phono.htm
collection by U Kyaw Tun, M.S. (I.P.S.T., U.S.A.). Not for sale. No copyright. Free for everyone. Prepared for students of TIL Computing and Language Center, Yangon, MYANMAR .
index.htm | |Top
lang-mean-indx.htm
Phonology
Representing phonemes
Phoneme inventories
Doing a phoneme inventory
Allophones (phonemic distinctions)
Change of phoneme
inventory over time
Other topics in phonology
Development of the field
UKT Notes
• Government phonology
• phoneme
• phonemic principle (phonemic orthography)
• phonetics
• Shiva Sutras
Noteworthy passages in this file: (always check with
the original section from which they are taken.)
• The /t/ sounds in the words <tub>, <stub>, <but>, <butter>,
and <button> are all pronounced differently in American English, yet are
all intuited to be of "the same sound", therefore they constitute another
example of allophones of the same phoneme in English. However, an intuition such
as this could be interpreted as a function of post-lexical recognition of the
sounds. That is, all are seen as examples of English /t/ once the word itself
has been recognized.
by UKT based on Wikipedia: http://en.wikipedia.org/wiki/Phonology 090819
Phonology (from Ancient Greek: φωνή, phōnē, "voice, sound" and λόγος, lógos, "word, speech, subject of discussion") is the systematic use of sound to encode meaning in any spoken human language, or the field of linguistics studying this use. Just as a language has syntax and vocabulary, it also has a phonology in the sense of a sound system. When describing the formal area of study, the term typically describes linguistic analysis either beneath the word (e.g., syllable, onset and rime, phoneme, articulatory gesture, articulatory feature, mora, etc.) or to units at all levels of language that are thought to structure sound for conveying linguistic meaning. [UKT ¶ ]
Phonology is viewed as the subfield of linguistics that deals with the sound systems of languages. Whereas phonetics is about the physical production, acoustic transmission and perception of the sounds of speech, phonology describes the way sounds function within a given language or across languages to encode meaning. The term "phonology" was used in the linguistics of a greater part of the 20th century as a cover term uniting phonemics and phonetics. Current phonology can interface with disciplines such as psycholinguistics and speech perception, resulting in specific areas like articulatory or laboratory phonology.
An important part of traditional forms of phonology has been
studying which sounds can be grouped into distinctive units
within a language; these units are known as phonemes.
For example, in English, the [p] sound in <pot> is
aspirated (pronounced [pʰ]
![]() {hpa.}), while the word- and syllable-final [p]
{hpa.}), while the word- and syllable-final [p]
![]() {pa.} in soup is not
aspirated (indeed, it might be realized as a glottal stop). However, English
speakers intuitively treat both sounds as variations (allophones)
of the same phonological category, that is, of the phoneme /p/. Traditionally,
it would be argued that if a word-initial aspirated [p] were interchanged with
the word-final unaspirated [p] in soup, they would still be perceived by
native speakers of English as "the same" /p/. (However, speech perception
findings now put this theory in doubt.) Although some sort of "sameness" of
these two sounds holds in English, it is not universal and may be absent in
other languages. For example, in
Thai,
Hindi, and
Quechua,
aspiration and non-aspiration differentiates phonemes: that is, there are word
pairs that differ only in this feature (there are
minimal
pairs differing only in aspiration).
{pa.} in soup is not
aspirated (indeed, it might be realized as a glottal stop). However, English
speakers intuitively treat both sounds as variations (allophones)
of the same phonological category, that is, of the phoneme /p/. Traditionally,
it would be argued that if a word-initial aspirated [p] were interchanged with
the word-final unaspirated [p] in soup, they would still be perceived by
native speakers of English as "the same" /p/. (However, speech perception
findings now put this theory in doubt.) Although some sort of "sameness" of
these two sounds holds in English, it is not universal and may be absent in
other languages. For example, in
Thai,
Hindi, and
Quechua,
aspiration and non-aspiration differentiates phonemes: that is, there are word
pairs that differ only in this feature (there are
minimal
pairs differing only in aspiration).
In addition to the minimal units that can serve the purpose of differentiating meaning (the phonemes), phonology studies how sounds alternate, i.e. replace one another in different forms of the same morpheme (allomorphs), as well as, e.g., syllable structure, stress, accent, and intonation.
The principles of phonological theory have also been applied to the analysis of sign languages, even though the sub-lexical units are not instantiated as speech sounds. The principles of phonological analysis can be applied independently of modality because they are designed to serve as general analytical tools, not language-specific ones. On the other hand, it must be noted, it is difficult to analyze phonologically a language one does not speak, and most phonological analysis takes place with recourse to phonetic information.
The writing systems of some languages are based on the phonemic principle of having one letter (or combination of letters) per phoneme and vice-versa. [UKT ¶ ]
UKT: Burmese-Myanmar, derived from the Asoka script (dubbed Brahmi) is a writing system based on sound phonemic principle. It is not an alphabet but an abugida. -- UKT 090825
Ideally, speakers can correctly write whatever they can say, and can correctly read anything that is written. However in English, different spellings can be used for the same phoneme (e.g., <rude> and <food> /have the same vowel sounds), and the same letter (or combination of letters) can represent different phonemes (e.g., the "th" consonant sounds of <thin> and <this> are different). In order to avoid this confusion based on orthography, phonologists represent phonemes by writing them between two slashes: " / / ". On the other hand, reference to variations of phonemes or attempts at representing actual speech sounds are usually enclosed by square brackets: " [ ] ". While the letters between slashes may be based on spelling conventions, the letters between square brackets are usually the International Phonetic Alphabet (IPA) or some other phonetic transcription system. Additionally, angled brackets " < >" can be used to isolate the graphemes of an alphabetic writing system.
UKT: The following IPA transcriptions are taken from DJPD16:
¤ <rude> /rudː/ ; <food> /fudː/
¤ <thin> /θɪn/ ; <this> /ðɪs/
Part of the phonological study of a language involves looking at data (phonetic transcriptions of the speech of native speakers) and trying to deduce what the underlying phonemes are and what the sound inventory of the language is. Even though a language may make distinctions between a small number of phonemes, speakers actually produce many more phonetic sounds. Thus, a phoneme in a particular language can be instantiated in many ways.
