

human-snd.htm
by U Kyaw Tun (UKT) (M.S., I.P.S.T., USA) and staff of Tun Institute of Learning (TIL) . Not for sale. No copyright. Free for everyone. Prepared for students and staff of TIL Research Station, Yangon, MYANMAR : http://www.tuninst.net , www.romabama.blogspot.com
Human sound production
Hearing vs. seeing
Resonators and vocal resonation : addition 130816
Nasality
Normal resonance and
velopharyngeal function
Ancient phoneticians - Panini in India
Graphical representation of the human speech
Hissers and Hushers - the true fricatives
Passages worthy of note:
•
Nasality is above all else an auditory
phenomenon (that is, the way you hear) and
not primarily an articulatory one able to be
specified in terms of the position of the
velum.
• In reality,
the velum does not move like a hinged trap door
but is only the anterior part of a complex velopharyngeal
valve which functions as a circular sphincter.
• It has been demonstrated electrographically in
the form of "
voice-prints"
that, like fingerprints, no two voices are exactly
alike.
• Panini should
be thought of as the forerunner of the modern formal
language theory used to specify computer languages.
The Backus Normal Form was discovered independently by
John Backus (1924-2007) in 1959, but Panini's notation
is equivalent in its power to that of Backus and has
many similar properties. It is remarkable to think that
concepts which are fundamental to today's theoretical
computer science should have their origin with an
Indian genius around 2500 years ago.
UKT note
•
acoustic phonetics
•
articulatory phonetics
• formant
• grapheme
• Panini
• phonotactics
• Quintilian
• rhoticity
• sagittal plane
•
speech machine model
• thorn
- UKT 180712
Humans are endowed with the ability to speak, and speech comes naturally to us. Because of this, we do not value our ability to speak until we lose it due to disease or injury. All of us know how frustrated we are when suffering a common cold and unable to convey even a short message.
The ancients of the Indian subcontinent, including
those of the mainland Myanmarpré had personified
the human speech (and its representation - especially
of religious nature) as a Mother-goddess Saraswati
![]() {þu-raþ~þa.ti mèý-tau}.
{þu-raþ~þa.ti mèý-tau}.
Because speech flows out of the mouth from its source
in the lungs, it can be likened to a stream of water.
We associate speech with flowing water, and Saraswati
with a river. Lets see in this series how the human
body produce the speech that differentiates us from
the most intelligent of animals, apes and dolphins.
See in my note on
articulatory phonetics .
After listening to a noted Myanmar Buddhist monk in
a sermon, objecting to the term "Caretaker of
Tipitaka" as is usually applied to Saraswati
![]() {þu-raþ~þa.ti mèý-tau} in Myanmarpré, I have decided
to refer to her as the Goddess of Speech.
{þu-raþ~þa.ti mèý-tau} in Myanmarpré, I have decided
to refer to her as the Goddess of Speech.
When did the humans or pre-humans learn to speak
that came to separate them from their ape-like
cousins? Read
#1. Evolutionary Psychology and the Origins of
Language (editorial for the special issue of
Journal of Evolutionary Psychology on the
evolution of language), by Thomas C. Scott-Phillips,
2010:
-
TCScottPhillips-EvolvPsychoOriginLang<Ô> /
Bkp<Ô> (link chk 180712)
#2. Natural Language and Natural Selection,
by Steven Pinker and Paul Bloom, 1990
-
SPinkerPBloom-NatLangNatSelect<Ô> /
Bkp<Ô> (link chk 180715)
Lets see what Charles Darwin thought:
"It [language] certainly is not a true instinct, for every language has to be learned. It differs, however, widely from all ordinary arts, for man has an instinctive tendency to speak, as we see in the babble of our young children; while no child has an instinctive tendency to brew, bake, or write. Moreover, no philologist now supposes that any language has been deliberately invented; it has been slowly and unconsciously developed by many steps." - Charles Darwin (1874, pp. 88-89) cited in Without Miracles, 11. The Evolution, Acquisition, and Use of Language. http://faculty.ed.uiuc.edu/g-cziko/wm/11.html#fn0 101101
UKT 180713: Unfortunately about half my collection, which had included Without Miracles is now lost due to computer failures and the misplacement backups.

