names, of
different social ranks and families, have
come to join the Order. With their own
vernaculars they have marred the Buddha's
words. Please permit us to express the
Buddha's words in Sanskrit.'
"The Buddha reproached them, saying,
'You fools, how dare you say, "Please
permit us to express the Buddha's words in
Sanskrit!" Fools, by doing so you could
neither induce those who did not have faith
in the Buddha to have faith in him, nor could
you enhance the faith of those who already
had it in the Buddha. You could only help
those who did not believe in the Buddha and
change the mind of those who already believed
in him.'
"After having reprimanded them, he preached
the Dhamma for them, and then said to the
Bhikkhus,
'Bhikkhus, you are not allowed to express the
Buddha's words in Sanskrit. Those who act
contrarily will be considered as having
committed the offence of Dukkata
 {doak~ka.Ta.}.'
fn09-01
{doak~ka.Ta.}.'
fn09-01
fn09-01.
The Vinaya Pitakam, ed. by
Hermann Olderberg, Vol. II, The
Cullavagga, London, 1880, p. 139.
fn09-01b
"And finally the Buddha said,
anujānāmi bhikkhave sakāya niruttiyā
buddhavacanam pariyāpunitum
"A comparatively important problem of
primitive Buddhism, the problem of language,
is involved in this story. Buddhism during
the period of its initiation may be considered,
in many respects, as a sort of resistance or
revolution against Brahmanism, the principal
religion that occupied the position of
predomination at the time. It was but natural
that it should have opposed with determination
the use of Sanskrit, the language of
Brahmanism. [UKT 151208]
UKT 151214: It is my firm belief that Language
as a means of communication between human
individuals is religion-neutral. We should
avoid using words like: "Sanskrit, the
language of Brahmanism", and "Pali,
the language of Theravada Buddhism".
Moreover, it is a known fact that speech is
transitory, whereas script is more permanent.
In order to specify what we mean by
"Language", we should specify the
script in which speech is written as:
Burmese-Myanmar (Bur-Myan), English-Latin
(Eng-Lat), Pali-Myanmar (Pal-Myan), and,
Sanskrit-Devanagari (Skt-Dev). Thus my
invention Romabama is Bur-Lat. It is not
"Burglish". Moreover, Romabama
stands for
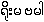 {ro:ma.ba.ma} the 'backbone of Bur-Myan'.
If you follow this rule strictly you will
see that Vedic (or Vedic-Asokan) is different
from Sanskrit (or Skt-Dev). What the
phonetician or grammarian
Paṇini
पाणिनि
«pāṇini»
{ro:ma.ba.ma} the 'backbone of Bur-Myan'.
If you follow this rule strictly you will
see that Vedic (or Vedic-Asokan) is different
from Sanskrit (or Skt-Dev). What the
phonetician or grammarian
Paṇini
पाणिनि
«pāṇini»
 {pa-Ni.ni.} was doing was to lay down rules
for transcribing Vedic into Sanskrit.
Yaska
यास्क
(= य ा स ् क)
«yāska»
{yaaþ~ka.}, his predecessor, was the Vedic
phonetician or grammarian.
{pa-Ni.ni.} was doing was to lay down rules
for transcribing Vedic into Sanskrit.
Yaska
यास्क
(= य ा स ् क)
«yāska»
{yaaþ~ka.}, his predecessor, was the Vedic
phonetician or grammarian.
"In spite of the fact that during
the 5th and 6th centuries B.C., the development
of the Sanskrit language had reached its zenith,
and if used, it would bring many advantages for
the propagation of the Buddhist doctrines, but
for the sake of carrying out his own ideas, the
Buddha would not consider the use of that
language and scolded the two Bhikkhus as
"fools" Probably because they were
the descendants of a Brahman family, these two
Bhikkhus still had some old conceptions in their
brains. That was why they made the proposal to
the Buddha for the adoption of Sanskrit and
incurred his rebuke.
UKT 090902, 151210 : It is well worth noting
that the 5th and 6th centuries B.C. means
periods during the Iron Age (1200 B.C. - 1 B.C.)
in India and the life time of the prominent
linguist Panini. He was a Brahman linguist
(or grammarian), and he is said to have
mentioned the works of others who preceded
him centuries before. It was
Pāṇini who gave rules for
transcribing Vedic - most probably a Tib-Myan
language - into Classical Sanskrit - an IE
language.
The Buddha must have known all about them,
their religion (Hinduism) and their language
(Sanskrit). The problem was Sanskrit and the
notions of
Sabda-brahman
{þûb~da. brah~ma} and Mahabrahma as the
Creator were so intertwined that once
Sanskrit was adopted as the language to
propagate Buddhism, it would erode the very
idea of Anatta
 {a.nût~ta.} 'Impermanence' the mainstay
of Buddhism. To the Buddha, the essence of
understanding - not the exact pronunciation
of a word such as Om - is more important
than the sound vibrations in the air. He
would have known about the problem of
conveying his message to the Hearing-Speaking
challenged (Deaf-Mutes) through speech-sound.
My question is that "Did he tried to
preach to the Deaf-Mutes?". If he did,
in what "Language"?
{a.nût~ta.} 'Impermanence' the mainstay
of Buddhism. To the Buddha, the essence of
understanding - not the exact pronunciation
of a word such as Om - is more important
than the sound vibrations in the air. He
would have known about the problem of
conveying his message to the Hearing-Speaking
challenged (Deaf-Mutes) through speech-sound.
My question is that "Did he tried to
preach to the Deaf-Mutes?". If he did,
in what "Language"?
"If Sanskrit was not used, then what
language did they use? For the propagation
of religion, the "policy of language"
was a comparatively important problem, which
must be settled. The Buddha's last sentence
in the above story was for the solution of
this problem. [end JBRS p09]"
UKT 090807: Though the question of using Sanskrit
to express Buddha's words should have been laid
to rest with the above rule laid down by the
Buddha, it is not so because the question
resurfaced in our times around the meaning of the
word of nirutti . So it is imperative to
concentrate on
Nirukta (and
Nighaṇṭu),
a work/works by Yāska
(यास्कः
 {yaaþ~ka:}) in
lang.htm , an ancient Sanskrit grammarian.
Refer to Wikipedia articles
http://en.wikipedia.org/wiki/Nirukta
090806 and
http://en.wikipedia.org/wiki/Vedas 090807.
At the present Nirukta has been identified with
Etymology.
{yaaþ~ka:}) in
lang.htm , an ancient Sanskrit grammarian.
Refer to Wikipedia articles
http://en.wikipedia.org/wiki/Nirukta
090806 and
http://en.wikipedia.org/wiki/Vedas 090807.
At the present Nirukta has been identified with
Etymology.
Nirukta
 {ni.roat~ti.} (PMDict-495) nirutti
(Sk. nirukti ) (PTSDict-370) in Pali means:
{ni.roat~ti.} (PMDict-495) nirutti
(Sk. nirukti ) (PTSDict-370) in Pali means:
- one
of the Vedāngas, explanation of words, grammatical
analysis, etymological interpretation, pronunciation,
dialect, way of speaking, expression.
Nighaṇṭu
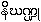 {ni.GaN-Tu.} (PMDict-480) Nighaṇḍu [Sk. nighaṇṭu
...] an explained word or a word explanation, vocabulary, gloss, usually in
ster. formula marking the accomplishments of a learned Brahmin ... --
PTSDict-355
{ni.GaN-Tu.} (PMDict-480) Nighaṇḍu [Sk. nighaṇṭu
...] an explained word or a word explanation, vocabulary, gloss, usually in
ster. formula marking the accomplishments of a learned Brahmin ... --
PTSDict-355
Contents of this page
UKT151209: By the word "Word"
{waad} we do not
mean the Eternal Verbum (Eng-Lat);
dei verbum (Roman-Latin); or
śabda-brahman (Skt-Lat), which all
mean "the Word of the Creator or the Brahma. Here we mean the word used by a
human speaker/writer and a human hearer/reader.
That the "Word" is the "Word of the Creator or the Brahma" is the view held by Bhartṛhari. His philosophy of language is ultimately grounded in a
monistic and idealistic metaphysical theory. He speaks of a transcendental
word-essence (śabdatattva) as the first principle of the universe.
See
LANGUAGE AND THOUGHT -
lang-thot-indx.htm (link chk 151218)
and proceed to
Bhartṛhari's Syntax, Meaning, Sphoṭa -
spho-bartri-matilal.htm
Such a view has been a hindrance to the progress of European Science in the
Middle Ages. See Wikipedia:
-
https://en.wikipedia.org/wiki/European_science_in_the_Middle_Ages 151218
UKT 090814, 151209: There are two main headings under which words are
studied: Lexicology and Morphology. These two
topics are presented in their own files:
lexico.htm and
morpho.htm respectively.
Lexicology (from lexiko-, in
the Late Greek lexikon) is that part of linguistics
which studies words [singly (lexemes) or grouped
(lexical items)], their nature and meaning, words' elements,
relations between words (semantical relations), words groups
and the whole lexicon.
Morphology is the identification, analysis
and description of the structure of words. While words
are generally accepted as being (with clitics) the smallest
units of syntax, it is clear that in most (if not all)
languages, words can be related to other words by rules.
From Wikipedia:
http://en.wikipedia.org/wiki/Word 090814
A word is the smallest free form (an item that may be
uttered in isolation with
semantic or
pragmatic
content) in a language, in contrast to a
morpheme,
which is the smallest unit of meaning. A word may consist of
only one morpheme (e.g. <cat>), but a single morpheme
may not be able to exist as a free form (e.g. the English
plural morpheme <-s>).
UKT:
morpheme n. Linguistics 1. A meaningful linguistic unit
consisting of a word, such as <man>, or a word element,
such as <-ed> in <walked>, that cannot be divided
into smaller meaningful parts. [French morphème blend
of Greek morphē form French phonème phoneme;
See phoneme
-- AHTD
polymorphemic (linguistics) 1.
Comprising multiple morphemes.
Etymology: poly- + morpheme + -ic
--
http://www.allwords.com/word-polymorphemic.html 090814
UKT example:
¤ monomorphemic word, e.g. <cat>, <walk>
¤ polymorphemic word, e.g. <cats>, <walked>
Typically, a word will consist of a
root , or
stem,
and zero or more affixes. [UKT ¶ ]
Words can be combined to create other units of language, such as
phrases, clauses, and/or sentences. A word consisting
of two or more stems joined together form a
compound.
A word combined with an already existing word or part of a word form a
portmanteau.
Definitions
Depending upon the language in question, it can be either easy
or difficult to identify or decipher a word. Dictionaries take
upon themselves the task of categorizing a language's lexicon into
lemmas. These can be taken as an indication of what
constitutes a "word" in the opinion of the authors.
Word boundaries
In spoken language, the distinction of individual words is
usually given by rhythm or accent, but short words are
often run together. See
clitic for
phonologically dependent words. For example, spoken
French has some of the features of a
polysynthetic language: il y est allé ("He went
there"), pronounced [iljɛtale]. Since the majority
of the world's languages are not written, the scientific
determination of word boundaries becomes important.
There are five ways to determine where the word boundaries of spoken language
should be placed:
1. Potential pause : A speaker is told to repeat a given sentence
slowly, allowing for pauses. The speaker will tend to insert pauses at the
word boundaries. However, this method is not foolproof: the speaker could
easily break up polysyllabic words.
2. Indivisibility : A speaker is told to say a
sentence out loud, and then is told to say the sentence again with extra
words added to it. Thus, I have lived in this village for ten years
might become My family and I have lived in this little village for about
ten or so years. These extra words will tend to be added in the word
boundaries of the original sentence. However, some languages have
infixes, which are put inside a word. Similarly, some have
separable affixes; in the German sentence "Ich komme
gut zu Hause an," the verb ankommen is separated.
3. Minimal free forms : This concept was proposed by
Leonard Bloomfield in 1926. Words are thought of as the smallest
meaningful unit of speech that can stand by themselves.
[1]
This correlates phonemes (units of sound) to
lexemes
(units of meaning). However, some written words are not minimal free forms,
as they make no sense by themselves (for example, the and of ).
[2]
4. Phonetic boundaries : Some languages have particular rules of
pronunciation that make it easy to spot where a word boundary should be.
For example, in a language that regularly stresses the last syllable
of a word, a word boundary is likely to fall after each stressed syllable.
Another example can be seen in a language that has
vowel harmony (like Turkish)
[3]: the vowels within a given word
share the same quality, so a word boundary is likely to occur
whenever the vowel quality changes. Nevertheless, not all languages
have such convenient phonetic rules, and even those that do
present the occasional exceptions.
UKT: An interesting term above is vowel harmony (and consonant
harmony). I have prepared a file on the topic in
harmo.htm
. I need to study more if Burmese has vowel harmony.
5. Semantic units : Much like the above mentioned
minimal free forms, this method breaks down a sentence
into its smallest semantic units [meaningful units]. However,
language often contains words that have little semantic
value (and often play a more grammatical role), or
semantic units that are compound words.
A further criterion. Pragmatics.
As Plag suggests, the idea of a lexical item being considered a word should
also adjust to pragmatic criteria. The word <hello>, for example,
does not exist outside of the realm of greetings being difficult to assign
a meaning out of it. This is a little more complex if we consider
<how do you do?>: is it a word, a phrase, or an idiom? In practice,
linguists apply a mixture of all these methods to determine the word boundaries
of any given sentence. Even with the careful application of these methods,
the exact definition of a word is often still very elusive.
There are some words that seem very general, but may truly have a technical
definition, such as the word "soon," usually meaning within a week.
UKT: Continued in the another section as Orthography .