UKT: The phrase "phonetic transcriptions of the speech of native speakers" should be used with care. A "phonetic transcription" made by an L1-speaker and L2-speaker are bound to be different. I hold that a transcriber no matter how well trained he is, is still under the influence of his L1 and his culture and the transcriptions given in various pronouncing dictionaries should be taken only as guides. -- UKT 090825
Traditionally, looking for minimal pairs forms part of the research in studying the phoneme inventory of a language. A minimal pair is a pair of words from the same language, that differ by only a single categorical sound, and that are recognized by speakers as being two different words. When there is a minimal pair, the two sounds are said to be examples of realizations of distinct phonemes. However, since it is often impossible to detect or agree to the existence of all the possible phonemes of a language with this method, other approaches are used as well.
If two similar sounds do not belong to separate phonemes, they are called allophones of the same underlying phoneme. For instance, voiceless stops (/p/, /t/, /k/) can be aspirated. In English, voiceless stops at the beginning of a stressed syllable (but not after /s/) are aspirated, whereas after /s/ they are not aspirated. This can be seen by putting the fingers right in front of the lips and noticing the difference in breathiness in saying <pin> versus <spin>. There is no English word <pin> that starts with an unaspirated p, therefore in English, aspirated [pʰ] (the [ʰ] means aspirated) and unaspirated [p] are allophones of the same phoneme /p/. This is an example of a complementary distribution.
The /t/ sounds in the words <tub>, <stub>, <but>, <butter>, and <button> are all pronounced differently in American English, yet are all intuited to be of "the same sound", therefore they constitute another example of allophones of the same phoneme in English. However, an intuition such as this could be interpreted as a function of post-lexical recognition of the sounds. That is, all are seen as examples of English /t/ once the word itself has been recognized.
The findings and insights of speech perception and articulation research complicates this idea of interchangeable allophones being perceived as the same phoneme, no matter how attractive it might be for linguists who wish to rely on the intuitions of native speakers. First, interchanged allophones of the same phoneme can result in unrecognizable words. Second, actual speech, even at a word level, is highly co-articulated, so it is problematic to think that one can splice words into simple segments without affecting speech perception. In other words, interchanging allophones is a nice idea for intuitive linguistics, but it turns out that this idea can not transcend what co-articulation actually does to spoken sounds. Yet human speech perception is so robust and versatile (happening under various conditions) because, in part, it can deal with such co-articulation.
There are different methods for determining why allophones should fall categorically under a specified phoneme. Counter-intuitively, the principle of phonetic similarity is not always used. This tends to make the phoneme seem abstracted away from the phonetic realities of speech. It should be remembered that, just because allophones can be grouped under phonemes for the purpose of linguistic analysis, this does not necessarily mean that this is an actual process in the way the human brain processes a language. On the other hand, it could be pointed out that some sort of analytic notion of a language beneath the word level is usual if the language is written alphabetically. So one could also speak of a phonology of reading and writing.
The particular sounds which are phonemic in a language can change over time. At one time, [f] and [v] were allophones in English, but these later changed into separate phonemes. This is one of the main factors of historical change of languages as described in historical linguistics.
Phonology also includes topics such as phonotactics (the phonological constraints on what sounds can appear in what positions in a given language) and phonological alternation (how the pronunciation of a sound changes through the application of phonological rules, sometimes in a given order which can be feeding or bleeding, [1] as well as prosody, the study of suprasegmentals and topics such as stress and intonation.
In ancient India, the Sanskrit grammarian Pāṇini (c. 520–460 BC) in his text of Sanskrit phonology, the Shiva Sutras, discusses something like the concepts of the phoneme, the morpheme and the root. The Shiva Sutras describe a phonemic notational system in the fourteen initial lines of the Aṣṭādhyāyī . The notational system introduces different clusters of phonemes that serve special roles in the morphology of Sanskrit, and are referred to throughout the text. Panini's grammar of Sanskrit had a significant influence on Ferdinand de Saussure, the father of modern structuralism, who was a professor of Sanskrit.
The Polish scholar Jan Baudouin de Courtenay, (together with his former student Mikołaj Kruszewski) coined the word phoneme in 1876, and his work, though often unacknowledged, is considered to be the starting point of modern phonology. He worked not only on the theory of the phoneme but also on phonetic alternations (i.e., what is now called allophony and morphophonology). His influence on Ferdinand de Saussure was also significant.
Prince Nikolai Trubetzkoy's posthumously published work, the Principles of Phonology (1939), is considered the foundation of the Prague School of phonology. Directly influenced by Baudouin de Courtenay, Trubetzkoy is considered the founder of morphophonology, though morphophonology was first recognized by Baudouin de Courtenay. Trubetzkoy split phonology into phonemics and archiphonemics; the former has had more influence than the latter. Another important figure in the Prague School was Roman Jakobson, who was one of the most prominent linguists of the twentieth century.
In 1968 Noam Chomsky and Morris Halle published The Sound Pattern of English (SPE), the basis for Generative Phonology. In this view, phonological representations are sequences of segments made up of distinctive features. These features were an expansion of earlier work by Roman Jakobson, Gunnar Fant, and Morris Halle. The features describe aspects of articulation and perception, are from a universally fixed set, and have the binary values + or -. There are at least two levels of representation: underlying representation and surface phonetic representation. Ordered phonological rules govern how underlying representation is transformed into the actual pronunciation (the so called surface form). An important consequence of the influence SPE had on phonological theory was the downplaying of the syllable and the emphasis on segments. Furthermore, the Generativists folded morphophonology into phonology, which both solved and created problems.