 We know that sound can be produced by vibrating strings
such as guitar strings and vibrating surfaces such as
drum heads. We also know that the flow of air from the
lungs through the vocal tract -- the oral and the nasal
channels -- also produces sound. And so there must be
organs similar to the vibrating strings and vibrating
surfaces in the vocal tract to produce sound. If that
sound carries information for interspecies communication,
it could be called a language or speech.
We know that sound can be produced by vibrating strings
such as guitar strings and vibrating surfaces such as
drum heads. We also know that the flow of air from the
lungs through the vocal tract -- the oral and the nasal
channels -- also produces sound. And so there must be
organs similar to the vibrating strings and vibrating
surfaces in the vocal tract to produce sound. If that
sound carries information for interspecies communication,
it could be called a language or speech.
Both man and animal make information-carrying sounds. But for that information-carrying sound to be really called a "language" or speech, it must have syntax. If not, the information-carrying sound, such as that used by the chimpanzee and the dolphin -- the most highly developed animals on land and water -- remains calls, not language.
Another point of difference may be ability to ask questions in a human language. The answer may be "yes" or "no", or an indirect answer amounting to "no". The second way of saying can be exemplified by:
Husband to wife late in the evening: "Honey, would you like to have a piece of cake?
Wife to husband: "I've already brushed my teeth".
We cannot imagine how animals can question each other with calls.
We may normally first think of language as a tool
for communication among individuals, but it also
appears to be used silently as a medium of thought.
Although its specific role in facilitating and
shaping our thought processes remains the subject
of lively debate among scholars, the subjective
experience of being human suggests that language
plays an important role in human cognition and
consciousness.
See Berk (1994) [ cited in Without
Miracles, 11. The Evolution, Acquisition,
and Use of Language.
-
http://faculty.ed.uiuc.edu/g-cziko/wm/11.html#fn0
101101]
for an account of how the private, self-directed
speech of the child gradually turns into the silent
thoughts of the adult.
It is unfortunate that speech has been loosely termed "language". Since all humans speak one way or another for interspecies communication there is no such thing as "the oldest language". What is generally meant by the term is when it was first recorded or represented in durable markings. These "markings" constitute script. Thus instead of saying Burmese language, we should specify it as the Burmese speech usually represented in Myanmar script - in short Burmese-Myanmar (Bur-Myan).
It is said that all human babies (except those born with defects) are born with the ability to articulate all human speech sounds. This ability remains up to about the age of 6 when they start to loose the ability to produce certain sounds alien to the language-group it is being brought up with. By the time of puberty, say age 12, he or she has lost all ability to produce the alien sounds, and could only speak the speech of only his or her language-group. The speech is now subject to its own phonotactics. Thus, a Hindi speaker became a sibilant speaker with hisser /s/ and husher /ʃ/ , and a Burmese speaker a thibilant speaker used to the sound of /θ/, whereas an English speaker is used to both sibilant and thibilant sounds.
UKT 180713: In the extreme case of a human child who had lost contact with other humans, and had lived with animals, such as a feral child, and had come back to the human society only after the onset of puberty, it loses its ability to speak any human language. See
- https://en.wikipedia.org/wiki/Feral_child 180713
See also The Child of Nature: The Feral Child and the State of Nature. A PhD Thesis by Michael Newton, University College, London, date of publication not given, in TIL HD-PDF and SD-PDF libraries:
- MNewton-FeralChild<Ô> / Bkp<Ô> (link chk 180715)
Some language groups speak with a highly rhotic accent, while others are able to speak only with some rhoticity. Even in a language group, say English-Latin, British speakers tend to speak with very little rhoticity whereas Americans tend to speak with a rhotic accent. The same can be said of Bur-Myan speakers: mainland speakers speak with very little rhoticity whilst those of the western coast - Rakhines - speak with a noticeable rhotic accent. However, their rhoticity is no match for those of Sanskrit speakers and Macedonian-Greek speakers.