Contents of this page
Content word : lexical word
Lexemes and Lexical items
Lexical category or lexical class
Excerpt from:
http://en.wikipedia.org/wiki/Function_word 090822
Words that are not function words are called
content words (or lexical words): these include
nouns, verbs, adjectives, and most adverbs,
although some adverbs are function words (e.g., <then> and <why>).
[UKT ¶ ]
Dictionaries define the specific meanings of content words, but can
only describe the general usages of function words. By contrast,
grammars describe the use of function words in detail, but treat
lexical words in general terms only.
Excerpt Wikipedia:
http://en.wikipedia.org/wiki/Word_class 090804
In grammar, a lexical category (also word class,
lexical class, or in traditional grammar part of speech)
is a linguistic category of words (or more precisely lexical
items), which is generally defined by the syntactic or
morphological behaviour of the lexical item in question.
Common linguistic categories include noun and verb,
among others. There are open word classes, which
constantly acquire new members, and closed word classes,
which acquire new members infrequently if at all.
UKT 090830: In English, open word classes include
the following parts of speech: nouns, main verbs
(not auxiliary verbs), adjectives, adverbs, interjections.
-- Wikipedia
http://en.wikipedia.org/wiki/Open_class_word 090830
Whereas, closed word classes found in many languages are
adpositions (prepositions and postpositions), determiners,
conjunctions, and pronouns.
-- Wikipedia
http://en.wikipedia.org/wiki/Closed_class_word 090830.
Different languages may have different lexical categories, or
they might associate different properties to the same one.
For example, Japanese has as many as three classes of adjectives
where English has one; Chinese, Korean and Japanese have
measure words while European languages do not grammaticalize
these units of measurement (a "pair of pants", a
"grain of rice"); many languages don't have a distinction
between adjectives and adverbs, adjectives and verbs (see
stative verbs) or adjectives and nouns , etc. [UKT ¶ ]
UKT 090826: Measure words in Burmese-Myanmar: {lu tic-yauk}
'one man', {hkwé: nhic-kaung} 'two dogs', {toat tic-hkyaung:}
'one stick' . Measure words are most often used when counting.
Their use is analogous to English words that represent units or
portions of mass nouns, for example <one drop of milk>,
<ten grains of rice>, <fifty heads of
cattle>, <three pieces of cake>.
-- based on Wikipedia:
http://en.wikipedia.org/wiki/Measure_word 090826
Many linguists argue that the formal distinctions between
parts of speech must be made within the framework of a specific
language or language family, and should not be carried over to
other languages or language families.
From Wikipedia:
http://en.wikipedia.org/wiki/Content_word 090822
Redirected from Content word.
Lexical items are single words or words that are
grouped in a language's lexicon. Examples are:
Single words [or lexemes]: <cat>,
Grouped words: <traffic light>, <take care of>,
<by-the-way>, and <don't count your chickens
before they hatch>. [UKT ¶ ]
Lexical items are those which can be generally understood to
convey a single meaning, much as a lexeme, but are not
limited to single words. Lexical items are like semes
in that they are "natural units" translating between
languages, or in learning a new language. In this last sense,
it is sometimes said that language consists of
grammaticalized lexis, and not lexicalized grammar.
UKT: Seme, the smallest unit of meaning recognized
in Semantics, refers to a single characteristic of a sememe.
These characteristics are defined according to the differences
between sememes. The term was introduced by Eric Buyssens
in the 1930s and developed by Bernard Pottier in the 1960s.
It is the result produced when determining the minimal elements
of meaning, which enables one to describe words
multilingually. Such elements provide a bridge to component
analysis and the initial work of ontologies. --
From Wikipedia:
http://en.wikipedia.org/wiki/Seme 090826
The idea of Seme should be compared with
the Eastern idea of Sphoṭa (developed thousands
of years ago): the term sphoṭa is derived from
the Sanskrit root sphuṭ, which means to
burst forth. In his Sanskrit-English Dictionary, V. S. Apte
defines sphoṭa as : (1) breaking forth,
bursting or disclosure; and (2) the idea which bursts out
or flashes on the mind when a sound is uttered. See
sphota2.htm
in this series.
The entire store of lexical items in a language is called its
lexis.
Lexical chunks
Lexical items composed of more than one word are also sometimes called
gambits, lexical phrases, lexical units, lexicalized stems
or speech formulae. The term polyword listemes is also sometimes
used. Common types of lexical chunks include
[1]:
• Words, e.g.,
<cat>, <tree>.
• Phrasal verbs, such as
<put off> or <get out>
• Polywords, e.g.,
<by the way>, <inside out>.
• Collocations, e.g.,
<motor vehicle>, <absolutely convinced>.
UKT: Within the area of corpus linguistics, collocation is
defined as a sequence of words or terms which coöccur more often
than would be expected by chance.
Collocation comprises the restrictions on how words can be used
together, for example which prepositions are used with particular verbs,
or which verbs and nouns are used together. Collocations are examples of
lexical units. Collocations should not be confused with idioms.
Collocation extraction is a task that extracts collocations
automatically from a corpus, using computational linguistics. -- Excerpt
from Wikipedia:
http://en.wikipedia.org/wiki/Collocation 090826
• Institutionalized utterances, e.g.,
<I'll get it>, <We'll see>, <That'll
do>, <If I were you>, <Would you like a cup of coffee?>
• Idioms, e.g.,
<break a leg>, <was one whale of a>,
<a bitter pill to swallow>.
• Sentence frames and heads, e.g.,
<That is not as...as you think>, <The
problem was>.
• Text frames, e.g.,
<In this paper we explore...; Firstly...; Secondly...;
Finally ...>.
An associated concept is that of noun-modifier semantic relations,
wherein certain word pairings have a standard interpretation.
For example, the phrase <cold virus> is generally understood to
refer to the virus causes a cold, rather than a virus that is cold.
UKT: End of Wikipedia article.
Contents of this page
From Wikipedia:
-
http://en.wikipedia.org/wiki/Function_word 090822
-
https://en.wikipedia.org/wiki/Function_word 151215
The distinction between function/structure
words and content/lexical words proposed
by C.C. Fries in 1952 has been highly
influential in the grammar used in L2 acquisition
and English Language Teaching.
[1] [UKT
¶]
Function words are
words that have
little
lexical
meaning or have
ambiguous meaning, but instead serve to express
grammatical
relationships with other words within a
sentence, or specify the attitude or mood of the speaker. They signal the
structural relationships that words have to one another and are the glue that
holds sentences together. Thus, they serve as important elements to the
structures of sentences.[2]
Words that are not function words are called
content words (or
open class words or lexical words or autosemantic words):
these include nouns,
verbs,
adjectives,
and most adverbs,
although some adverbs are function words (e.g., then and why).
Dictionaries define the specific meanings of content words, but can only
describe the general usages of function words. By contrast,
grammars
describe the use of function words in detail, but treat lexical words in general
terms only.
Function words might be
prepositions,
pronouns,
auxiliary verbs,
conjunctions,
grammatical articles or
particles, all of which belong to the group of
closed-class words.
Interjections are sometimes considered function words but they belong to the
group of
open-class words. Function words might or might not be
inflected
or might have
affixes.
Function words belong to the closed class of words in
grammar in
that it is very uncommon to have new function words created in the course of
speech, whereas in the open class of words (that is, nouns, verbs, adjectives,
or adverbs) new words may be added readily (such as
slang words,
technical terms, and adoptions and adaptations of foreign words). See
neologism.
Each function word either gives some grammatical information on other words
in a sentence or
clause, and cannot be isolated from other words, or it may indicate the
speaker's mental model as to what is being said.
Grammatical words, as a class, can have distinct
phonological properties from content words. Grammatical words sometimes do
not make full use of all the sounds in a language. For example, in some of the
Khoisan languages, most content words begin with
clicks, but very few function words do.[3]
In English, very few words other than function words begin with voiced th-"[ð]"[citation
needed] (see
Pronunciation of English th); English function words may have less than
three letters 'I', 'an', 'in' while non-function words usually have three or or
more 'eye', 'Ann', 'inn' (see
three letter rule).
The following is a list of the kind of words considered to be function words:
-
articles — the and a. In some inflected languages, the
articles may take on the case of the
declension of the following noun.
- pronouns
— inflected in English, as he — him, she — her,
etc.
-
adpositions —
uninflected in English
-
conjunctions — uninflected in English
-
auxiliary verbs — forming part of the
conjugation (pattern of the
tenses of main verbs), always inflected
-
interjections — sometimes called "filled pauses", uninflected
-
particles — convey the attitude of the speaker and are uninflected, as
if, then, well, however, thus, etc.
-
expletives — take the place of sentences, among other functions.
-
pro-sentences — yes, okay, etc.
-----
Function words (or grammatical words) are
words that have little lexical meaning or have ambiguous
meaning, but instead serve to express grammatical
relationships with other words within a sentence, or
specify the attitude or mood of the speaker. [UKT ¶ ]
Words that are not function words are called content words
(or lexical words): these include nouns, verbs, adjectives,
and most adverbs, although some adverbs are function words
(e.g., <then> and <why>). Dictionaries define
the specific meanings of content words, but can only describe
the general usages of function words. By contrast, grammars
describe the use of function words in detail, but treat
lexical words in general terms only.
Function words might be prepositions, pronouns, auxiliary
verbs, conjunctions, grammatical articles or particles,
all of which belong to the group of closed-class words.
Interjections are sometimes considered function words
but they belong to the group of open-class words.
Function words might or might not be inflected or might
have affixes.
Function words belong to the closed class of words in grammar in
that it is very uncommon to have new function words created in the course of
speech, whereas in the open class of words (that is, nouns, verbs, adjectives,
or adverbs) new words may be added readily (such as slang words,
technical terms, and adoptions and adaptations of foreign words). See
neologism.
Each function word either gives some grammatical information on
other words in a sentence or clause, and cannot be isolated from
other words, or it may indicate the speaker's mental model as to
what is being said.
Grammatical words, as a class, can have distinct phonological
properties from content words. Grammatical words sometimes
do not make full use of all the sounds in a language. For example,
in some of the Khoisan languages, most content words begin with
clicks, but very few function words do.
[1]
In English, only function words begin with voiced th-
[ð] (see
Pronunciation of English th).
The following is a list of the kind of words considered to be
function words:
• articles
— the and a. In highly inflected languages,
the articles may take on the case of the
declension of the following noun.
• pronouns
— inflected in English, as he — him,
she — her, etc.
• adpositions
— uninflected in English
• conjunctions
— uninflected in English
• auxiliary verbs
— forming part of the conjugation (pattern of
the tenses of main verbs), always inflected
• interjections
— sometimes called "filled pauses", uninflected
• particles
— convey the attitude of the speaker and are uninflected, as
if, then, well, however, thus, etc.
• expletives
— take the place of sentences, among other functions.
• pro-sentences
— yes, okay, etc.
UKT: End of Wikipedia article.
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Concordance 090901
 A concordance is an alphabetical list of the principal words used in a
book or body of work, with their immediate contexts. Because of the time and
difficulty and expense involved in creating a concordance in the pre-computer
era, only works of special importance, such as the Bible, Qur'an or the works of
Shakespeare, had concordances prepared for them.
A concordance is an alphabetical list of the principal words used in a
book or body of work, with their immediate contexts. Because of the time and
difficulty and expense involved in creating a concordance in the pre-computer
era, only works of special importance, such as the Bible, Qur'an or the works of
Shakespeare, had concordances prepared for them.
Even with the use of computers, producing a concordance (whether on paper or
in a computer) may require much manual work, because they often include
additional material, including commentary on, or definitions of, the indexed
words, and topical cross-indexing that is not yet possible with
computer-generated and computerized concordances.
However, when the text of a work is on a computer, a search function can
carry out the basic task of a concordance, and is in some respects
even more versatile than one on paper.
A bilingual concordance is a concordance based on
aligned parallel text.
A topical concordance is a list of subjects that a book (usually The
Bible) covers, with the immediate context of the coverage of those subjects.
Unlike a traditional concordance, the indexed word does not have to appear in
the verse. The most well known topical concordance is
Nave's Topical Bible.
The first concordance, to the Vulgate Bible, was compiled by Hugh of St Cher
(d.1262), who employed 500 monks to assist him. In 1448 Rabbi Mordecai Nathan
completed a concordance to the Hebrew Bible. It took him ten years. 1599 saw a
concordance to the Greek New Testament published by Henry Stephens and the
Septuagint was done a couple of years later by Conrad Kircher in 1602. The first
concordance to the English bible was published in 1550 by Mr Marbeck, according
to Cruden it did not employ the verse numbers devised by Robert Stephens in 1545
but "the pretty large concordance" of Mr Cotton did. Then followed the notorious
Cruden's Concordance and
Strong's Concordance.
Use in Linguistics
Concordances are frequently used in linguistics, when studying a text. For
example:
• comparing different usages of the same word
• analysing keywords
• analysing word frequencies
• finding and analysing phrases and idioms
• finding translations of subsentential elements, e.g.
terminology, in
bitexts and translation memories
• creating indexes and word lists (also useful for publishing)
Inverting a concordance
A famous use of a concordance involved the
reconstruction of the text of some of the
Dead Sea Scrolls from a concordance.
Access to some of the scrolls was governed
by a "secrecy rule" that allowed
only the original International Team or their
designates to view the original materials.
After the death of Roland de Vaux in 1971, his
successors repeatedly refused to even allow
the publication of photographs to other
scholars. This restriction was circumvented
by Martin Abegg in 1991, who used a computer
to "invert" a concordance of the
missing documents made in the 1950s which had
come into the hands of scholars outside of the
International Team, to obtain an approximate
reconstruction of the original text of 17 of
the documents.
[1]
[2]
This was soon followed by the release of the
original text of the scrolls.
UKT: End of Wikipedia article.