Natural Phonology was a theory based on the publications of its proponent David Stampe in 1969 and (more explicitly) in 1979. In this view, phonology is based on a set of universal phonological processes which interact with one another; which ones are active and which are suppressed are language-specific. Rather than acting on segments, phonological processes act on distinctive features within prosodic groups. Prosodic groups can be as small as a part of a syllable or as large as an entire utterance. Phonological processes are unordered with respect to each other and apply simultaneously (though the output of one process may be the input to another). The second-most prominent Natural Phonologist is Stampe's wife, Patricia Donegan; there are many Natural Phonologists in Europe, though also a few others in the U.S., such as Geoffrey Pullum. The principles of Natural Phonology were extended to morphology by Wolfgang U. Dressler, who founded Natural Morphology.
In 1976 John Goldsmith introduced autosegmental phonology. Phonological phenomena are no longer seen as operating on one linear sequence of segments, called phonemes or feature combinations, but rather as involving some parallel sequences of features which reside on multiple tiers. Autosegmental phonology later evolved into Feature Geometry, which became the standard theory of representation for the theories of the organization of phonology as different as Lexical Phonology and Optimality Theory.
Government Phonology, which originated in the early 1980s as an attempt to unify theoretical notions of syntactic and phonological structures, is based on the notion that all languages necessarily follow a small set of principles and vary according to their selection of certain binary parameters. That is, all languages' phonological structures are essentially the same, but there is restricted variation that accounts for differences in surface realizations. Principles are held to be inviolable, though parameters may sometimes come into conflict. Prominent figures include Jonathan Kaye, Jean Lowenstamm, Jean-Roger Vergnaud, Monik Charette, John Harris, and many others.
In a course at the LSA summer institute in 1991, Alan Prince and Paul Smolensky developed Optimality Theory — an overall architecture for phonology according to which languages choose a pronunciation of a word that best satisfies a list of constraints which is ordered by importance: a lower-ranked constraint can be violated when the violation is necessary in order to obey a higher-ranked constraint. The approach was soon extended to morphology by John McCarthy and Alan Prince, and has become the dominant trend in phonology. Though this usually goes unacknowledged, Optimality Theory was strongly influenced by Natural Phonology; both view phonology in terms of constraints on speakers and their production, though these constraints are formalized in very different ways.
Broadly speaking Government Phonology (or its descendant, strict-CV phonology) has a greater following in the United Kingdom, whereas Optimality Theory is predominant in North America.
UKT: End of Wikipedia article.
From Wikipedia: http://en.wikipedia.org/wiki/Government_Phonology 090825
Government phonology (GP) is a theoretical framework of linguistics and more specifically of phonology. The framework aims to provide a non-arbitrary account for phonological phenomena by replacing the rule component of phonology with a restricted set of universal principles and parameters. As in Noam Chomsky’s principles and parameters approach to syntax, the differences in phonological systems across languages are captured through different combinations of parametric settings.
In GP, phonological representations consist of zero (e.g. vowel-zero in French) or more combinations of elements. These elements are the primitives of the theory and are deemed to be universally present in all human phonological systems. They are assumed to correspond to characteristic acoustic signatures in the signal, or hot features as previously referred to.
There are 6 elements believed to be existent across all languages, namely (A), (I), (U),(?),(L) and (H). They represent backness, frontness, roundness, stopness, a low tone and a high tone respectively.
As in French, it is possible to have empty nuclei, marked (_), which are subject to the phonological Empty Category Principle (ECP) . Unlike features, each element is a monovalent, and potentially interpretable phonological expression. Its actual interpretation depends on what phonological constituent dominates it, and whether it occupies a head or operator position within a phonological expression.
UKT: End of Wikipedia article.
Go back govt-phonolog-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Phoneme 090814
Ed. by UKT using brackets in TIL convention: <...> English-Latin; {...} Romabama or Burmese-extended Latin. Text in [...] are those inserted by UKT for better understanding.
In human phonology, a phoneme (from the Greek: φώνημα, phōnēma, "a sound uttered") is the smallest segmental unit of sound employed to form meaningful contrasts between utterances.
In effect, a phoneme is a group of slightly different sounds which are all perceived to have the same function by speakers of the language in question. An example of a phoneme is the /k/ sound [POA (Place of Articulation in the mouth): velar-stop] in the words <kit> and <skill>. (In transcription, phonemes are placed between slashes, as here.) Even though most [English] native speakers don't notice, in most [English] dialects, the <k>s in each of these words are actually pronounced differently: they are different speech sounds, or phones (which, in transcription, are placed in square brackets). In our example, the /k/ in <kit> is aspirated, [kʰ], while the /k/ in <skill> is not, [k]. The reason why these different sounds are nonetheless considered to belong to the same phoneme in English is that if an English-speaker used one instead of the other, the meaning of the word would not change: saying [kʰ] in <skill> might sound odd, but the word would still be recognized. By contrast, some other sounds could be substituted which would cause a change in meaning, producing words like <still> (substituting /t/ [POA: dental-stop]), <spill> (substituting /p/ [POA: bilabial-stop]) and <swill> (substituting /w/ [POA: bilabial-approximant]). These other sounds (/t/, /p/ and /w/) are, in English, different phonemes. [- primarily because the POAs are different]. [UKT ¶ ]
In some languages [such as Burmese-Myanmar / Hindi-Devanagari ],
however, [k] and [kʰ] are different phonemes
[![]() {ka.}/क Ka and
{ka.}/क Ka and
![]() {ka.}/ख
Kha}], and are perceived as such by the speakers of those languages.
Thus, in Icelandic, /kʰ/ is the first sound of kátur 'cheerful',
while /k/ is the first sound of gátur 'riddles'.
{ka.}/ख
Kha}], and are perceived as such by the speakers of those languages.
Thus, in Icelandic, /kʰ/ is the first sound of kátur 'cheerful',
while /k/ is the first sound of gátur 'riddles'.
In many languages, each letter [grapheme] in the spelling system represents one phoneme.