 Up to now, we are looking at human speech from the speaker's side. What about
the hearer? If the speakers of different language-groups articulate the "same"
sound differently from speakers of other language-groups, then there is the
possibility that hearers of different groups would perceive the same sound
differently subject to the restraints set by his culture. Thus there is a
possibility that a Sanskrit phonetician such as Panini would "hear" the Magadhi
Up to now, we are looking at human speech from the speaker's side. What about
the hearer? If the speakers of different language-groups articulate the "same"
sound differently from speakers of other language-groups, then there is the
possibility that hearers of different groups would perceive the same sound
differently subject to the restraints set by his culture. Thus there is a
possibility that a Sanskrit phonetician such as Panini would "hear" the Magadhi
![]() {þa.}
as an /s/ and not /θ/. Thus, there is actually no way of knowing how Gautama
Buddha had pronounced his
{þa.}
as an /s/ and not /θ/. Thus, there is actually no way of knowing how Gautama
Buddha had pronounced his
![]() {þa.} -
as /s/ as in Pal-Latin, or, as /θ/ as in Pal-Myan. Coming back to modern times,
we can now study the human speech using instruments instead of human
phoneticians. See in my notes on
Acoustic
Phonetics .
{þa.} -
as /s/ as in Pal-Latin, or, as /θ/ as in Pal-Myan. Coming back to modern times,
we can now study the human speech using instruments instead of human
phoneticians. See in my notes on
Acoustic
Phonetics .
 Thus, when I realized that in trying to come up with a system of
transcription-transliteration between Burmese and English, relying on
pronunciation would lead me to a quagmire, I decided to start with
transliteration relying on the fact that Bur-Myan script is phonemic. It could
easily be related to IPA rather than to regular non-phonetic English-Latin. The
system that I have developed, Romabama
Thus, when I realized that in trying to come up with a system of
transcription-transliteration between Burmese and English, relying on
pronunciation would lead me to a quagmire, I decided to start with
transliteration relying on the fact that Bur-Myan script is phonemic. It could
easily be related to IPA rather than to regular non-phonetic English-Latin. The
system that I have developed, Romabama
![]() {ro:ma.ba.ma} 'Bur-Latin', is very formal and if you were to
pronounce a Bur-Myan word as is spelled in Romabama, you can come up with a
"pronunciation" which will sound like the Rakhine dialect, but would be
understood everywhere in Myanmar. I fine-tuned the Romabama orthography, until it
is now a transcription. However, it fails when applied to Mon-Myan which
uses a phonology unlike Bur-Myan.
{ro:ma.ba.ma} 'Bur-Latin', is very formal and if you were to
pronounce a Bur-Myan word as is spelled in Romabama, you can come up with a
"pronunciation" which will sound like the Rakhine dialect, but would be
understood everywhere in Myanmar. I fine-tuned the Romabama orthography, until it
is now a transcription. However, it fails when applied to Mon-Myan which
uses a phonology unlike Bur-Myan.
The first sounds that I must have heard while still in my mother's womb must
have been Burmese-Myanmar. These would also have been the first sounds I must
have heard as soon as I was born. So my first language (L1) would be Bur-Myan.
However, the doctor attending the delivery, my father's friend, was Dr. Gobra
Singh (I hope I've spelled his name right!). He was a Punjabi and he and my
father would have been speaking in English. Since, my mother and father spoke
sometimes in English, I must have also heard English sounds while I was still in
my mother's womb. So even though English is not my L1, it is almost L1. As a new
born child, I must have started to associate the voices of my mother, father,
and those around with their faces. And as each human speak with a unique pattern
even within a speech, I would have been able to identify the speaker from the
sound of his or her voice. So what kind of voice would be the easiest to
distinguish from others. My mother being a woman would have a kind of nasal
voice whilst my father being a man would have a sort of pharyngeal voice. It is
said that
![]() {yauk-kya: aa/ main:ma. nha//} - that man sing and speak with a pharyngeal
voice, and that woman sing and speak with a nasal voice. Most of the times, when
they are not frustrated (my mother used to say that I was a quiet child in the
first year - I rarely cried even when hungry. I was dubbed
{yauk-kya: aa/ main:ma. nha//} - that man sing and speak with a pharyngeal
voice, and that woman sing and speak with a nasal voice. Most of the times, when
they are not frustrated (my mother used to say that I was a quiet child in the
first year - I rarely cried even when hungry. I was dubbed
![]() {hpo:ré-hkè:} 'the ice child'*) the speakers would be speaking in normal voices
which are what could be called "modal".