Contents of this page
UKT 151215: Orthography
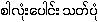 {sa-loän:paung: þût-poän} -- MEDict107
{sa-loän:paung: þût-poän} -- MEDict107
Contd. from Wikipedia:
http://en.wikipedia.org/wiki/Word 090814
[UKT: I have rewritten this paragraph.]
The
languages we are dealing with -- Burmese, English,
Pali and Sanskrit -- have long literary traditions,
and there is interrelation between orthography and
the question of what is considered a single
word. Though word separators (typically
white spaces) are common in modern orthography of
these languages especially Eng-Latin, these
are modern developments (see also
history of writing). In older texts many
phrases in Bur-Myan and Pali-Myan suffer from a dearth of
white spaces separating words. Though this is not a problem for
native Bur-Myan speakers speaking or writing Burmese,
it is a very genuine problem for new comers for speaking
and writing Pali-Myan because it is a dead language.
[UKT: I have rewritten this paragraph.]
In English-Latin orthography,
words may contain spaces if they are compounds or proper nouns
such as <ice cream> or <air raid shelter>. The problem
becomes real when we try to write (transcribe) English in Myanmar
script. The same is true for writing Burmese in Latin (as in Romabama).
[UKT: I have rewritten this paragraph.]
In correlating Pali-Latin
(common referred to as "Pali in English") and Pali-Myan the problem
becomes unnecessarily complex because the [c] in Pali-Latin is the
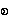 {sa.} in Pali-Myan and च [c] in Skt-Dev. Added to this problem, is the problem of
allophones in the English. Perhaps the greatest problem is to
point out that Burmese and English have the so-called thibilant
pronunciation (/θ/) which is unfamiliar to the speakers
of the majority of European speakers such as the the French and
Germans, and Hindi and Sanskrit speakers. Their languages use
the sibilant pronunciation (/s/) in place of the thibilant.
{sa.} in Pali-Myan and च [c] in Skt-Dev. Added to this problem, is the problem of
allophones in the English. Perhaps the greatest problem is to
point out that Burmese and English have the so-called thibilant
pronunciation (/θ/) which is unfamiliar to the speakers
of the majority of European speakers such as the the French and
Germans, and Hindi and Sanskrit speakers. Their languages use
the sibilant pronunciation (/s/) in place of the thibilant.
Vietnamese orthography, although using the Latin alphabet,
delimits monosyllabic morphemes, not words. Conversely,
synthetic languages often combine many lexical morphemes
into single words, making it difficult to boil them down to
the traditional sense of words found more easily in
analytic languages [UKT: see isolating language in my notes] ;
this is especially difficult for polysynthetic languages,
such as Inuktitut and Ubykh, where entire sentences may consist
of single such words.
Logographic scripts use single signs
(characters) to express a word. Most de facto existing
scripts are however partly logographic, and combine logographic
with phonetic signs. The most widespread logographic script in
modern use is the Chinese script. While the Chinese script has
some true logographs, the largest class of characters used in modern
Chinese (some 90%) are so-called pictophonetic compounds
(形声字, Xíngshēngzì).
[4]
Characters of this sort are composed of two parts: a pictograph,
which suggests the general meaning of the character, and
a phonetic part, which is derived from a character pronounced
in the same way as the word the new character represents.
In this sense, the character for most Chinese words consists
of a determiner and a syllabogram, similar to the approach used
by cuneiform script and Egyptian hieroglyphs.
There is a tendency informed by orthography to identify a single
Chinese character as corresponding to a single word in
the Chinese language, parallel to the tendency to identify
the letters between two space marks as a single word in
the English language. In both cases, this leads to the identification of
compound members as individual words, while e.g. in
German orthography, compound members are not separated
by space marks, and the tendency is thus to identify the entire compound
as a single word. Compare e.g. English capital city
with German Hauptstadt and Chinese 首都
(lit. chief metropolis): all three are equivalent compounds,
in the English case consisting of "two words"
separated by a space mark, in the German case written
as a "single word" without space mark, and
in the Chinese case consisting of two logographic characters.
Contents of this page
Contd. from Wikipedia:
http://en.wikipedia.org/wiki/Word 090814
See also
https://en.wikipedia.org/wiki/Suffix 151215
In synthetic languages [inflectional languages],
a single word stem
(for example, <love>) may have a number of different
forms (for example, <loves>, <loving>, and
<loved>). However, these are not usually considered to be
different words, but different forms of the same word. In
these languages, words may be considered to be constructed
from a number of morphemes. In Indo-European languages
in particular, the morphemes distinguished are
• the root
• optional suffixes
• a desinence or suffix used as inflection
desinence (plural desinences)
- from:
http://en.wiktionary.org/wiki/desinence 090814
- A suffix used as an inflection
- from:
http://dictionary.reference.com/browse/desinence 151215
- n. ¹. a termination or ending, as the final line of a verse. ².
grammar , a termination, ending, or suffix of a word.
Thus, the Proto-Indo-European
*wr̥dhom would be
analysed as consisting of
1 • *wr̥-, the
zero grade of the root *wer-
2 • a root-extension *-dh-
(diachronically a suffix),
resulting in a complex root *wr̥dh-
3 • The thematic suffix
*-o-
4 • the neuter gender nominative or accusative
singular desinence *-m.
Classes
Grammar classifies a language's lexicon into several groups
of words. The basic bipartite division possible for virtually
every natural language is that of nouns vs. verbs.
The oldest classification of a lexicon of a
language was probably that of Yāska
यास्कः
{yaaþ~ka.} (fl. 6th-5th centuries B.C.) who
defines four main categories of words :
See
lang.htm
(broken link on 151215)
or alternately see ¤ Word formation -
word-forma.htm (link chk 151215)
1. nāma
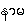 {na-ma.} - nouns or substantives - UHS-PMDict0515
{na-ma.} - nouns or substantives - UHS-PMDict0515
2. ākhyāta
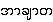 {a-hkya-ta.} - verbs - UHS-PMDict0153
{a-hkya-ta.} - verbs - UHS-PMDict0153
3. upasarga -
 {U.pa.tha-ra.}
- pre-verbs or prefixes - UHS-PMDict0233
{U.pa.tha-ra.}
- pre-verbs or prefixes - UHS-PMDict0233
4. nipāta
 {ni.pa-ta.} - particles, invariant words
(perhaps prepositions) - UHS-PMDict0529
{ni.pa-ta.} - particles, invariant words
(perhaps prepositions) - UHS-PMDict0529
UHS-BEPD0406, PMDict-486, PTS-360.
The classification into such classes is in the
tradition of Dionysius Thrax (fl. 100 B.C. -- AHTD),
who distinguished eight categories:
noun, verb, adjective, pronoun,
preposition, adverb, conjunction and interjection.
In Indian grammatical tradition, Pāṇini
{pa-Ni.ni.} introduced a similar fundamental classification
into a nominal «nāma»
{na-ma.}- suP
, and a verbal
«ākhyāta»
{a-hkya-ta.}- tiN class, based on the set of desinences taken by the word.
UKT: End of Wikipedia article.
Contents of this page
UKT 090912, 151207:
There are three linguistic terms most confusing
for a Bur-Myan native speaker learning ESL:
• lexeme
• morpheme, and
• phoneme
The IPA transcriptions and Bur-Myan equivalents
below are mine. I have used the "narrow
transcription" with /.../ instead of [...]
to avoid confusion. It should be noted that the
idea of a double consonant <tt> is
unacceptable since <batter> is a
disyllabic word and written as
/ˡbæt|.əʳ/.
A more illustrative word is
<success> /sək'ses/ ≅
 {hsaak~hsakS}
{hsaak~hsakS}
See my discussion Pronouncing the double C
dated 080309, in:
http://www.antimoon.com/forum/t9999.htm
151207
First, the definitions of these and their
"children" from AHTD:
• lex·eme n. 1. The
fundamental unit of the lexicon of a
language. <Find>, <found>, and
<finding> are members of the English
lexeme <find>. [ lex(icon) -eme ]
• mor·pheme n. Linguistics
1. A meaningful linguistic unit
consisting of a word, such as <man>,
or a word element, such as <-ed> in
<walked>, that cannot be divided into
smaller meaningful parts. [French
morphème blend of Greek
morphē form French phonème
phoneme; See phoneme ]
UKT note:

¤ al·lo·morph ² n.
1. Any of the variant
forms of a morpheme. For example, the phonetic
/s/ of <cats> /kæts/, /z/ of
<dogs> /dɒgz (US) dɔːgz/,
and /ɪz/ of <horses>
/hɔːsɪz/ and the /en/ of
<oxen> /ˡɒk.sən
(US) ˡɒːk-/ are allomorphs
of the English plural morpheme. -- AHTD
• pho·neme n. Linguistics 1.
The smallest phonetic unit in a language that is
capable of conveying a distinction in meaning,
as the <m> of <mat> and the <b>
of <bat> in English. [French phonème from
Greek phōnēma phōnēmat
-- utterance, sound produced from phōnein to
produce a sound from phōnē sound,
voice; See bh ā- ² in Indo-European
Roots.]
¤ al·lo·phone n. Linguistics
1. A predictable phonetic variant of
a phoneme. For example, the aspirated
/tʰ/ of <top> /tʰɒp (US)
tʰɑːp/, the unaspirated /t/ of
<stop> /stɒp (US) stɑːp/,
and the <tt> [?] (pronounced d ) of
<batter> /ˡbæt|.əʳ/ are
allophones of the English phoneme /t/. - AHTD
Now, we will take up, summarily, Lexeme, Morpheme, and Phoneme, one by one.
The following is an excerpt from Wikipedia:
http://en.wikipedia.org/wiki/Lexeme 090730
A lexeme is an abstract unit of morphological analysis in
linguistics, that roughly corresponds to a set of forms taken
by a single word. For example, in the English language,
<run>, <runs>, <ran> and <running>
are forms of the same lexeme, conventionally written as
<RUN> . A related concept is the lemma (or
citation form), which is a particular form of
a lexeme that is chosen by convention to represent
a canonical form of a lexeme. Lemmas are used in
dictionaries as the headwords, and other forms of
a lexeme are often listed later in the entry if they are
not common conjugations of that word.
UKT: A more comprehensive note is included in another file,
Lexicology -
lexico.htm
If you have been looking for a quick check, go back lexeme-note-b
The following
by UKT based on Wikipedia:
http://en.wikipedia.org/wiki/Morpheme 090731
In
morpheme-based morphology, a morpheme is the smallest linguistic unit
that has semantic meaning.
Morphemes are composed of
• phonemes (the smallest linguistically distinctive sound units)
in spoken languages
• graphemes (the smallest units of written language) in written languages
The concept morpheme differs from the concept word,
as many morphemes cannot stand as words on their own. A morpheme is free
if it can stand alone, or bound if it is used exclusively alongside
a free morpheme. Its actual phonetic representation is the morph,
with the different morphs representing the same morpheme being grouped as its
allomorphs. e.g. the word "unbreakable" has three morphemes:
<un->, a bound morpheme - prefix
<break>, a free morpheme - [UKT: root]
<-able>, a bound morpheme - suffix
Both <un-> and <-able> are affixes: <un->
is the prefix, and <-able> the suffix.
UKT:
A more comprehensive note is included in another file,
Morphology - morpho.htm
If you have been looking for a quick check, go back morpheme-note-b
From Wikipedia:
http://en.wikipedia.org/wiki/Phoneme 090814
In human phonology, a phoneme (from the Greek:
φώνημα, phōnēma,
"a sound uttered") is the smallest
segmental unit of sound employed to form meaningful contrasts
between utterances.
UKT: A more comprehensive note is included in another file,
Phonology - phono.htm
If you have been looking for a quick check, go back phoneme-note-b
Contents of this page
clitic (linguistic)
From Wikipedia:
http://en.wikipedia.org/wiki/Clitic 090823
In linguistics, a clitic is a grammatically independent
and phonologically dependent morpheme.
[1]
It is pronounced like an affix, but works at the phrase level.
For example, the English possessive -'s is a clitic;
in the phrase the girl next door’s cat, -’s is
phonologically attached to the preceding word door while
grammatically combined with the phrase the girl next door,
the possessor.
UKT: At one time (when I was young: I'm now an old man
in my mid seventies), we (in Myanmar and India) tend
to use "the cat of my aunt" instead of
"my aunt's cat". We were made fun of for that
by the Westerners. Little do they know that fricative endings
are very difficult for Burmese speakers to pronounce.
-- UKT 090823
Clitics may belong to any grammatical category, though they are commonly
pronouns, determiners, or adpositions. Note that spelling is not a good guide
for identifying clitics, clitics may be spelled as independent words,
bound affixes or separated by special characters (e.g. apostrophe).
Classification
A clitic that precedes its host is called a proclitic.
• English: an apple
A clitic that follows its host is called an enclitic.
• Latin: Senatus
Populusque Romanus
lit. "Senate people-and Roman"
meaning: "The Roman Senate and people"
A mesoclitic appears between the
stem
of the host and other affixes.
• Portuguese: Ela levá-lo-ia.
lit. "She take-it-COND"
meaning: "She would take it."
A final type of clitic, the endoclitic, splits apart the root
and is inserted between the two pieces. Endoclitics defy the
Lexical Integrity Hypothesis
(Lexicalist Hypothesis) and so were long claimed to be impossible,
but evidence from the Udi language suggests that they do exist.
[2]
Endoclitics are also found in Pashto [language].
[3].
In addition to Udi and Pashto, endoclitics are reported to exist in Degema.
[4]
Properties of clitics
Some clitics can be understood as elements undergoing a historical process of
grammaticalization:
[5]
lexical item → clitic → affix
According to this model, an autonomous lexical item in a particular context
loses the properties of a fully independent word over time and acquires the
properties of a morphological affix. At any intermediate stage of this
evolutionary process, the element in question can be described as a
"clitic". As a result, this term ends up being applied
to a highly heterogeneous class of elements, presenting different
combinations of word-like and affix-like properties.