[In Burmese-Myanmar IPA [k] is represented by
![]() {ka. - ka.kri:} alone and IPA [kʰ] by
{ka. - ka.kri:} alone and IPA [kʰ] by
![]() {hka. - hka.hkwé:} only. -- MEDict051] However, in English spelling
there is a very poor match between spelling and phonemes. For example,
the two letters <sh> represent the single phoneme /ʃ/
[POA post-alveolar-fricative], while the letters <k> and <c>
can both represent the phoneme /k/ (as in <kit> and <cat> ).
{hka. - hka.hkwé:} only. -- MEDict051] However, in English spelling
there is a very poor match between spelling and phonemes. For example,
the two letters <sh> represent the single phoneme /ʃ/
[POA post-alveolar-fricative], while the letters <k> and <c>
can both represent the phoneme /k/ (as in <kit> and <cat> ).
Phones that belong to the same phoneme, such as [t] and [tʰ] for English /t/, are called allophones. A common test to determine whether two phones are allophones or separate phonemes relies on finding minimal pairs: words that differ by only the phones in question. For example, the words tip and dip illustrate that [t] and [d] are separate phonemes, /t/ and /d/, in English, whereas the lack of such a contrast in Korean (/tʰata/ is pronounced [tʰada], for example) indicates that in this language they are allophones of a phoneme /t/.
In sign languages, the basic elements of gesture and location were formerly called cheremes (or cheiremes), but general usage changed to phoneme. Tonic phonemes are sometimes called tonemes, and timing phonemes chronemes.
Some linguists (such as Roman Jakobson, Morris Halle, and Noam Chomsky) consider phonemes to be further decomposable into features, such features being the true minimal constituents of language. Features overlap each other in time, as do suprasegmental phonemes in oral language and many phonemes in sign languages. Features could be designated as acoustic (Jakobson) or articulatory (Halle & Chomsky) in nature.
The term phonème was reportedly first used by A. Dufriche-Desgenettes in 1873, but it referred to only a sound of speech. The term phoneme as an abstraction was developed by the Polish linguist Jan Niecisław Baudouin de Courtenay and his student Mikołaj Kruszewski during 1875-1895. The term used by these two was fonema, the basic unit of what they called psychophonetics. Conceptions of the phoneme were then elaborated in the works of Nikolai Trubetzkoi and others of the Prague School (during the years 1926-1935), as well as in that of structuralists like Ferdinand de Saussure, Edward Sapir, and Leonard Bloomfield. Some structuralists wished to eliminate a cognitive or psycholinguistic function for the phoneme.
Later, it was also used in generative linguistics, most famously by Noam Chomsky and Morris Halle, and remains central to many accounts of the development of modern of phonology. As a theoretical concept or model, though, it has been supplemented and even replaced by others.
Some languages make use of pitch for phonemic distinction. In this case, the tones used are called tonemes. Some languages distinguish words made up of the same phonemes (and tonemes) by using different durations of some elements, which are called chronemes. However, not all scholars working on languages with distinctive duration use this term.
UKT: Burmese-Myanmar uses both pitch and register for phonetic distinction and is known as a pitch-register language. At one time it was classified as tone language similar to Thai. See Wikipedia: http://en.wikipedia.org/wiki/Register 090815
Usually, long vowels and consonants are represented either by a length indicator or doubling of the symbol in question.
UKT: e.g., the vowel length indicator in Burmese-Myanmar is the
{weik-hkya.} or the
{mauk-hkya.}.
short vowel --> long vowel
Burmese-Myanmar:{a.} -->
{a} (ignoring the creak
{aa.}, and the emphatic
{a:} for the moment)
Hindi-Devanagari: अ a --> आ ā
In sign languages, phonemes may be classified as Tab (elements of location, from Latin tabula), Dez (the hand shape, from designator), Sig (the motion, from signation), and with some researchers, Ori (orientation). Facial expressions and mouthing are also phonemic.
The distinction between phonetic and phonemic systems gave rise of Kenneth Pike's concepts of Emic and etic description.
A transcription that only indicates the different phonemes of a language is said to be phonemic. In languages that are morphophonemic (vowels in particular), pronunciations that correspond to the canonical alphabet pronunciations are called alphaphonemic. Such transcriptions are enclosed within virgules (slashes), / /; these show that each enclosed symbol is claimed to be phonemically meaningful. On the other hand, a transcription that indicates finer detail, including allophonic variation like the two English L's, is said to be phonetic, and is enclosed in square brackets, [ ].
UKT: "Allophones of English /l/ may be noticed if the 'light' [l] of <leaf > [ˈliːf] is contrasted with the 'dark' [ɫ] of <feel> [ˈfiːɫ]. Again, this difference is much more obvious to a Turkish speaker, for whom /l/ and /ɫ/ are separate phonemes, than to an English speaker, for whom they are allophones of a single phoneme." -- from: Wikipedia http://en.wikipedia.org/wiki/Allophone 090815
In Burmese-Myanmar, the L following the vowel is usually silent, e.g. in{bol} .
The common notation used in linguistics employs virgules (slashes) (/ /)
around the symbol that stands for the phoneme. For example, the phoneme for the
initial consonant sound in the word "phoneme" would be written as
/f/. In other words, the graphemes are <ph>,
but this digraph represents one sound /f/.
Allophones,
more phonetically specific descriptions of how a given phoneme might be commonly
instantiated, are often denoted in linguistics by the use of diacritical or
other marks added to the phoneme symbols and then placed in square brackets ([
]) to differentiate them from the phoneme in slant brackets
The symbols of the International Phonetic Alphabet (IPA) and extended sets adapted to a particular language are often used by linguists to write phonemes of oral languages, with the principle being one symbol equals one categorical sound. Due to problems displaying some symbols in the early days of the Internet, systems such as X-SAMPA and Kirshenbaum were developed to represent IPA symbols in plain text. As of 2004, any modern web browser can display IPA symbols (as long as the [computer's] operating system provides the appropriate fonts), and we use this system in this article.