{hpo:ré-hkè:} 'the ice child'*) the speakers would be speaking in normal voices
which are what could be called "modal".
• Mother's voice comparable to - nasal<))
• Father's voice comparable to - pharyngeal<))
• normal voice - modal<))
* After the first few years, I came to suffer from what might be called "heart
burns" - my innards seemed to be burning (almost about the same time every
morning just before noon for a few years - I was about 4-5) which I tried to
cool by drinking cold water to no avail, but being unable to express myself, I
cried a lot and came to earn the name
![]() {hpo:mi:hkè:} 'master cinder'. The remedy was a sound thrashing from my mother
which send me to sleep.
{hpo:mi:hkè:} 'master cinder'. The remedy was a sound thrashing from my mother
which send me to sleep.
![]() {hpo:mi:hkè:} was the alternate title of a short story titled "The Refuge" which
I wrote for the Guardian Magazine of Rangoon in the late 1950s or early 1960s.
{hpo:mi:hkè:} was the alternate title of a short story titled "The Refuge" which
I wrote for the Guardian Magazine of Rangoon in the late 1950s or early 1960s.
Soon after birth, the human baby could recognized the speaker probably by both the speaker's voice and appearance.
 A person's speech may be studied from two view points: 1. his language and
dialect, and 2. his idiolect and pronunciation. The first, his language and
dialect belongs to the domain of Phonetics and Phonology, whereas, the second,
to the domain of Oratory and Rhetoric.
A person's speech may be studied from two view points: 1. his language and
dialect, and 2. his idiolect and pronunciation. The first, his language and
dialect belongs to the domain of Phonetics and Phonology, whereas, the second,
to the domain of Oratory and Rhetoric.
"In his Institutes of
Oratory, Quintilian wrote that 'The voice
of a person is as easily distinguished by the ear
as the face by the eye' (c.III, Book XI). The importance
of an individual speaker's voice in everyday social
interaction, as an audible index of his identity,
personality and mood, could hardly be overstated.
Yet we know how only a little more about the factors
that give rise to different qualities of the voice
than Quintilian did." (John Laver, Introduction,
The Phonetic Description of Voice Quality, 1980,
p001.)
See in my note on Institutes of Oratory, by Quintilian.
Of all the voices, it is probably the easiest to contrast the nasal from the pharyngeal. Even among grownups we instantly note whether a speaker is suffering from common cold or not by noting the nasality in his or her voice.
Nasality is above all else an auditory phenomenon (that is, the way you hear) and not primarily an articulatory one able to be specified in terms of the position of the velum. See Felicity Cox, The Acoustic Characteristics of Nasals, Consonant Acoustics, in Speech Science Resource Pages, Macquarie Univ., Australia, http://clas.mq.edu.au/speech/acoustics/consonants/nasalweb.html 071115, 101104
Nasality is a special condition of resonance. In nasal voice, when the velum is lowered due to palatoglossus activity (palatoglossus muscle connects the tongue and the velum)) there is often the added perception of velarisation due to tongue being raised and retracted.
When the palatopharyngeus contracts it influences the mode of vibration of the vocal folds as the larynx may be pulled up thereby stretching the folds causing an increase in F0. (See elsewhere on Formant - Any of several frequency regions of relatively great intensity in a sound spectrum.) Raising the larynx also has the effect of shortening the vocal tract and therefore changing the resonatory characteristics.
UKT 130816: Now that we have mentioned "resonatory characteristics", we must know what are the resonators that are responsible for these characteristics.
In reality, the velum does not move like a hinged trap door but is only the anterior part of a complex velopharyngeal valve which functions as a circular sphincter.
Palatal elevation occurs but there is also movement of the back wall of the pharynx towards the front and in some speakers a structure known as Passavant's pad, a muscular bar or cushion on the back wall of the nasopharynx at the point where it is touched by the lifted velum.