One characteristic shared by many clitics is a lack of
prosodic independence. A clitic attaches to an adjacent word,
known as its host. Orthographic conventions treat clitics
in different ways: Some are written as separate words, some
are written as one word with their hosts, and some are attached
to their hosts, but set off by punctuation (a hyphen or an
apostrophe, for example).
Although the term "clitic" can be used descriptively
to refer to any element whose grammatical status is somewhere
in between a typical word and a typical affix, linguists have proposed
various definitions of "clitic" as a technical
term. One common approach is to treat clitics as words that are prosodically
deficient: they cannot appear without a host, and they can only form an
accentual unit in combination with their host. The term
"postlexical clitic" is used for this narrower sense of the term.
Given this basic definition, further criteria are needed to establish a
dividing line between postlexical clitics and morphological affixes, since both
are characterized by a lack of prosodic autonomy. There is no natural, clear-cut
boundary between the two categories (since from a historical point of view, a
given form can move gradually from one to the other by morphologization).
However, by identifying clusters of observable properties that are associated
with core examples of clitics on the one hand, and core examples of affixes on
the other, one can pick out a battery of tests that provide an empirical
foundation for a clitic/affix distinction.
An affix syntactically and phonologically attaches to a base morpheme of a
limited part of speech, such as a verb, to form a new word. A clitic
syntactically functions above the word level, on the phrase or clause level, and
attaches only phonetically to the first, last, or only word in the phrase or
clause, whichever part of speech the word belongs to.
[6]
The results of applying these criteria sometimes reveal that elements that have
traditionally been called "clitics" actually have
the status of affixes (e.g. the Romance pronominal clitics discussed
below).
Clitics do not always appear next to the word or phrase that they are
associated with grammatically. They may be subject to global word order
constraints that act on the entire sentence. Many languages, for example, obey "
Wackernagel's
Law", which requires clitics to appear in "second position",
after the first syntactic phrase or the first stressed word in a clause:
• Czech: Kde se to stalo?
lit. "Where REFL that happened"
meaning: "Where did that happen?"
Several clitics appearing in the same position (sharing the same host)
form a "clitic cluster". The relative order of clitics
in a cluster is usually strictly fixed (just as affixes appear
in a strict order within a single word):
• Czech: Nechtěli jsme vám ho dát.
lit. "NOT-wanted 1PL
to-you it give"
meaning: "We didn't want to give it to you.")
• Polish: Ty widziałbyś go jutro.
lit. "you saw-COND-2sg
him tomorrow"
meaning: "You would see him tomorrow."
Clitics in English
• The abbreviated forms of be :
¤ ’m in I’m
¤ ’re in you’re
¤ ’s in she’s
• The abbreviated forms of auxiliary verbs:
¤ ’ll in they’ll
¤ ’ve in they’ve
English proclitics include:
• a ____ in a desk
• an ____ in an egg
• the ____ in the house
The contraction n’t as in couldn’t etc.
has been shown to have the properties of an
affix,
rather than a syntactically independent clitic.
[7]
In English, clitics must be unstressed, but not as a full word
cannot be unstressed.
• I have not done it yet.
• I’ve not done it yet.
• I haven’t done it yet.
• I’ven’t done it yet. (dialectal non-standard)
Stress also prevents cliticization as follows:
• I don’t know who she is. (*I don't know who she’s.)
• Have you done it? —Yes, I have. (*Yes, I’ve.)
• He’s not a fool. —He is a fool! (*He’s a fool!)
cf. He’s not a genius, either.
Clitics in Romance languages
In the
Romance languages, the articles and
direct and indirect object
personal pronoun forms are clitics. [UKT ¶ ]
In
Spanish, for example:
• las aguas
[laˈsaɣwas] ("the waters")
• lo atamos
[loaˈtamos] ("it tied-1PL" = "we tied
it")
• dámelo
[ˈdamelo] ("give me it")
According to most criteria, in fact, the pronominal clitics
in most of the Romance languages have already developed into affixes.
[8]
There is still some debate as to whether or not this change
from clitic to affix has occurred with
French subject pronouns. Subject pronouns, especially,
are still considered clitics as they force a topicalized reading of a coindexed
XP.
[9]
Although mesoclisis is extremely formal in
Brazilian Portuguese and tends to be circumscribed in lesser formal
registers by avoiding synthetical future/conditional verb forms,
European Portuguese still allows clitic object pronouns to surface as
mesoclitics in colloquial situations:
[10]
• Ela levá-lo-ia ("She take-it-would" — "
She would take it").
• Eles dar-no-lo-ão ("They give-us-it-will"
— "They will give it to us").
Further examples
In the Indo-European languages, some clitics can be traced back to
Proto-Indo-European:
Example, *-kʷe
is the original form of
¤ Sanskrit
च,
[UKT: rendering this akshara to Myanmar:
Decimal - च --> Hexadecimal: U091A --> Devanagari
letter Ca = Burmese-Myanmar
{sa.}]
¤ Greek
τε, and
¤ Latin
-que.
• Latin:
-que and,
-ve or,
-ne
(
yes-no question)
• Greek:
τε and,
δέ but,
γάρ for (in a logical argument),
οὖν therefore
• Russian:
ли (yes-no question),
же (emphasis), то (emphasis),
не "not" (proclitic),
бы (subjunctive)
• Dutch: 't definite article of neuter nouns and third person
singular neuter pronoun, 'k first person pronoun, je second
person singular pronoun, ie third person masculin singular pronoun,
ze third person plural pronoun
• Plautdietsch: "Deit'a't vondoag?":
"Will he do it today?"
• Czech: special clitics: weak personal and reflexive pronouns
(mu, "him"), certain auxiliary verbs
(by, "would"), and various short particles and adverbs
(tu, "here"; ale, "though").
"Nepodařilo by se mi mu to dát"
"I would not succeed in giving it to him". In addition
there are various simple clitics including short prepositions.
• Swedish: Definite articles are attached to the end of the nouns
(enclitic), like in the other Scandinavian languages.
Examples: "en pojke" "a boy",
"pojken" "the boy", "pojkarna
" "the boys"; "en flicka"
"a girl", "flickan" "the girl";
"ett barn" "a child", "barnet"
"the child"
• In Old Norse,
the definite article is expressed in the enclitics "-inn"
(masc.) eg. alfrinn "the elf" dvergrinn
"the dwarf" and haukrinn "the hawk",
"-in" (fem.) gjǫfin and "-it" (neut.)
treit "the tree".
Examples of some non-Indo-European languages are shown below:
• Hungarian: the marker of indirect questions is -e: Nem tudja
még, jön-e. "He doesn't know yet if he'll come."
Is
("as well") and se ("not... either") also function as clitics:
although written separately, they are pronounced together with the preceding
word, without stress: Ő is jön. "He'll come too." Ő se jön.
"He won't come, either."
• Japanese: all
particles, such as the
genitive
postposition
の (no) and the
topic marker
は (wa).
• Korean: The copula
이다
(ida) and the adjectival
하다
(hada), as well as some nominal and verbal particles (e.g.
는,
neun).[11]
However, alternative analysis suggests that the nominal particles do not
function as clitics, but as phrasal affixes.
[12]
• Luganda: -nga attached to a verb to form the
progressive;
-wo 'in' (also attached to a verb)
UKT: End of Wikipedia article.
Go back clitic-note-b
Contents of this page
Excerpt from Wikipedia:
http://en.wikipedia.org/wiki/Compound 090820
In linguistics, a compound is a lexeme (less precisely, a word) that
consists of more than one stem. [UKT ¶ ]
Compounding or composition is the word-formation that creates
compound lexemes (the other word-formation process being
derivation). Compounding or Word-compounding refers to the
faculty and device of language to form new words by combining or putting
together old words. In other words, compound, compounding or
word-compounding occurs when a person attaches two or more words together to
make them one word. The meanings of the words interrelate in such a way that a
new meaning comes out which is very different from the meanings of the words in
isolation.
Colloquial or everyday examples of compounds are <fireman> and <hardware>.
Someone who believes that nothing he does has a good result might be called a
<never-go-well> person. We combine the words <never>, <go>
and <well> to form an adjectival compound. This process
of birth and death of words is going on all the time.
UKT: A more comprehensive note is included in another file,
Word formation -
word-forma.htm
Go back compound-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Cruden_concordance 090901
A Complete Concordance to the Holy Scriptures,
generally known as Cruden's Concordance, is a
concordance of the
King James Bible (KJV) that was single handedly created by
Alexander Cruden (1699-1770). It was first published
in 1737 and has not been
out of print since then.
Cruden's concordance was first published in 1737, one of
the first copies being personally presented to
Queen Caroline on November 3, 1737. Cruden began work
on his concordance in 1735 whilst a bookseller in London.
Cruden worked alone from 7am to 1am every day and completed
the bulk of the work in less than a year. The proofreading
and layout took a little longer. His brain was occupied with
nothing else, so much so that he failed to notice the
diminishing stock in his bookshop and the consequent lack of
custom. "Was there ever, before or since the year
1737", writes his biographer Edith Olivier, "
another enthusiast for whom it was no drudgery, but a sustained
passion of delight, to creep conscientiously word by word
through every chapter of the Bible, and that not once only,
but again and again?".
UKT: End of Wikipedia article.
Go back concorda-cruden-note-b
Contents of this page
devoicing : medial formation
From Wikipedia:
http://en.wikipedia.org/wiki/Devoicing 090816
Devoicing is a phonological process whereby a consonant that is normally
voiced becomes devoiced (i.e.
unvoiced)
due to the influence of a phonological element in its phonological environment.
UKT: We find this process as a part of "medial formation" in
Burmese-Myanmar:
voiced --> devoiced (usually described as "voiceless")
(See Ladefoged
http://www.phonetics.ucla.edu/vowels/chapter12/burmese.html 090815 )
¤  {ma.} -->
{ma.} -->
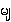 {mya.} /
{mya.} /
 {mwa.} /
{mwa.} /
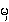 {mha.}
- (
{ma.} is voiced: it is devoiced as medials shown on the right)
{mha.}
- (
{ma.} is voiced: it is devoiced as medials shown on the right)
¤ 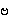 {ba.} -->
{ba.} -->
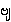 {bya.} /
{bya.} /
 {bwa.}
- (
{ba.} is voiced: it is devoiced as medials shown on the right)
{bwa.}
- (
{ba.} is voiced: it is devoiced as medials shown on the right)
¤ 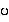 {pa.} -->
{pa.} -->
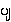 {pya.} /
{pya.} /
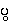 {pwa.}
- (
{pa.} is voiceless: medial formation has not effect)
{pwa.}
- (
{pa.} is voiceless: medial formation has not effect)
Medial formation also results in aspiration, and consonants that
already are "aspirated" do not conjoin with
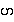 {ha.} /h/ to form
{ha.} /h/ to form
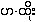 {ha.hto:}.
{ha.hto:}.
This process is different from the concept of a consonant being
voiceless.
The difference is that voiceless consonants are always voiceless, whereas
a devoiced consonant is one that is usually voiced, but which becomes
unvoiced under very specific circumstances.
English
In English, sonorants (/l r w j/) following aspirated fortis plosives (that is,
/p t k/ in the onsets of stressed syllables unless preceded by
/s/) are devoiced such as in <please>, <crack>, <twin>, and <pewter>.
Ref. Roach, Peter (2004), "British English: Received
Pronunciation", Journal of the International Phonetic Association 34 (2):
239-245
http://en.wikipedia.org/wiki/Received_Pronunciation 090816
UKT: The sonorants referred to above are approximants. They are
conjunct formers {ya.} {ra.} {la.} {wa.} in Burmese-Myanmar which form
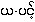 {ya.ping.},
{ya.ping.},
 {ra.ric},
{ra.ric},
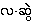 {la.hswè:},
{la.hswè:},
 {wa.hswè:} medials. There is a fifth medial former
{wa.hswè:} medials. There is a fifth medial former
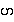 {ha.} which forms the medial
{ha.hto:}. See: Peter Ladefoged Vowels and Consonants
http://www.phonetics.ucla.edu/vowels/chapter12/burmese.html 090815
{ha.} which forms the medial
{ha.hto:}. See: Peter Ladefoged Vowels and Consonants
http://www.phonetics.ucla.edu/vowels/chapter12/burmese.html 090815
¤ 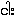 {nga:} 'fish' -->
{nga:} 'fish' -->
 {ngha:} 'to borrow'
{ngha:} 'to borrow'
¤ {Ña} --> {Ñha}
¤ {na} --> {nha}
¤ {ma.} --> {mha.}
Examples in other languages
Another type of devoicing is
final obstruent devoicing a systematic phonological process occurring
in languages such as German, Dutch, Polish, and Russian, among others.
In these languages, voiced
obstruents
in the syllable coda or at the end of a word become voiceless.
Go back devoicing-note-b
Contents of this page
Excerpt from Wikipedia:
http://en.wikipedia.org/wiki/Key_Word_in_Context 090901
KWIC is an acronym for Key Word In Context, the most
common format for concordance lines. The term KWIC was first coined by Hans
Peter Luhn.
[1]
A KWIC index is formed by sorting and aligning the words within an
article title to allow each word (except the stop words) in titles to be
searchable alphabetically in the index. It was a useful indexing method for
technical manuals before computerized full text search became common. --
Go back KWIC-note-b
Contents of this page
lemma (Linguistics) or headword
UKT: First you should know what 'lexicon' is:
lexicon n. pl. lexicons or lexica Abbr.
lex. 1. A dictionary. 2. A stock of terms used in a particular
profession, subject, or style; a vocabulary: the lexicon of surrealist art. 3.