There is one published set of phonemic symbols for sign language, the Stokoe notation, used for linguistic research and originally developed for American Sign Language. Stokoe notation has since been applied to British Sign Language by Kyle and Woll, and to Australian Aboriginal sign languages by Adam Kendon. Other sign notations, such as the Hamburg Notation System and SignWriting, are phonetic scripts capable of writing any sign language. However, because they are not constrained by phonology, they do not yield a specific spelling for a sign. The SignWriting form, for example, will be different depending on whether the signer is left or right handed, despite the fact this makes no difference to the meaning of the sign.
Examples of phonemes in the English language would include sounds from the set of English consonants, like /p/ and /b/. These two are most often written consistently with one letter for each sound. However, phonemes might not be so apparent in written English, such as when they are typically represented with combined letters, called digraphs, like <sh> (pronounced /ʃ/) or <ch> (pronounced /tʃ/).
UKT: The aim of Romabama is to represent one phoneme by one grapheme, and I find it to replace the English diagraphs:
¤ <th> with the 'thorn' character of Old English <þ> for IPA /θ/
¤ <ny> with the Spanish <ñ> for IPA /nj/ .
The character <Ñ> is used to represent vertical conjunct {ñ~ña.} a concept not used in English.
To see a list of the phonemes in the English language, see IPA for English.
Two sounds that may be allophones (sound variants belonging to the same phoneme) in one language may belong to separate phonemes in another language or dialect. In English, for example, /p/ has aspirated [pʰ] and non-aspirated [p] allophones: aspirated as in <pin> /pɪn/ [pɪn], and non-aspirated as in <spin> /spɪn/ [spʰɪn] . [UKT ¶]
UKT: The last line has been rewritten by me with [...] to give the narrow phonetic representation showing the English allophones.
However, in many languages (e. g. Chinese [Burmese and most Indic languages]), aspirated /pʰ/ is a phoneme distinct from unaspirated /p/. As another example, there is no distinction between [r] and [l] in Japanese; there is only one /r/ phoneme, though it has various allophones that can sound more like [l], [ɾ], or [r] to English speakers. The sounds [z] and [s] are distinct phonemes in English, but allophones in Spanish. The sounds [n] (as in <run>) and [ŋ] (as in <rung>) are phonemes in English, but allophones in Italian and Spanish.
An important phoneme is the chroneme, a phonemically-relevant extension of the duration a consonant or vowel. Some languages or dialects such as Finnish or Japanese allow chronemes after both consonants and vowels. Others, like Australian English use it after only one (in the case of Australian, vowels).
A restricted phoneme is a phoneme that can only occur in
a certain environment: There are restrictions as to where it can occur.
English has several restricted phonemes:
• /ŋ/, as in <sing>, occurs only at the end of a syllable, never at the beginning (in many other languages, such as Swahili or Thai, /ŋ/ can appear word-initially).
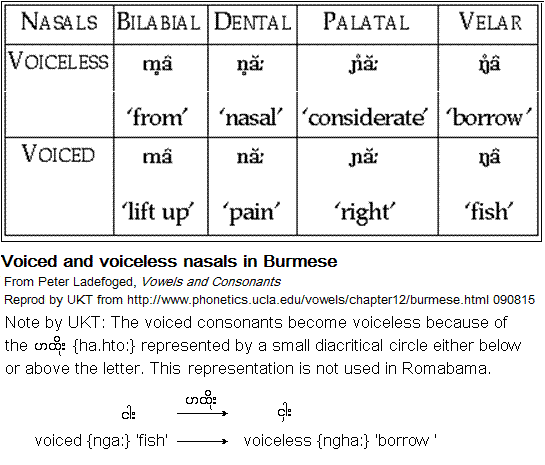
UKT:
{nga.} with the IPA sound /ŋ/ is a common occurrence in many Burmese-Myanmar words. It is a very prominent voiced velar-nasal stop consonant. In the onset position, it can occur before
{ha.} when it becomes voiceless as
{ngha.}
The{ha.hto:}. It then modifies the sound of the parent consonant and is called a medial. A medial, in every way, is like its parent consonant except that it cannot have its inherent vowel killed and thus could never be in the coda position. Peter Ladefoged shows the function of the {ha.hto:} in his Vowels and Consonants http://www.phonetics.ucla.edu/vowels/chapter12/burmese.html 090815 .
If you are not a native Burmese-Myanmar speaker, you might get confused by Ladefoged's examples. While English have only two "tones" (short and long) Burmese has "three" (creak, modal, and emphatic). The examples for velar sounds by Ladefoged are for emphatic pitch-registers:
¤ voiced -
{nga:} 'fish' --> voiceless -
{ngha:} 'to borrow'
The examples for bilabial nasal are in creak register, but the examples for dental and palatal are in modal register.
Burmese-Myanmar nasals are all voiced. However, when conjoined to the medial former
See also: Devoicing, Aspiration and Nasality — Cases of Universal Misunderstanding?
by Katherine Morton and Mark Tatham, Reproduced from Occasional Papers 23, Department of Language and Linguistics, University of Essex, UK, April 1980, 90–103. Copyright © 1980 Kate Morton and Mark Tatham — this version Copyright © 1997 Kate Morton and Mark Tatham. http://www.morton-tatham.co.uk/publications/to_1994/devoicing, aspiration and nasality.pdf 090816• /h/ occurs only before vowels and at the beginning of a syllable, never at the end (a few languages, such as Arabic, or Romanian allow /h/ syllable-finally).
UKT: What is Burmese-Myanmar
Burmese-Myanmar "/h/ occurs only before vowels and at the beginning of a syllable, never at the end". One common word that has been incorporated into Burmese-Myanmar{groh} 'astrological planet' is from Pali-Myanmar. However, according to my friend U Tun Tint of MLC, killed-{ha.} was common in Burmese in Pagan era after Anawratha expelled the Ari monks and introduced the Theravada Buddhism from the Mon kingdom of Thaton. This, I think, is to be expected because Pali is the language of Theravada Buddhism. The Aris in all probability because of the direct route to northern India would be more familiar with Magadhi.
• In many American dialects with the cot-caught merger, /ɔ/ occurs only before /r/, /l/, and in the diphthong /ɔɪ/.