(Velum closure is primarily effected by the palatal tensor, the palatal levator, the superior pharyngeal constrictor).
- UKT 130816
The Wikipedia article given below is directed to a singer: "The objective is to have command of all the colors of the spectrum, which allows you, the artist, greater scope of emotional expression." If you are a linguist, keep this in mind as you go along reading it.Excerpts from Wikipedia: http://en.wikipedia.org/wiki/Vocal_resonation 130816
McKinney defines Vocal resonance as "the process by which the basic product of phonation is enhanced in timbre and/or intensity by the air-filled cavities through which it passes on its way to the outside air." [1] Throughout the vocal literature, various terms related to resonation are used, including: amplification, enrichment, enlargement, improvement, intensification, and prolongation. Acoustic authorities would question many of these terms from a strictly scientific perspective. However, the main point to be drawn from these terms by a singer or speaker is that the result of resonation is to make a better sound.
The voice, like all acoustic instruments such as the guitar, trumpet, piano, or violin, has its own special chambers for resonating the tone. Once the tone is produced by the vibrating vocal cords, it vibrates in and through the open resonating chambers, activating the four primary colors (resonances):
1. chest,
2. mouth,
3. nasal (or mask) and
4. head.
Think of the various resonances as vocal colors in a continuous spectrum, from dark or chest resonance to bright or head/nasal resonance. We may call this spectrum a resonance track. In the lower range, the chest resonance or dark color predominates; in the middle range, the mouth-nasal resonance is dominant; in the higher range, the head-nasal resonance (bright color) predominates. The objective is to have command of all the colors of the spectrum, which allows you, the artist, greater scope of emotional expression. The emotional content of the lyric or phrase suggests the color and volume of the tone and is the personal choice of the artist.
HEAD RESONANCE should not be confused with head register or falsetto. It is used primarily for softer singing in either register throughout the range.
MOUTH RESONANCE is used for a conversational vocal color in singing and, in combination with nasal resonance, it creates forward placement or mask resonance.
CHEST RESONANCE adds richer, darker, deeper tone coloring for a sense of power, warmth and sensuality. It creates a feeling of depth and drama in the voice.
NASAL or MASK RESONANCE is present at all times in a well-produced tone, except, perhaps, in the instance of the pure head tone or at very soft volume. Nasal resonance is bright and edgy and is used in combination with mouth resonance to create forward placement (mask resonance). In an over-all sense, it adds overtones that give clarity and projection to the voice.
There are some singers who are recognized by their pronounced nasal quality and others noted for a deep, dark and chesty sound and still others for their breathy or heady sound ... and so on. In part, such individuality depends on the structure of the singer's vocal instrument, that is, the inherent shape and size of the vocal cords and resonating chambers.
The quality or color of your voice also depends on your ability to develop and use various resonances by controlling the shape and size of the chambers through which the sound flows. It has been demonstrated electrographically in the form of " voice-prints" that, like fingerprints, no two voices are exactly alike. [2]
There are a number of factors which determine the resonance characteristics of a resonator. Included among them are the following: size, shape, type of opening, composition and thickness of the walls, surface, and combined resonators. The quality of a sound can be appreciably changed by rather small variations in these conditioning factors. [6]
In general, the larger a resonator is, the lower the frequency it will respond to; the greater the volume of air, the lower its pitch. But the pitch also will be affected by the shape of resonator and by the size of opening and amount of lip or neck the resonator has. [3]
... ... ...

There are seven areas that may be listed as possible vocal resonators. In sequence from the lowest within the body to the highest, these areas are the chest, the tracheal tree, the larynx itself, the pharynx, the oral cavity, the nasal cavity, and the sinuses. [6]
 The chest is not an effective resonator.
Although strong vibratory sensations may
be experienced in the upper chest, and
although numerous voice books refer to
chest resonance, the chest, by virtue of
its design and location, can make no
significant contribution to the resonance
system of the voice. The chest is on the
wrong side of the vocal folds and there is
nothing in the design of the lungs that
could serve to reflect sound waves back
toward the larynx.
[3]
The chest is not an effective resonator.