Linguistics The morphemes of a language considered as a group. [Medieval
Latin from Greek lexikon (biblion) word(book), from neuter of lexikos of words
from lexis word from legein to speak; See leg- in Indo-European Roots.] -- AHTD
From Wikipedia:
http://en.wikipedia.org/wiki/Headword 090822
A headword, head word, lemma, or sometimes catchword
is the word under which a set of related dictionary or encyclopaedia entries
appears. The headword is used to locate the entry, and dictates its alphabetical
position. Depending on the size and nature of the dictionary or encyclopedia,
the entry may include alternative meanings of the word, its etymology and
pronunciation, compound words or phrases that contain the headword, and
encyclopedic information about the concepts represented by the word.
For example, the headword <bread> may contain the following (simplified)
definitions:
Bread
(noun)
¤ A common food made from the combination of flour, water and yeast
¤ Money (slang)
(verb)
¤ To coat in breadcrumbs
— to know which side your bread is buttered to know how to act in
your own best interests.
The Academic Dictionary of Lithuanian contains around 500,000 headwords.
The Oxford English Dictionary has around 300,000 headwords,
while Merriam-Webster's Third New International Dictionary has
about 470,000. Both of these values are as claimed by the dictionary makers,
and may not be using exactly the same definition of a headword.
Also, the Oxford English Dictionary covers each word much more exhaustively
than the Third New International.
The term 'lemma' comes from the practice in Greco-Roman antiquity of using
the word to refer to the headwords of marginal glosses in
scholia; for
this reason, the Ancient Greek plural form is sometimes used, namely lemmata
(Greek λῆμμα, pl. λήμματα).
UKT: End of Wikipedia:
http://en.wikipedia.org/wiki/Headword 090822
From Wikipedia:
http://en.wikipedia.org/wiki/Lemma 090725
In linguistics a lemma (plural lemmas or lemmata)
has two distinct interpretations:
1. morphology / lexicography: the canonical form or citation form
of a set of forms (headword); e.g., in English, <run>, <runs>,
<ran> and <running> are forms of the same lexeme, with <run>
as the lemma.
2. psycholinguistics: Abstract conceptual form that has been mentally
selected for utterance in the early stages of speech production, but before
any sounds are attached to it.
A lemma in morphology is the canonical form of a lexeme.
Lexeme, in this context, refers to the set of all
the forms that have the same meaning, and lemma
refers to the particular form that is chosen by convention
to represent the lexeme. In lexicography, this unit is usually
also the citation form or headword by which it is
indexed. Lemmas have special significance in highly
inflected languages such as Czech. The process of
determining the lemma for a given word is called
lemmatisation.
UKT:
In linguistics, lemmatisation is the process of grouping together
the different inflected forms of a word so they can be analysed
as a single item. -- Wikipedia:
http://en.wikipedia.org/wiki/Lemmatisation 090731
UKT: A more comprehensive note is included in another
file, Lexicology -
lexico.htm
Go back lemma-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Lexis 090831
In linguistics, lexis (from the Greek:
λέξις "word")
describes the storage of language in our mental lexicon
as prefabricated patterns (lexical units) that can be
recalled and sorted into meaningful speech and writing.
Recent research in corpus linguistics suggests that
the long-held dichotomy between grammar and vocabulary
does not exist. Lexis as a concept differs from the
traditional paradigm of grammar in that it defines
probable language use, not possible language usage.
This notion contrasts starkly with the Chomskian proposition
of a “Universal Grammar” as the prime mover for language;
grammar still plays an integral role in lexis, of course,
but it is the result of accumulated lexis, not its
generator.
Lexicon
In short, the lexicon is
• Formulaic: it relies on partially-fixed expressions and
highly probable word combinations
• Idiomatic: it follows conventions and patterns for usage
• Metaphoric: concepts such as time and money, business
and sex, systems and water all share a large portion of
the same vocabulary
• Grammatical: it uses rules based on sampling of the Lexicon
• Register-specific: it uses the same word differently
and/or less frequently in different contexts
A major area of study psycholinguistics and neurolinguistics
involves the question of how words are retrieved from the
mental lexicon in online language processing and production.
For example, the
cohort
model seeks to describe lexical retrieval in terms of
segment-by-segment activation of competing lexical entries.
[1]
[2]
Formulaic Language
In recent years, the compilation of language databases using real samples
from speech and writing has enabled researchers to take a fresh look at the
composition of languages. Among other things, statistical research methods offer
reliable insight into the ways in which words interact. The most interesting
findings have taken place in the dichotomy between language use (how
language is used) and language usage (how language could be used).
Language use shows which occurrences of words and their partners
are most probable. The major finding of this research is that language users
rely to a very high extent on ready-made language “lexical chunks”, which
can be easily combined to form sentences. This eliminates the need for the
speaker to analyze each sentence grammatically, yet deals with a situation
effectively. Typical examples include “I see what you mean” or “Could you
please hand me the …” or “Recent research shows that…”
Language usage, on the other hand, is what takes place when the
ready-made chunks do not fulfill the speaker’s immediate needs; in other
words, a new sentence is about to be formed and must be analyzed for
correctness. Grammar rules have been internalized by native speakers,
allowing them to determine the viability of new sentences. Language usage
might be defined as a fall-back position when all other options have been
exhausted.
Context and Co-Text
When analyzing the structure of language statistically, a useful
place to start is with high frequency context words, or so-called
Key Words in Context
( KWICs). After millions of samples of spoken and written
language have been stored in a database, these KWICs can be
sorted and analyzed for their co-text, or words which commonly
co-occur with them. Valuable principles with which KWICs can
be analyzed include:
• Collocation: words and their co-occurrences (examples
include “fulfill needs” and “fall-back position”)
• Semantic prosody: the connotation words carry (“pay attention”
can be neutral or remonstrative, as when a teacher says
to a pupil: “Pay attention!” (or else)
• Colligation: the grammar words use (while “I hope that
suits you” sounds natural, “I hope that you are suited
by that” does not).
• Register: the text style a word is used in (“President
vows to support allies” is most likely found in
news headlines, whereas “vows” in speech most likely refer
to “marriages”; in speech, the verb “vow” is most likely
used as “promise”).
(partially adapted from Lewis, 1997)
Once data has been collected, it can be sorted to determine
the probability of co-occurrences. One common and well-known
way is with a concordance: the KWIC is centered and shown with
dozens of examples of it in use, as with the example
for “possibility” below.
UKT: More in Wikipedia article.
Go back
lexis-note-b
Contents of this page
Excerpt from Wikipedia:
http://en.wikipedia.org/wiki/Pāṇini 090814
Pāṇini (पाणिनि ;
a patronymic meaning "descendant of
Paṇi"),
{pa-Ni.ni.} was an Ancient Indian Sanskrit
grammarian linguist from
Pushkalavati, Gandhara (fl. 4th century BCE
[1]
[2]).
He is known for his Sanskrit grammar,
particularly for his formulation of the
3,959 rules
[2] of
Sanskrit morphology in the grammar known
as Ashtadhyayi
( अष्टाध्यायी
Aṣṭādhyāyī,
meaning "eight chapters"), the
foundational text of the grammatical branch
of the
Vedanga, the auxiliary scholarly disciplines
of Vedic religion.
UKT 151204: There is considerable
difference between the Old Vedic religion
and the Later Brahmin-Poannar religion as
can be attested from two facts.
1. Gautama Buddha, an astute observer of
people's beliefs of his day who had learned
the various religious practices under
rishis teachers, Alara Kalama and
Uddaka Ramaputta respectively, prior to his
enlightenment, holds in high regard the old
rishis of the Vedas, but has little regard
for the new ones, who has altered
the old beliefs to suit their own imported
male gods.
2. The most important Vedic gods and goddess
are the King of Heaven Indra, Protector of
domestic life Agni, and Giver of Peace and
Tranquility Soma (who is now represented by
intoxicants like alcohol and psychedelic
drugs), and not Mahabrahma, Vishnu and Shiva.
There are more hymns directed to Indra, Agni,
and Soma, than to Mahabrahma, Vishnu and Shiva.
See Wikipedia:
https://en.wikipedia.org/wiki/Rigvedic_deities
151204
The Ashtadhyayi is one of the earliest known
grammars of Sanskrit, although he refers to
previous texts like the Unadisutra,
Dhatupatha, and Ganapatha.
[2]
It is the earliest known work on
descriptive linguistics,
generative linguistics, and together with
the work of his immediate
predecessors (Nirukta,
Nighantu,
Pratishak) stands at the beginning of the
history of linguistics itself.
Pāṇini's comprehensive and scientific theory of grammar
is conventionally taken to mark the end of the period of Vedic Sanskrit,
by definition introducing Classical Sanskrit.
UKT: More in the original Wikipedia article. See a more detailed account on the
subject in one of the files of this series:
Language and thought - lang.htm
Go back pa2nni1ni1-note-b
Contents of this page
UKT: A portmanteau means a "suitcase" into which
you pack your clothes for use during your travel.
From Wikipedia:
http://en.wikipedia.org/wiki/Portmanteau 090822
A portmanteau (pronounced /pɔrtmænˈtoʊ/)
or portmanteau word is used broadly to mean a blend of two (or more) words,
[1]
[2]
[3]
and narrowly in linguistics fields to mean only a blend of two or more
function words.
[4]
[5]
[6]
[7]
Meaning
"Portmanteau word" is used to describe a
linguistic blend,
namely "a word formed by blending sounds from two or more distinct words
and combining their meanings."
[1]
Such a definition of "portmanteau word" overlaps
with the grammatical term contraction, and linguists
avoid using the former term in such cases. As an example:
the words <do + not> become the contraction
<don't>, a single word that represents the meaning
of the combined words.
Origin
The usage of the word "portmanteau" in this sense
first appeared in Lewis Carroll's book Through the Looking-Glass (1871),
[1]
in which Humpty Dumpty explains to Alice the coinage of
the unusual words in Jabberwocky.
[8] [UKT:
Jabberwocky is the caption of a no-sense poem
in which some words have no meaning and the reader
is at liberty to apply a meaning to it.]
• "‘Slithy’ means ‘lithe and slimy’... You see it's like a portmanteau —
there are two meanings packed up into one word"
• "‘Mimsy’ is ‘flimsy and miserable’ (there's another portmanteau ...
for you)".
Carroll uses the word again when discussing
lexical selection:
Humpty Dumpty's theory, of two meanings packed into one word like a
portmanteau, seems to me the right explanation for all. For instance,
take the two words "fuming" and "furious."
Make up your mind that you will say both words ... you will say
"frumious."
[8].
According to the The American Heritage Dictionary of the English Language,
the word portmanteau comes from French porter, to carry +
manteau, cloak (from Old French mantel, from Latin mantellum).
[9]
Examples
Many
neologisms are examples of blends, but many blends
have become part of the lexicon.
[8] [UKT: ¶ ]
¤ In Punch [Magazine] in 1896, the word <brunch>
(breakfast + lunch) was introduced as a "portmanteau word."
[10]
¤ In 1964, the newly independent African republic of Tanganyika and
Zanzibar chose the portmanteau word Tanzania as its name.
¤ A <spork> is an eating utensil that is a combination
of a spoon and fork.
¤ "Wikipedia" is an example of a portmanteau word
because it combines the word "wiki" with the word
"Encyclopedia."
¤ The name Motown derives from the portmanteau of <motor>
and <town>. It is also a nickname for the city of Detroit.
"Jeoportmanteau!" is a recurring category on the American television
quiz show Jeopardy!. The category's name is itself a portmanteau of
"Jeopardy" and "portmanteau". Responses in the category
are portmanteaus constructed by fitting two words together. For example,
the clue "Brett Favre or John Elway plus a knapsack" yielded
the response "What is a 'quarterbackpack'?"
[11]
"Blaxploitation" is a film genre/style, whose name derives from a portmanteau
of "black" and "exploitation," reflecting its main theme of social problems,
along with the stereotypical depiction of Black people in film.
Portmanteau words may be produced by joining together proper nouns with common
nouns, such as "gerrymandering," which refers to the scheme of
Massachusetts Governor Elbridge Gerry for politically contrived redistricting:
one of the districts created resembled a salamander
[ {ré-poat-thing] in outline. Two proper names can also be used in creating a
portmanteau word in reference to the partnership between people, especially
in cases where both persons are well-known, or sometimes to produce
epithets such as "Billary" (referring to former United States president
Bill Clinton and [his wife] Hillary Rodham Clinton). In this example of recent
American political history, the purpose for blending is not so much
to combine the meanings of the source words but "to suggest
a resemblance of one named person to the other"; the effect
is often derogatory, as linguist Benjamin Zimmer notes.
[12]
In contrast, the public and even the media use portmanteaux to refer to their
favorite pairings as a way to "...giv[e] people an essence
of who they are within the same name."
[13]
This is particularly seen in cases of fictional and real-life
"supercouples." An early and well-known example,
"Bennifer", referred to film stars (and former couple)
Ben Affleck and Jennifer Lopez. Other examples include "Brangelina"
(Brad Pitt and Angelina Jolie) and "TomKat" (Tom Cruise and
Katie Holmes). In double-barreled names, the hyphen is almost pushing
one name away from the other.
[13]
Meshing says "I am you and you are me," notes one expert.
[13]
{ré-poat-thing] in outline. Two proper names can also be used in creating a
portmanteau word in reference to the partnership between people, especially
in cases where both persons are well-known, or sometimes to produce
epithets such as "Billary" (referring to former United States president
Bill Clinton and [his wife] Hillary Rodham Clinton). In this example of recent
American political history, the purpose for blending is not so much
to combine the meanings of the source words but "to suggest
a resemblance of one named person to the other"; the effect
is often derogatory, as linguist Benjamin Zimmer notes.