• In non-rhotic dialects, /r/ can only occur before a vowel, never at the end of a word or before a consonant.
• Under most interpretations, /w/ and /j/ occur only before a vowel, never at the end of a syllable. However, many phonologists interpret a word like <boy> as either /bɔɪ/ or /bɔj/.
Biuniqueness is a criterial definition of the phoneme in classic structuralist phonemics. The biuniqueness definition states that every phonetic allophone must unambiguously be assigned to one and only one phoneme. In other words, there is a many-to-one allophone-to-phoneme mapping instead of a many-to-many mapping.
The notion of biuniqueness was controversial among some pre-generative linguists and was prominently challenged by Morris Halle and Noam Chomsky in the late 1950s and early 1960s.
The unworkable aspects of the concept soon become apparent if you consider sound changes/alternations and assimilation/co-articulation. Take English for its examples. If many vowels reduce to a 'schwa' /ə/, what is 'schwa' then? Its own phoneme? Or totally unrelated allophones, only grouped under the phonemic vowels? Or both?
Phonemes that are contrastive in certain environments may not be contrastive in all environments. In the environments where they don't contrast, the contrast is said to be neutralized.
In English there are three nasal phonemes, /m, n, ŋ/, as shown by the minimal triplet,
/sʌm/ <sum>
/sʌn/ <sun>
/sʌŋ/ <sung>UKT - need to consult with my Burmese-Myanmar peers for my following observations:
• In order to compare English with Burmese-Myanmar we will take only the rimes:
1. from <sung>, we get velar: {ûng}- not allowed
2. ___________ , _____ palatal: {ûñ}/{ûÑ}/
- not allowed
3. ___________ , _____ retroflex: {ûN}allowed ?
4. from <sun> , we get dental: {ûn}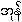
5. from <sum>, we get bilabial: {ûm}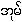
In the above 5 instances I just change the English vowel <u> to Romabama {û} and try to pronounce the resultant according to Burmese-Myanmar rules of spelling with which as a native Burmese-Myanmar speaker I am familiar. In all five instances we do not get the pronunciations of <sung>, <sun>, <sum>.
• To get near the English pronunciations, we just have to nasalize using the {thé:thé:ting}:
1. from <ung>, we get velar: {ngän}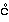
2a. __________ , _____ palatal: {ñän}not allowed: do not get confused with OÄN
the equivalent of Devanagari ॐ Om
2b. __________ , _____ palatal: {Ñän}
3. ___________ , _____ retroflex: {Nän}allowed but not known in Burmese
4. from <un> , we get dental: {nän}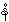
5. from <um>, we get bilabial: {män}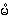
• To get more closer to the English pronunciations, we have to use other means, such as changing the peak vowel /ʌ/, which we will not try for the present.
However, with rare exceptions, [/sʌm/, /sʌn/, /sʌŋ/] these sounds are not contrastive before plosives such as /p, t, k/ within the same morpheme. Although all three phones appear before plosives, for example in <limp>, <lint>, <link>, only one of these may appear before each of the plosives. That is, the /m, n, ŋ/ distinction is neutralized before each of the plosives /p, t, k/:
• Only /m/ occurs before /p/,
• only /n/ before /t/, and
• only /ŋ/ before /k/.UKT: The explanation is simple if we note that in each of the above cases the phonemes belong to the same POA:
¤ /m/ and /p/ - bilabial
¤ /n/ and /t/ - alveolar
¤ /ŋ/ and /k/ - velar
Thus these phonemes are not contrastive in these environments, and according to some theorists, there is no evidence as to what the underlying representation might be. If we hypothesize that we are dealing with only a single underlying nasal, there is no reason to pick one of the three phonemes /m, n, ŋ/ over the other two.
(In some languages there is only one phonemic nasal anywhere, and due to obligatory assimilation, it surfaces as [m, n, ŋ] in just these environments, so this idea is not as far-fetched as it might seem at first glance.)
In certain schools of phonology, such a neutralized distinction is known as an archiphoneme (Nikolai Trubetzkoy of the Prague school is often associated with this analysis). Archiphonemes are often notated with a capital letter. Following this convention, the neutralization of /m, n, ŋ/ before /p, t, k/ could be notated as |N|, and limp, lint, link would be represented as |lɪNp, lɪNt, lɪNk|. (The |pipes| indicate underlying representation.) Other ways this archiphoneme could be notated are |m-n-ŋ|, {m, n, ŋ}, or |n*|.
Another example from American English is the neutralization of the plosives /t, d/ following a stressed syllable. Phonetically, both are realized in this position as [ɾ], a voiced alveolar flap. This can be heard by comparing writer with rider (for the sake of simplicity, Canadian raising is not taken into account).
[ɹaɪˀt] <write>
[ɹaɪd] <ride>
with the suffix -er:
[ˈɹaɪɾɚ] <writer>
[ˈɹaɪɾɚ] <rider>
Thus, one cannot say whether the underlying representation of the intervocalic consonant in either word is /t/ or /d/ without looking at the unsuffixed form. This neutralization can be represented as an archiphoneme |D|, in which case the underlying representation of writer or rider could be |ˈɹaɪDɚ|.
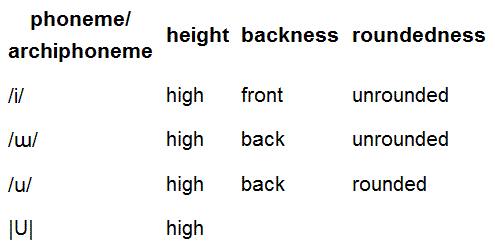
Another way to talk about archiphonemes involves the concept of underspecification: phonemes can be considered fully specified segments while archiphonemes are underspecified segments. In Tuvan, phonemic vowels are specified with the articulatory features of tongue height, backness, and lip rounding. The archiphoneme |U| is an underspecified high vowel where only the tongue height is specified.