[12]
In contrast, the public and even the media use portmanteaux to refer to their
favorite pairings as a way to "...giv[e] people an essence
of who they are within the same name."
[13]
This is particularly seen in cases of fictional and real-life
"supercouples." An early and well-known example,
"Bennifer", referred to film stars (and former couple)
Ben Affleck and Jennifer Lopez. Other examples include "Brangelina"
(Brad Pitt and Angelina Jolie) and "TomKat" (Tom Cruise and
Katie Holmes). In double-barreled names, the hyphen is almost pushing
one name away from the other.
[13]
Meshing says "I am you and you are me," notes one expert.
[13]
Portmanteaux (or portmanteaus)
[2]
can also be created by attaching a prefix or suffix from one word to give that
association to other words. Subsequent to the Watergate scandal,
it became popular to attach the suffix "-gate" to other
words to describe contemporary scandals, e.g. "Filegate" for the
White House FBI files controversy, and Spygate, an incident involving the
2007 New England Patriots. Likewise, the suffix "-holism"
or "-holic," taken from the word "alcoholism"
or "alcoholic," can be added to a noun, creating a word that describes an
addiction to that noun. Chocoholic, for instance, means a person who is
"addicted" to chocolate. Also, the suffix " -athon"
is often appended to other words to connote a similarity to a marathon
(for example, telethon, phonathon and walkathon).
Portmanteau words can be used to describe bilingual speakers who use
words from both languages while speaking. For instance, people are said
to be speaking "Spanglish" when they are using both Spanish
and English words to voice a complete thought, and likewise
"Franglais" when mixing French and English language.
UKT: A portmanteau word you might have heard is "Burglish"
- a blend of Burmese and English. Please note that Romabama is not Burglish.
It is Burmese spoken language in extended-Latin alphabet.
It is also popular to use portmanteau words when breeding two breeds
of dogs together. (ie. A "labrador" [a breed of dog]
and a "poodle" [another breed of dog] mix can be called
a "labradoodle.")
UKT: More in the original Wikipedia article.
Go back portmanteau-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Pragmatics 090820
Pragmatics is a subfield of linguistics which studies the ways in which
context contributes to meaning. Pragmatics encompasses
speech act
theory, conversational
implicature,
talk in interaction and other approaches to language behavior in philosophy,
sociology, and linguistics.
[1]
It studies how the transmission of meaning depends not only on the linguistic
knowledge (e.g. grammar, lexicon etc.) of the speaker and listener,
but also on the context of the utterance, knowledge about the status
of those involved, the inferred intent of the speaker, and so on.
[2]
In this respect, pragmatics explains how language users are able to overcome
apparent ambiguity, since meaning relies on the manner, place, time etc.
of an utterance.
[1]
The ability to understand another speaker's intended meaning is called
pragmatic competence. An utterance describing pragmatic
function is described as
metapragmatic. Pragmatic awareness is regarded as one
of the most challenging aspects of language learning, and
comes only through experience.
Structural ambiguity
The sentence "You have a green light" is ambiguous. Without knowing the
context, the identity of the speaker, and their intent, it is not possible to
infer the meaning with confidence. For example:
• It could mean you are holding a green light bulb.
• Or that you have a green light to drive your car.
• Or it could be indicating that you can go ahead with the project.
Similarly, the sentence "Sherlock saw the man with binoculars"
could mean that Sherlock observed the man by using binoculars; or
it could mean that Sherlock observed a man who was holding binoculars.
[3] The
meaning of the sentence depends on an understanding of the context and the
speaker's intent. [UKT: ¶ ]
As defined in linguistics, a sentence is an abstract entity — a string of
words divorced from non-linguistic context — as opposed to an utterance, which
is a concrete example of a speech act in a specific context. The cat sat on
the mat is a sentence of English; if you say to your sister on Tuesday
afternoon: "The cat sat on the mat", this is an example of an utterance. Thus,
there is no such thing as a sentence with a single true meaning; it is
underspecified (which cat sat on which mat?) and potentially ambiguous. The
meaning of an utterance, on the other hand, is inferred based on linguistic
knowledge and knowledge of the non-linguistic context of the utterance (which
may or may not be sufficient to resolve ambiguity).
UKT: More in the Wikipedia article.
Go back pragma-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Prosody 090823
In linguistics, prosody (from Greek προσῳδία,
prosōidía) is the rhythm, stress, and intonation of connected speech
(as opposed to smaller elements like syllables or words).
Prosody may reflect various features of the speaker or the utterance:
the emotional state of a speaker; whether an utterance is a statement,
a question, or a command; whether the speaker is being ironic or sarcastic;
emphasis, contrast, and focus; or other elements of language that may
not be encoded by grammar or choice of vocabulary.
Acoustic attributes of prosody
Acoustically, the prosodics of oral languages involve variation in syllable
length, loudness, pitch, and the formant frequencies of speech sounds. In cued
speech and sign languages, prosody involves the rhythm, length, and tension
of gestures, along with mouthing and facial expressions. [UKT ¶ ]
Prosody is absent in writing, which is one reason e-mail, for example, may
notoriously be misunderstood. Orthographic conventions to mark or substitute for
prosody include punctuation (commas, exclamation marks, question marks,
scare quotes, and ellipses), typographic styling for
emphasis (italic, bold, and underlined text), and emoticons.
The details of a language's prosody depend upon its phonology.
For instance, in a language with phonemic vowel length, this must be
marked separately from prosodic syllable length. Similarly,
prosodic pitch must not obscure tone in a tone language if the result
is to be intelligible. Although tone languages such as Mandarin
have prosodic pitch variations in the course of a sentence, such
variations are long and smooth contours, on which the short
and sharp lexical tones are superimposed. [UKT ¶ ]
If pitch can be compared to ocean waves, the swells are the prosody,
and the wind-blown ripples in their surface are the lexical tones,
as with stress in English. The word dessert has greater stress on
the second syllable, compared to desert which has greater stress
on the first; but this distinction is not obscured when the entire word
is stressed by a child demanding "Give me dessert!" [UKT ¶ ]
UKT: Compare the IPA transcriptions of
¤ <dessert> /dɪˡzɜːt/
¤ <desert> /dɪ|ˡzɜːt/ (note inclusion of | )
Vowels in many languages are likewise pronounced differently (typically less
centrally) in a careful rhythm or when a word is emphasized,
but not so much as to overlap with the
formant
structure of a different vowel. Both
lexical and prosodic information are encoded in rhythm, loudness,
pitch, and vowel formants.
The prosodic domain
Prosodic features are
suprasegmental. They are not confined to any one
segment, but occur in some higher level of an utterance. These
prosodic units are the actual phonetic "spurts",
or chunks of speech. They need not correspond to grammatical
units such as phrases and clauses , though they may; and these
facts suggest insights into how the brain processes speech.
Prosodic units are marked by phonetic cues, such as a coherent
pitch
contour – or the gradual decline in pitch and
lengthening of vowels over the duration of the unit, until
the pitch and speed are reset to begin the next unit. Breathing,
both inhalation and exhalation, only seems to occur at these
boundaries where the prosody resets.
"Prosodic structure" is important in language contact and lexical borrowing.
Linguist Ghil'ad Zuckermann demonstrates that in "Israeli" (his term for Modern
Hebrew), the XiXéX verb-template is much more productive than the XaXáX
verb-template because in morphemic adaptations of non-Hebrew stems, the XiXéX
verb-template is more likely to retain — in all conjugations throughout the
tenses — the prosodic structure (e.g. the consonant clusters and the location of
the vowels) of the stem.
For example, the Israeli verb le-transfér "to transfer (people)" is
fitted into the XiXéX verb-template. In the past (3rd person, masculine,
singular) one says trinsfér, in the present metransfér and in the
future yetransfér. The consonant clusters of the stem transfer are
kept throughout. Now, let us try to fit the stem transfer into the XaXáX
verb-template, which in fact used to be the most productive one in Classical
Hebrew. The normal pattern can be seen in garám–gorém–yigróm "cause"
(past, present, future). So, yesterday, he *transfár "transferred (people)";
today, he *tronsfér. So far so good; the consonant clusters and the location of
the vowels of transfer are maintained, the specific characteristics of
the vowels (e.g. whether they are a or i) being less important.
However, the future form, *yitrnsfór, is impossible because among other things,
lacking a vowel between the r and the n, it violates the prosodic
structure of the stem transfer.
According to Zuckermann, this is exactly why the stem click "select by
pressing one of the buttons on the computer mouse" was fitted into the hiXXíX
verb-template, resulting in hiklík rather than in the XiXéX (*kilék) or
XaXáX (*kalák) verb-templates. The form hiklík is the only one preserving
the [kl] cluster.
One important conclusion is that prosodic considerations supersede semantic
ones. For example, although hiXXíX is historically the
causative
verb-template, it is employed — on purely phonological grounds — in the
intransitive hishvíts "show off" (from
Yiddish shvits) and in the ambitransitive (in fact, usually
intransitive) hiklík "click" (cf. English click).
[1]
Prosody and emotion
Emotional prosody is the expression of feelings using prosodic
elements of speech. It was recognized by Charles Darwin in
The Descent of Man as predating
the evolution of human language: " Even monkeys express
strong feelings in different tones – anger and impatience by low,
– fear and pain by high notes."
[2]
Native speakers listening to actors reading emotionally neutral text while
projecting emotions correctly recognized happiness 62% of the time, anger 95%,
surprise 91%, sadness 81%, and neutral tone 76%. When a database of this speech
was processed by computer, segmental features allowed better than 90%
recognition of happiness and anger, while suprasegmental prosodic features
allowed only 44%–49% recognition. The reverse was true for surprise, which was
recognized only 69% of the time by segmental features and 96% of the time by
suprasegmental prosody.
[3]
In typical conversation (no actor voice involved) the recognition of emotion may
be quite low, of the order of 50%, hampering the complex interrelationship
function of speech advocated by some authors.
[4]
Brain location of prosody
An
aprosodia is an acquired or developmental impairment in comprehending or
generating the emotion conveyed in spoken language.
Producing these nonverbal elements requires intact motor areas of the face,
mouth, tongue, and throat. This area is associated with Brodmann areas 44 and 45
(Broca's area) of the left frontal lobe. Damage to areas 44/45 produces
motor aprosodia, with the nonverbal elements of speech being disturbed
(facial expression, tone, rhythm of voice).
Understanding these nonverbal elements requires an intact and
properly functioning Brodmann area 22
(Wernicke's area) in the right hemisphere. Right-hemispheric area 22
aids in the interpretation of prosody, and damage causes sensory aprosodia,
with the patient unable to comprehend changes in voice and body language.
UKT: End of Wikipedia article.
Go back prosody-note-b
Contents of this page
root (linguistics)
From Wikipedia:
http://en.wikipedia.org/wiki/Root 090818
The root is the primary lexical unit of a word,
which carries the most significant aspects of semantic
content and cannot be reduced into smaller constituents. [UKT ¶ ]
 UKT
151215: The symbol for root is borrowed from mathematics: √
UKT
151215: The symbol for root is borrowed from mathematics: √
You can copy & paste from Doggie's Tale in my notes on most indx.htm
files such as -
lang-mean-indx.htm (link chk 151215)
Content words in nearly all languages contain, and may consist only of,
root morphemes. However, sometimes the term "root"
is also used to describe the word minus its
inflectional endings, but with its lexical endings in place.
For example, <chatters> has the inflectional root or
lemma <chatter>, but the lexical root <chat>. [UKT ¶ ]
Inflectional roots
are often called stems, and a root in the stricter sense may be
thought of as a monomorphemic stem.
The traditional definition allows roots to be either
free morphemes or
bound morphemes. Root morphemes are essential for
affixation and
compounds. However, in
polysynthetic languages with very high levels of inflectional morphology,
the term "root" is generally synonymous with "free morpheme".
Many such languages have a very restricted number of morphemes that can stand alone
as a word: Yup'ik [language], for instance, has no more than two thousand.
The root of a word is a unit of meaning (morpheme) and, as such, it is an
abstraction, though it can usually be represented in writing as a word would be.
For example, it can be said that the root of the English verb form <running>
is <run>, or the root of the Spanish superlative adjective amplísimo
is ampl-, since those words are clearly derived from the root forms by
simple suffixes that do not alter the roots in any way. [UKT ¶]
English, in particular, has very little inflection, and hence a tendency
to have words that are identical to their roots. But more complicated inflection,
as well as other processes, can obscure the root; for example,
the root of <mice> is <mouse> (still a valid word), and the root
of <interrupt> is, arguably, <rupt>, which is not a word in English
and only appears in derivational forms (such as <disrupt>,
<corrupt>, <rupture>, etc.). The root <rupt> is
written as if it were a word, but it's not.
UKT: Points to remember from the above paragraph:
• Root still visible: simple inflection
¤ Root <run> --> <running>
¤ Root <rupt> --> <disrupt>, <corrupt>,
<rupture>, etc.
• Root obscure: complicated inflection
¤ Root <mouse> --> <mice>
This distinction between the word as a unit of speech and the root
as a unit of meaning is even more important in the case of
languages where roots have many different forms when used
in actual words, as is the case in Semitic languages. In these,
roots are formed by consonants alone, and different words
(belonging to different parts of speech) are derived from
the same root by inserting vowels. For example, in Hebrew,
the root gdl represents the idea of largeness,
and from it we have gadol and
gdola (masculine and feminine forms
of the adjective "big"), gadal
"he grew", higdil
"he magnified" and magdelet
"magnifier", along with many other words such as
godel "size" and
migdal "tower".
Secondary roots

"Consider
Israeli Hebrew מיקום mikúm ‘locating’, from
Israeli Hebrew מקמ √mqm ‘locate’, which derives from
Biblical Hebrew מקום måqom ‘place’, whose root
is קומ √qwm ‘stand’. A recent example introduced by the
Academy of the Hebrew Language is מדרוג
midrúg ‘rating’, from מדרג
midrág, whose root is דרג √drg ‘grade’."
[1]
According to
Ghil'ad Zuckermann, "this process is morphologically similar
to the production of
frequentative (iterative) verbs in Latin, for example:
• iactito ‘to toss about’ derives from iacto ‘to boast of,
keep bringing up, harass, disturb, throw, cast, fling away’, which in turn
derives from iacio ‘to throw, cast’ (whose past participle is iactus).
• scriptito ‘to write often, compose’ is based on scribo ‘to
write’ (<‘to draw lines, engrave with a sharp-pointed instrument’).
UKT note for future use: The English word <script> and the
Burmese-Myanmar word {hkyic} from the compound word {ré:hkyic} have very
similar pronunciations which are written with r2 consonants of Myanmar
akshara table. Note the pronunciations of r2 in Devanagari table.
s , {sa.}
 {hkric}, च Ca
{hkric}, च Ca
• dicto ‘to say often, repeat’ is from dico ‘to indicate,
say, speak, tell’.
• clamito ‘to cry loudly/often, shout violently’ derives from
clamo ‘call, shout’."
[2]
"Consider also Rabbinic Hebrew תרמ √trm
‘donate, contribute’ (Mishnah: T’rumoth 1:2: ‘separate priestly dues’),
which derives from Biblical Hebrew תרומה
t'rūmå ‘contribution’, whose root is רומ
√rwm ‘raise’; cf. Rabbinic Hebrew תרע √tr`
‘sound the trumpet, blow the horn’, from Biblical Hebrew
תרועה t'rū`å
‘shout, cry, loud sound, trumpet-call’, in turn from רוע √rw`."
[3]
"Similar cases occur in Arabic, e.g.
• مركز √mrkz, cf. ['markaza] ‘centralized (masculine, singular)’, from [markaz]
‘centre’, from [rakaza] ‘plant into the earth, stick up (a lance)’ (< ركز √rkz).
• أرجح √'rjħ, cf. [ta'arjaħa] ‘oscillated (masculine, singular)’, from ['urju:ħa]
‘swing (n)’, from [rajaħa] ‘weighed down, preponderated (masculine,
singular)’ (< رجح √rjħ).
• محور √mħwr, cf. [tamaħwara] ‘centred, focused (masculine, singular)’,
from [miħwar] ‘axis’, from [ħa:ra] ‘turned (masculine, singular)’ (< حور √ħwr).
• مسخر √msxr, cf. تمسخر [tamasxara] ‘mocked, made fun (masculine,
singular)', from مسخرة [masxara] ‘mockery’, from سخر [saxira] ‘mocked
(masculine, singular)’ (< سخر √sxr)."
[4]
UKT: End of Wikipedia article
Go back root-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Semantic 090820
Semantics is the study of meaning. The word "semantics" itself denotes
a range of ideas, from the popular to the highly technical. It is often used in
ordinary language to denote a problem of understanding that comes down to word
selection or connotation. This problem of understanding has been the subject of
many formal inquiries, over a long period of time. The word is derived from the
Greek word σημαντικός (semantikos), "significant",[1]
from σημαίνω (semaino), "to signify, to indicate" and that from
σήμα (sema), "sign, mark, token".
[2]
In linguistics, it is the study of interpretation of signs or symbols as used by
agents or communities within particular circumstances and contexts.
[3]
Within this view, sounds, facial expressions, body language,
proxemics
have semantic (meaningful) content, and each has several branches of study. In
written language, such things as paragraph structure and punctuation have
semantic content; in other forms of language, there is other semantic content.
[3]
The formal study of semantics intersects with many other fields of inquiry,
including
proxemics,
lexicology,
syntax,
pragmatics,
etymology
and others, although semantics is a well-defined field in its own right, often
with synthetic properties.[4]
In philosophy of language, semantics and reference are related fields. Further
related fields include
philology,
communication, and
semiotics.
The formal study of semantics is therefore complex.
The word semantic in its modern sense is considered to have first
appeared in French as sémantique in Michel Bréal's 1897 book, Essai de
sémantique'. In International Scientific Vocabulary semantics is also called
semasiology. The discipline of Semantics is distinct from Alfred
Korzybski's General Semantics, which is a system for looking at the semantic
reactions of the whole human organism in its environment to some event, symbolic
or otherwise.
In linguistics, semantics is the subfield that is devoted to the study of
meaning, as inherent at the levels of words, phrases, sentences, and larger
units of discourse (referred to as texts).
UKT: More in the Wikipedia article
Go back seman-note-b
Contents of this page
UKT 151209
The two words Brahman &
Brahmin can easily be mixed up leading
one to assume that they are the same. To
differentiate the two I usually use the
Bur-Myan and Romabama for each of them.
Brahman
{brah~ma} is the Axiomatic Creator-God, whereas
Brahmin is the human
{braah~ma.Na. poaN~Na:}.
From Wikipedia:
https://en.wikipedia.org/wiki/Shabda_Brahman
151209
UKT: I have inserted Skt-Dev (& gloss)
equivalents after some English
transliterations to help me understand the
terms better. The Skt-Dev are usually from
SpkSkt. Then, for some, by aks-to-aks
transliteration I arrive at Skt-Myan.
However, these words must not be confused
with Pal-Myan.
Shabda Brahman or Sabda-brahman
means transcendental sound
(Shatapatha Brahmana III.12.48) or sound
vibration (Shatpatha Brahmana Vi.16.51) or
the transcendental sound of the Vedas
(Shatpatha Brahmana Xi.21.36) or of Vedic
scriptures (Shatpatha Brahmana X.20.43).
[1]
Shabda
शब्द «śabda»
'sound, word' or sabda
{þûb~da.}, stands for word manifested by sound
('verbal') and such a word has innate power to
convey a particular sense or meaning
(Artha).
[UKT ¶]
UKT 151209: Now I can get a new word -
{þûb~da. brah~ma}.
This probably indicates that it is not the Mahabrahma of the Vaishnavite
Hindu Trinity.
According to the
Nyaya and the
Vaisheshika schools, Shabda means verbal testimony; to the
Sanskrit
grammarians,
Yaska, Panini
and
Katyayana it meant a unit of language or speech or vac. In the
philosophical terms this word appears for the first time in the
Maitri Upanishad (Sloka VI.22) that speaks of two kinds of
Brahman -
Shabda Brahman ('Brahman with sound') and Ashabda Brahman ('soundless
Brahman').
Bhartrhari speaks about the creative power of shabda, the manifold
universe is a creation of Shabda Brahman (Brihadaranyaka
Upanishad IV.i.2).
Speech is
equated with Brahman (Shatpatha Brahmana 2.1.4.10).The
Rig Veda states that Brahman extends as far as
Vāc (R.V.X.114.8),
and has hymns in praise of Speech as the Creator (R.V.X.71.7) and as the final
abode of Brahman (R.V.I.164.37). Time is the creative power of Shabda Brahman.[2][3]
Purva Mimamsa deals with Shabda Brahman ('cosmic sound or word')
which is endowed with names and forms and is projected in vedic revelations (the
mantras, hymns, prayers etc.).
Vedanta
deals with Parama Brahman ('the Ultimate Reality') which is transcendent
and devoid of names and forms. One has to become well established in Shabda
Brahman before realizing Parama Brahman. Vedas are not the product of
conventional language but the emanation of reality in form of Shabda
(sound, word) which is the sole cause of creation and is eternal. Purva
Mimamsa, an esoteric discipline, from the point of view of spiritual growth
aims at attaining the heavenly happiness by realizing Shabda Brahman
(cosmic sound) by conducting
yajnas that
help control the senses and the mind; when the mind and the senses are subdued
the inner subtle sound is realized as Shabda Brahman.
[4]
The fundamental theory of Indian classical music, art and poetry is grounded
in the theory of Nada Brahman or Shabda Brahman, and is linked
with the Vedic religion.[5]
The Apara Brahman mentioned by
Mandukya Upanishad is Nada Brahman or Shabda Brahman.
Shiva Samhita states that whenever and wherever there is causal stress or
Divine action, there is vibration (spandan or kampan), and
wherever there is vibration or movement there sound (Shabda) is
inevitable. "M" of Aum,
the primordial vac represents
shabda
which is the root and essence of everything; it is
Pranava and
Pranava is
Vedas, Vedas are Shabda Brahman.
Consciousness in all beings is Shabda Brahman.[6]
When the necessity of directing the
Mantra
(identical to Ishta) internally and to objects externally is transcended
then one gains Mantra chaitanya which then awakens Atman chaitanya,
the Divine Consciousness, and unites with it. The Mantra is Shabda
Brahman and Ishta is the light of Consciousness. The
prana,
body
and mind
along with the entire universe, are all expressions of Mantra chaitanya.
At the ultimate level of Shabda Brahman words become wordless, forms
become formless and all multiplicity unified in Consciousness residing in that
transcendent glory extends beyond mind and speech.[7]
In the
Bhagavad Gita (Sloka VI.44) the term Shabda Brahman has been used to
mean
Vedic injunctions.
Adi
Shankara explains that the Yogic impressions do not perish even when held up
for a long period, even he who seeks to comprehend the essence of
Yoga and begins to
tread the path of Yoga goes beyond the spheres of the fruits of Vedic works, he
sets them aside.
[8] In this context
Srimad Bhagavatam (Sloka III.33.7) has also been relied upon to high-light
the disregard of Vedic rituals by the advanced transcendentalists.
[9]
Gaudapada
clarifies that the letter "a" of
Aum leads to Visva,
the letter "u"" leads to
Taijasa
and the letter "m" leads to
Prajna. With regard to one freed from letters, there remains no
attainment (Mandkya Karika I.23). Aum is Shabda Brahman, Aum
is the Root Sound of which creation is a series of permutations.[10]
According to the Tantric concept,
Sound is the
first manifestation of Parama Shiva; in its primary stage it is a pschic
wave. Its very existence entails the presence of spandan or movement
('vibration') without which there cannot be sound; spandan is the quality
of
Saguna brahman and the world is the thought-projection of Saguna Shiva. The
very first sutra of Sarada Tilaka explains the significance and hidden
meaning of Shabda Brahman.[11]
UKT: End of Wikipedia article.
Go back sabda-brahman-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Synthetic_language 090820
A synthetic language, in linguistic typology, is a language
with a high morpheme-per-word ratio in one word. This linguistic
classification is largely independent of morpheme-usage classifications (such as
fusional,
agglutinative, etc.), although there is a common tendency for agglutinative
languages to exhibit synthetic properties.
Synthetic vs. isolating languages
Synthetic languages are frequently contrasted with isolating
languages [non-inflectional language]. It is more accurate to
conceive of languages as existing on a continuum, with strictly
isolating (consistently one morpheme per word) at one end and highly
polysynthetic (in which a single word may contain as much
information as an entire English sentence) at the other extreme.
Synthetic languages tend to lie around the middle of this scale.
Examples
Synthetic languages are numerous and well-attested, the most
commonly cited being Indo-European languages such as Spanish,
Greek, Latin, German, Italian, Russian, Polish
and Czech, as well as many languages of the Americas,
including Navajo, Nahuatl, Mohawk and Quechua.
There are several ways in which a language can exhibit synthetic
characteristics:
Derivational synthesis
In derivational synthesis, morphemes of different types
(nouns, verbs, affixes, etc.) are joined to create new words.
For example:
German: Aufsichtsratsmitgliederversammlung =>
"On-view-council-with-link-plural-gathering"
meaning "meeting of members of the supervisory board"
("with" and "link" (as in link of a chain)
forming a derivation that is the German word for "member")
Greek: υπερχοληστερολαίμια
=> "overmuch/high-cholesterol-blood+-ia(suffix)"
meaning "hypercholesterolemia"
Polish: przystanek => "beside-stand-little"
meaning " bus stop"
English: antidisestablishmentarianism =>
"against-ending-institutionalize-condition-advocate-ideology"
Russian: спасибо => "God-save" (thank you)
Relational synthesis
In relational synthesis, root words are joined to
bound morphemes to show grammatical function:
Italian: comunicandovele => "communicating-you (plural)-those
(feminine, plural)" meaning "(while or by) communicating those (feminine,
plural) to you(plural)"
Spanish: escribiéndomelo => "writing-me-it (masculine/neuter)"
meaning "(while or by) writing it to me"
Nahuatl: ocaltizquiya => "already-(she)-him-bathe-would"
meaning "she would have bathed him"
Japanese: 見せられがたい
(miseraregatai ) =>
"see-causative-passive-difficult" meaning
"it's difficult to be shown (this)"
Finnish: juoksentelisinkohan =>
"run-
erratic motion-
conditional-I-question-casual"
meaning "I wonder if I should run around (aimlessly)"
Turkish: Afyonkarahisarlılaştıramayabileceklerimizden misiniz =>
meaning "Are you (all) amongst the ones whom we may not be able to make
citizens of Afyonkarahisar?"
Degree of synthesis (Language continuum)
UKT: Language continuum (waiting for comments from my peers)
¤ polysynthetic <--> synthetic <--> isolating
e.g. Pali <--> French <--> English <--> Burmese <-->
Mandarin-Chinese
In order to demonstrate the "continuum" nature of the
isolating-synthetic-polysynthetic classification, some examples are shown below:
Mandarin-Chinese

English
"He travelled by hovercraft on the sea."
Largely isolating, but travelled and hovercraft
each have two morphemes per word,
the former being an example of relational synthesis (inflection), and the latter
of derivational synthesis (derivation).