Whether |U| is pronounced as front or back and whether rounded or unrounded depends on vowel harmony. If |U| occurs following a front unrounded vowel, it will be pronounced as the phoneme /i/; if following a back unrounded vowel, it will be as an /ɯ/; and if following a back rounded vowel, it will be an /u/. This can been seen in the following words:
Not all phonologists accept the concept of archiphonemes. Many doubt that it reflects how people process language or control speech, and some argue that archiphonemes add unnecessary complexity.
Of all the sounds that a human vocal tract can create, different languages vary considerably in the number of these sounds that are considered to be distinctive phonemes in the speech of that language. [UKT ¶ ]
Ubyx and Arrernte have only two phonemic vowels, while at the other extreme, the Bantu language Ngwe has fourteen vowel qualities, twelve of which may occur long or short, for twenty-six oral vowels, plus six nasalized vowels, long and short, for thirty-eight vowels; while !Xóõ achieves thirty-one pure vowels — not counting vowel length, which it also has — by varying the phonation. Rotokas has only six consonants, while !Xóõ has somewhere in the neighborhood of seventy-seven, and Ubyx eighty-one. [UKT ¶ ]
French has no phonemic tone or stress, while several of the Kam-Sui languages have nine tones, and one of the Kru languages, Wobe, has been claimed to have fourteen, though this is disputed. The total phonemic inventory in languages varies from as few as eleven in Rotokas to as many as 112 in !Xóõ (including four tones). These may range from familiar sounds like [t], [s], or [m] to very unusual ones produced in extraordinary ways (see: Click consonant, phonation, airstream mechanism). [UKT ¶ ]
The English language itself uses a rather large set of thirteen to twenty-two vowels, including diphthongs, though its twenty-two to twenty-six consonants are close to average. (There are twenty-one consonant and five vowel letters [graphemes] in the English alphabet, but this does not correspond to the number of consonant and vowel sounds.)
The most common vowel system consists of the five vowels /i/, /e/, /a/, /o/, /u/. The most common consonants are /p/, /t/, /k/, /m/, /n/. Very few languages lack one of these: Arabic lacks /p/, standard Hawaiian lacks /t/, Mohawk and Tlingit lack /p/ and /m/, Hupa lacks both /p/ and a simple /k/, colloquial Samoan lacks /t/ and /n/, while Rotokas and Quileute lack /m/ and /n/.
UKT: End of Wikipedia article.
Go back phoneme-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Phonemic_principle 090825
Redirected from: Phonemic principle
A phonemic orthography is a writing system where the written graphemes correspond to phonemes, the spoken sounds of the language. These are sometimes termed true alphabets, but non-alphabetic writing systems like syllabaries can be phonemic as well.
Scripts with a good grapheme-to-phoneme correspondence include those of Albanian, Armenian, Bulgarian, Basque, Czech, Estonian, Finnish, Georgian, Hungarian, Macedonian, Polish, Romanian, Sanskrit, Turkish, Croatian, and Serbian. Most constructed languages such as Esperanto and Lojban have phonemic orthographies.
As dialects of the English language vary significantly, it would be difficult to create a phonemic orthography that encompassed all of them. However, it is fairly easy to create one based on a standard accent such as Received Pronunciation [RP]. This would, however, exclude certain sound differences found in other accents, such as the bad-lad split in Australian English. With time, pronunciations change and spellings become out of date, as has happened to English and French. In order to maintain a phonemic orthography such a system would need periodic updating, as has been attempted by various language regulators and proposed by other spelling reformers.
Phonemic orthography in a language is affected by the borrowing of loanwords from another written in the same alphabet but having different sound-to-spelling conventions. If the original spelling and pronunciation are both kept, then the spelling is "irregular": for example, fajita is pronounced < title="Representation in the International Phonetic Alphabet (IPA)"> /fəˈhiːtə/ to reflect the Spanish pronunciation of < title="Representation in the International Phonetic Alphabet (IPA)"> /faˈxita/, rather than < title="Representation in the International Phonetic Alphabet (IPA)"> /fəˈdʒaɪtə/ as the spelling would suggest under normal English spelling rules. Phonemicity may be preserved by nativizing the loanword's pronunciation as with the Russian word шофёр (from French chauffeur) which is pronounced < title="Representation in the International Phonetic Alphabet (IPA)"> [ʂɐˈfʲor] in accordance with the normal rules of Russian vowel reduction. Spelling pronunciation is another common phenomenon. Nativizing the spelling of loanwords is also common; for example, uísque is the Portuguese spelling of whisky, itself a respelling of Scots Gaelic uisge.
Methods for phonetic transcription such as the International Phonetic Alphabet (IPA) aim to describe pronunciation in a standard form. They are often used to solve ambiguities in the spelling of written language. They may also be used to write languages with no previous written form. Systems like IPA can be used for phonemic representation or for showing more detailed phonetic information (see Narrow vs. broad transcription).
Phonemic orthographies are different from phonetic transcription; whereas in a phonemic orthography, allophones will usually be represented by the same grapheme, a purely phonetic script would demand that phonetically distinct allophones be distinguished. To take an example from American English: the < title="Representation in the International Phonetic Alphabet (IPA)"> /t/ sound in the words <table> and <cat> would, in a phonemic orthography, be written with the same character; however, a strictly phonetic script would make a distinction between the aspirated "t" in <table>, the flap in <butter>, the unaspirated "t" in <stop> and the glottalized "t" in <cat> (not all these allophones exist in all English dialects). In other words, the sound that most English speakers think of as /t/ is really a group of sounds, all pronounced slightly differently depending on where they occur in a word. A perfect phonemic orthography has one letter per group of sounds (phoneme), with different letters only where the sounds distinguish words (so "bed" is spelled differently from "bet").
A narrow phonetic transcription represents phones, the atomic sounds humans are capable of producing, many of which will often be grouped together as a single phoneme in any given natural language, though the groupings vary across languages. English, for example, does not distinguish between aspirated and unaspirated consonants, but other languages, like Bengali and Hindi, do. [Burmese-Myanmar as well.]
UKT: End of Wikipedia article.