Japanese
私たちにとって、この泣く子供の写真は見せられがたいものです。
(Watashitachi ni totte, kono naku
kodomo no shashin wa miseraregatai mono desu) means
strictly literally: "In our case, these pictures of children crying are
things that are difficult to be shown,"
approximately: We cannot bear being shown these pictures of children
crying in more idiomatic English.
In the example, virtually every word has more than one morpheme and some have up
to five (the particles ni, no, wa are
enclitic case markers, i.e., they are phonologically part of the previous
word).
en·clit·ic Linguistics n. 1. A word or particle that
has no independent accent and forms an accentual and sometimes also
graphemic unit with the preceding word. In <Give 'em the works>, the pronoun
<'em> is an enclitic. adj. 1. Forming an accentual unit with
the preceding word, and thus having no independent accent. [Late Latin
encliticus from Greek enklitikos from enklinein to lean on
en- on, in; See en- 2 klinein to lean; See
klei- in Indo-European Roots.] -- AHTD
Finnish
Käyttäytyessään tottelemattomasti oppilas saa jälki-istuntoa
means "Should he/she behave in an insubordinate manner, the student
will get detention."
Structurally: behaviour (present/future tense) (of his/hers) obey
(without)(in the manner/style) studying (he/she who (should be))
gets detention (some).
Practically every word is derived and/or inflected, and one word can be
considered polysynthetic. This is, however, very formal language - almost like
judicial text - and usually replaced by more analytic structure:
Kun oppilas käyttäytyy tottelemattomasti, hän saa jälki-istuntoa.
Mohawk
Washakotya'tawitsherahetkvhta'se
means "He ruined her dress"
(strictly, "He made the thing that one puts on one's body ugly for her").
One word expresses the idea that would be conveyed in an entire sentence
in a non-polysynthetic language.
Further information:
Polysynthetic language
Oligosynthesis
Oligosynthetic languages are a theoretical notion created by
Benjamin Whorf with no known examples existing in natural languages. Such
languages would be functionally synthetic, but make use of a very limited array
of morphemes (perhaps just a few hundred). Whorf proposed that
Nahuatl [language] was oligosynthetic, but this has since been discounted by most
linguists.
UKT: End of Wikipedia article.
Go back synthetic-lang-note-b
Contents of this page
From Wikipedia:
http://en.wikipedia.org/wiki/Stem 090818
In linguistics, a stem (sometimes also theme) is a part of a
word. The term is used with slightly different meanings.
[UKT: The word stem is used in two usages as follows:]
In one usage, a stem is a form to which affixes can be attached.
[1]
Thus, in this usage, the English word <friendships>
contains the stem <friend>, to which the derivational suffix
<-ship> is attached to form a new stem <friendship>,
to which the inflectional suffix <-s> is attached. In a variant
of this usage, the root of the word (in the example,
<friend>) is not counted as a stem.
In a slightly different usage, which is adopted in the remainder of this article,
a word has a single stem, namely the part of the word
that is common to all its inflected variants.
[2]
Thus, in this usage, all derivational affixes are part of the stem.
For example, the stem of <friendships> is <friendship>,
to which the inflectional suffix <-s> is attached.
Stems may be roots, e.g. <run>, or they may be morphologically
complex, as in compound words (cf. the compound nouns <meat ball>
or <bottle opener>) or words with
derivational morphemes (cf. the derived verbs <black-en> or
<standard-ize>). [UKT ¶ ]
UKT: Stems may be:
• roots : <run>
• morphologically complex words: <meat ball> , <bottle opener>
• words with derivational morphemes: <black-en> , <standard-ize>
Thus, the stem of the complex English noun <photographer>
is <photo·graph·er>, but not <photo>. [UKT ¶ ]
For another example, the root of the English verb form <destabilized>
is <stabil->, a form of <stable> that does not occur alone;
the stem is <de·stabil·ize>, which includes the derivational affixes
<de-> and <-ize>, but not the inflectional past tense suffix
<-(e)d>. That is, a stem is that part of a word that
inflectional affixes attach to.
UKT: For the English word <destabilized>
• root: <stabil-> - a form of <stable>
¤ prefix: <de->
¤ suffix: <-ize> : (<-(e)d> is a suffix but not counted)
• stem: <de·stabil·ize>
The exact use of the word 'stem' depends on the morphology of the language
is question. In Athabaskan linguistics, for example, a verb stem is a root
that cannot appear on its own, and that carries the
tone of the word. Athabaskan verbs typically have two stems
in this analysis, each preceded by prefixes.
Citation forms (lemma or dictionary form) and bound morphemes
In languages with very little inflection, such as English and Chinese, the
stem is usually not distinct from the "normal" form of the word (the lemma,
citation or dictionary form). [UKT ¶ ]
In other languages, however, stems may rarely or
never occur on their own. For example, the English verb stem <run> is
indistinguishable from its present tense form (except in the third person
singular); but the equivalent Spanish verb stem corr- never appears as
such, since it is cited with the infinitive inflection (correr ) and
always appears in actual speech as a non-finite (infinitive or participle) or
conjugated form. Morphemes like Spanish corr- which can't occur on their
own in this way, are usually referred to as bound morphemes.
A stem is the part of the word that never changes even when morphologically
infected, whilst a lemma is the base form of the verb. For example,
given the word <produced>, its lemma (linguistics) is <produce>,
however the stem is <produc> : this is because there are words
such as production.
[3]
Paradigms and suppletion
A list of all the inflected forms of a stem is called its inflectional
paradigm. The paradigm of the adjective <tall> is given below,
and the stem of this adjective is <tall>.
• <tall> (positive); <taller> (comparative); <tallest> (superlative)
Some paradigms do not make use of the same stem throughout; this phenomenon
is called suppletion. An example of a suppletive paradigm is the paradigm
for the adjective <good> : its stem changes from <good>
to the bound morpheme bet-.
• <good> (positive); <better> (comparative); <best> (superlative)
UKT: End of Wikipedia article.
Go back word-stem-note-b
Contents of this page
Yāska :
{yaaþ~ka.}
- UKT 151208
It is said that nothing is known about the linguist Yaska except that he was the
author of Nirukta
{ni.roat~ta.} 'etymology'. Yet, the word Nirukta, and other words
Vyākaraṇa
 {bya-ka.reigN:} and Vedanga
{bya-ka.reigN:} and Vedanga
 {wé-dïn~ga.} tell me a lot about him. To us Vedanga 'Limbs
of the Veda' is more important than the present-day "Veda the collection of
hymns to unsubstantiated gods and goddesses". Veda is Knowledge itself -
not just hymns and formulas for sacrifices which the Buddha condemns. In ¤ Dictionary of Pali-derived Myanmar words
(in Bur-Myan) (PDMD), the author U Tun Myint (of Univ. of Rangoon Press, 1968) gives
the following. Please remember that I am not well versed in Bur-Myan
grammar, and that PDMD is just a dictionary - not a treatise on grammar.
{wé-dïn~ga.} tell me a lot about him. To us Vedanga 'Limbs
of the Veda' is more important than the present-day "Veda the collection of
hymns to unsubstantiated gods and goddesses". Veda is Knowledge itself -
not just hymns and formulas for sacrifices which the Buddha condemns. In ¤ Dictionary of Pali-derived Myanmar words
(in Bur-Myan) (PDMD), the author U Tun Myint (of Univ. of Rangoon Press, 1968) gives
the following. Please remember that I am not well versed in Bur-Myan
grammar, and that PDMD is just a dictionary - not a treatise on grammar.
Nirukta
{ni.roat~ta.} - UTM PDMD ? (not included)
Vyākaraṇa
{bya-ka.reigN:} - UTM PDMD207
Vedanga
{wé-dïn~ga.} - UTM PDMD302
Same as
 {wé-da.ïn~ga} 'limbs of Knowledge'. There are 6:
{wé-da.ïn~ga} 'limbs of Knowledge'. There are 6:
1.
 {kûp~pa.} «kalpa»
'modes of sacrifice'
{kûp~pa.} «kalpa»
'modes of sacrifice'
2.
{bya-ka.reigN:} «vyākaraṇa»
'rules of grammar'
3.
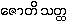 {zau:ti.þût~hta.}*
«jyotiṣa» 'mathematics and predictive astrology' .
{zau:ti.þût~hta.}*
«jyotiṣa» 'mathematics and predictive astrology' .
4.
 {þaik~hka} «śikṣā»
'phonetics, phonology, and sandhi
{þaik~hka} «śikṣā»
'phonetics, phonology, and sandhi
 {þûn~Di} सन्धिः
'joining at morpheme or word boundaries'. See UTM PDMD359. MLC MED508 does
not give any grammatical meaning.
{þûn~Di} सन्धिः
'joining at morpheme or word boundaries'. See UTM PDMD359. MLC MED508 does
not give any grammatical meaning.
5.
{ni.roat~ta.} «nirukta»:
etymology
6.
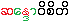 {hsûn~dau:wi.si.ti.} «chandas»:
meter
{hsûn~dau:wi.si.ti.} «chandas»:
meter
* I, as one who has studied Hindu Predictive Astrology,
specializing in Astakavarga after B.V. Raman, take this to be
Astronomy-Astrology. See Wikipedia:
https://en.wikipedia.org/wiki/Bangalore_Venkata_Raman 151208
Note the word
शास्त्र (= श ा स ् त ् र
) 'manual of instruction, any sacred book or composition of divine
authority'.
From Wikipedia:
https://en.wikipedia.org/wiki/Y%C4%81ska 151208
Yāska यास्क
(= य ा स ् क)
{yaaþ~ka.}, was an early
Sanskrit grammarian who preceded
Pāṇini (fl.
4th BC), assumed to have lived in the 6th or 5th century BC. Nothing is known
about him other than that he is traditionally identified as the author of
Nirukta,
the discipline of "etymology" (explanation of words) within
Vyākaraṇa 'Sanskrit
grammatical tradition'.
Yaska is the author of the Nirukta, a technical treatise on etymology,
lexical category and the semantics of Sanskrit words. He is thought to have
succeeded
Śākaṭāyana,
an old grammarian and expositor of the Vedas, who is mentioned in his text.
The Nirukta attempts to explain how certain words get to have their meanings,
especially in the context of interpreting the Vedic texts. It includes a system
of rules for forming words from roots and affixes, and a glossary of irregular
words, and formed the basis for later lexicons and dictionaries. It consists of
three parts, viz.:(i) Naighantuka, a collection of synonyms; (ii)
Naigama, a collection of words peculiar to the Vedas, and (iii) Daivata,
words relating to deities and sacrifices.
The Nirukta was one of the six
vedangas or
compulsory ritual subjects in syllabus of Sanskrit scholarship in ancient India.
Yāska defines four main categories of words:
[1]
1. nāma –
nouns or substantives
2. ākhyāta – verbs
3. upasarga – pre-verbs or prefixes
4. nipāta –
particles, invariant words (perhaps
prepositions)
Yāska singled out two main
ontological categories: a process or an action (bhāva), and an entity
or a being or a thing (sattva). Then he first defined the verb as that in
which the bhāva ('process') is predominant whereas a noun is that in which the
sattva ('thing') is predominant. The 'process' is one that has, according to one
interpretation, an early stage and a later stage and when such a 'process' is
the dominant sense, a finite verb is used as in vrajati, 'walks', or
pachati, 'cooks'.[1]
But this characterisation of noun /
verb is
inadequate, as some processes may also have nominal forms. For e.g., He went
for a walk. Hence, Yāska proposed that when a process is referred to as a
'petrified' or 'configured' mass (mUrta) extending from start to finish,
a verbal noun should be used, e.g. vrajyā, a walk, or pakti, a
cooking. The latter may be viewed as a case of summary scanning,[2]
since the element of sequence in the process is lacking.
These concepts are related to modern notions of
grammatical aspect, the murta constituting the
perfective and the bhāva the
imperfective aspect.
Yāska also gives a test for nouns both
concrete and abstract: nouns are words which can be indicated by the pronoun
that.
As in modern
semantic
theory, Yāska views words as the main carriers of meaning. This view – that
words have a primary or preferred ontological status in defining meaning, was
fiercely debated in the Indian tradition over many centuries. The two sides of
the debate may be called the Nairuktas (based on Yāska's Nirukta,
atomists),
vs the
Vaiyākarans (grammarians following Pāṇini,
holists), and
the debate continued in various forms for twelve centuries involving different
philosophers from the
Nyaya,
Mimamsa and
Buddhist schools.
In the prātishākhya texts that precede Yāska, and possibly Sakatayana as
well, the gist of the controversy was stated cryptically in sutra form as "saṃhitā
pada-prakṛtiḥ". According to the atomist view, the words would be the primary
elements (prakṛti) out of which the sentence is constructed, while the holistic
view considers the sentence as the primary entity, originally given in its
context of utterance, and the words are arrived at only through analysis and
abstraction.
This debate relates to the atomistic vs holistic interpretation of linguistic
fragments – a very similar debate is raging today between traditional
semantics
and
cognitive linguistics, over the view whether words in themselves have
semantic interpretations that can be composed to form larger strings. The
cognitive linguistics view of semantics is that any definition of a word
ultimately constrains it meanings because the actual meaning of a word can only
be construed by considering a large number of individual contextual cues.
Yāska also defends the view, presented first in the lost text of
Sakatayana that etymologically, most nouns have their origins in verbs. An
example in English may be the noun origin, derived from the Latin
originalis, which is ultimately based on the verb oriri, "to rise".
This view is related to the position that in defining agent categories,
behaviours are ontologically primary to, say, appearance. This was also a source
for considerable debate for several centuries (see
Sakatayana for details).
UKT: End of Wiki article.
Go back Yaska-note-b
Contents of this page
End of TIL file