Go back phon-ortho-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Phonetics 090825
Phonetics (from the Greek: φωνή, phōnē, "sound, voice") is a branch of linguistics that comprises the study of the sounds of human speech.[1] It is concerned with the physical properties of speech sounds (phones), and the processes of their physiological production, auditory reception, and neurophysiological perception.
Phonetics was studied as early as 2500 years ago in ancient India, with Pāṇini's account of the place and manner of articulation of consonants in his 5th century BC treatise on Sanskrit. The major Indic alphabets today [including Burmese-Myanmar] order their consonants according to Pāṇini's classification.
Phonetic transcription is a universal system for transcribing sounds that occur in spoken language. The most widely known system of phonetic transcription, the International Phonetic Alphabet (IPA), uses a one-to-one mapping between phones and written symbols.[2][3] The standardized nature of the IPA enables its users to transcribe accurately and consistently between different languages.[2][4][5] It can also indicate common pronunciations of words (e.g. [ðɪs] for the word <this>).
Phonetics as a research discipline has three main branches:
• articulatory phonetics is concerned with the articulation of speech: The position, shape, and movement of articulators or speech organs, such as the lips, tongue, and vocal folds.
• acoustic phonetics is concerned with acoustics of speech: The properties of the sound waves, such as their frequency and harmonics.
• auditory phonetics is concerned with speech perception: How sound is received by the inner ear and perceived by the brain.
Application of phonetics include:
• forensic phonetics: the use of phonetics (the science of speech) for forensic (legal) purposes.
• Speech Recognition: the analysis and transcription of recorded speech by a computer system.
In contrast to phonetics, phonology is the study of language-specific systems and patterns of sound and gesture, relating such concerns with other levels and aspects of language. While phonology is grounded in phonetics, it has emerged as a distinct area of linguistics, dealing with abstract systems of sounds and gestural units (e.g, phoneme, features, mora, etc.) and their variants (e.g., allophones), the distinctive properties (features) which form the basis of meaningful contrast between these units, and their classification into natural classes based on shared behavior and phonological processes. Phonetics tends to deal more with the physical properties of sounds and the physiological aspects of speech production and perception. It deals less with how sounds are patterned to encode meaning in language (though overlap in theorizing, research and clinical applications are possible).
UKT: End of Wikipedia article.
Go back phonetics-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Shiva_Sutra 090903
The Shiva Sutras (śivasūtrāṇi; शिवसूत्राणि) or Maheshvara Sutras ( महेश्वराणि सूत्राणि) are fourteen verses that organize the phonemes of the Sanskrit language as referred to in the Aṣṭādhyāyī of Pāṇini, the foundational text of Sanskrit grammar. Within the tradition they are known as the akṣarasamāmnāya, "recitation of phonemes," but they are popularly known as the Shiva Sutras because they are said to have been revealed to Pāṇini by Shiva (also known as Maheshvara). They were either composed by Pāṇini to accompany his Aṣṭādhyāyī or predate him. The latter is less plausible, but the practice of encoding complex rules in short, mnemonic verses is typical of the sutra style.

Each verse consists of Sanskrit phonemes followed by a single 'dummy letter' or anubandha, conventionally rendered by capital letters in Roman transliteration. This allows Pāṇini to refer to groups of phonemes with pratyāhāras, which consist of a phoneme-letter and an anubandha (and often the vowel a to aid pronunciation) and signify all of the intervening phonemes Pratyāhāras are thus single syllables, but they can be declined (see Aṣṭādhyāyī 6.1.77 below). Hence aL refers to all phonemes (because it consists of the first phoneme a and the last anubandha L); aC refers to vowels (i.e., all of the phonemes before the anubandha C: a i u ṛ ḷ e o ai au); haL to consonants, and so on. Note that some pratyāhāras are ambiguous. The anubandha Ṇ occurs twice in the list, which means that you can assign two different meanings to pratyāhāra aṆ (including or excluding ṛ, etc.); in fact, both of these meanings are used in the Aṣṭādhyāyī. On the other hand, the pratyāhāra haL is always used in the meaning "all consonants" --- Pāṇini never uses pratyāhāras to refer to sets consisting of a single phoneme.
From these 14 verses, a total of 281 pratyāhāras can be formed: 14*3 + 13*2 + 12*2 + 11*2 + 10*4 + 9*1 + 8*5 + 7*2 + 6*3 * 5*5 + 4*8 + 3*2 + 2*3 +1*1, minus 14 (as Pāṇini does not use single element pratyāhāras) minus 10 (as there are 10 duplicate sets due to h appearing twice); the second multiplier in each term represents the number of phonemes in each. But Pāṇini uses only 41 (with a 42nd introduced by later grammarians, raṆ=r l) pratyāhāras in the Aṣṭādhyāyī.
The Shiva Sutras put phonemes with a similar manner of articulation together (so sibilants in 13 śa ṣa sa R, nasals in 7 ñ m ṅ ṇ n M). Economy (Sanskrit: lāghava) is a major principle of their organization, and it is debated whether Pāṇini deliberately encoded phonological patterns in them (as they were treated in traditional phonetic texts called Prātiśakyas) or simply grouped together phonemes which he needed to refer to in the Aṣṭādhyāyī and which only secondarily reflect phonological patterns (as argued by Paul Kiparsky and Wiebke Petersen, for example). Pāṇini does not use the Shiva Sutras to refer to homorganic stops (stop consonants produced at the same place of articulation), but rather the anubandha U : to refer to the palatals c ch j jh he uses cU.
As an example, consider Aṣṭādhyāyī 6.1.77: iKo yaṆ aCi. iK refers to the phonemes i u ṛ ḷ, and is in the genitive case, which in the Aṣṭādhyāyī marks a string to be substituted; aC refers to vowels, as noted above, and is in the locative case, which marks the left-hand context for an operation. yaṆ refers to the semivowels y v r and l and is in the nominative, which marks a substitution. Hence this rule replaces a vowel with its corresponding semivowel when preceded by another vowel.
UKT: End of Wikipedia article.
Go back Shiv-Sutra-note-b
End of TIL file