Although strong vibratory sensations may
be experienced in the upper chest, and
although numerous voice books refer to
chest resonance, the chest, by virtue of
its design and location, can make no
significant contribution to the resonance
system of the voice. The chest is on the
wrong side of the vocal folds and there is
nothing in the design of the lungs that
could serve to reflect sound waves back
toward the larynx.
[3]
The tracheal tree makes significant contribution to the resonance system except for a negative effect around its resonant frequency. The trachea and the bronchial tubes combine to form an inverted Y-shaped structure known as the tracheal tree. It lies just below the larynx, and, unlike the interior of the lungs, has a definite tubular shape and comparatively hard surfaces. The response of the tracheal tree is the same for all pitches except for its own resonant frequency. When this resonant frequency is reached, the response of the subglottic tube is to act as an acoustical impedance or interference which tends to upset the phonatory function of the larynx. Research has placed the resonant frequency of the subglottal system or tracheal tree around the E-flat above "middle C" for both men and women, varying somewhat with the size of the individual. [7]
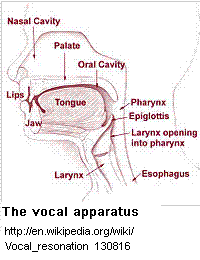 Due to its small size, the larynx acts
as a resonator only for high frequencies.
Research indicates that one of the
desirable attributes of good vocal tone
is a prominent overtone lying between
2800 and 3200 hertz, with male voices
nearer the lower limit and female voices
nearer the upper. This attribute is
identified as brilliance, or more
frequently as ring or the
singer's formant. There are
several areas in or adjacent to the
larynx which might resonate such a
high pitch. Among them are the collar
of the larynx, the ventricles of Morgani,
the vallecula, and the pyriform sinuses.
The larynx is not under conscious control,
but whatever produces "ring"
can be encouraged indirectly by
awareness on the part of the student
and the teacher of the sounds which
contain it.
Due to its small size, the larynx acts
as a resonator only for high frequencies.
Research indicates that one of the
desirable attributes of good vocal tone
is a prominent overtone lying between
2800 and 3200 hertz, with male voices
nearer the lower limit and female voices
nearer the upper. This attribute is
identified as brilliance, or more
frequently as ring or the
singer's formant. There are
several areas in or adjacent to the
larynx which might resonate such a
high pitch. Among them are the collar
of the larynx, the ventricles of Morgani,
the vallecula, and the pyriform sinuses.
The larynx is not under conscious control,
but whatever produces "ring"
can be encouraged indirectly by
awareness on the part of the student
and the teacher of the sounds which
contain it.
The pharynx is the most important resonator by virtue of its position, size, and degree of adjustability. It is the first cavity of any size through which the product of the laryngeal vibrator passes; the other supraglottal cavities have to accept whatever the pharynx passes on to them. Greene states:
"The supraglottic resonators being in the main muscular and moveable structures must be voluntarily controlled to produce conditions of optimal resonance either by varying degrees of tension in their walls, or by alterations in the size of their orifices and cavities during the articulatory movements."
The oral cavity is the second most effective resonator.
The nasal cavity is the third most effective resonator.
The sinuses are extremely important to voice modulation.
UKT: End of Wikipedia article.
UKT: This subsection has materials from Wikipedia http://en.wikipedia.org/wiki/Nasal_vowel 070908
See also Velopharyngeal settings in The Phonetic Description of Voice quality, by John Laver, Univ. of Edinburgh, Cambridge Univ. Press, 1980, p068. In particular, see p077-092. My html version of Laver's book is available in TIL library.UKT: It is said of the traditional Burmese-Myanmar singing:
{yauk~kya: a / maim:ma. nha//} meaning "male singing comes from throat; female from nose."
"The velopharyngeal settings describes the position of the velum which in its neutral setting facilitates nasality only on certain segments. The other (open or closed) position of the velum during the production of speech segments is regarded as the specific (nasalized or denasalized) setting. The coupling of the nasal resonator dramatically changes the spectral characteristics of the vocal tract. Additional formants and antiformants are produced while the high frequency components are suppressed.Now listen to nasalized voice nasal<)) to contrast it from pharyngealized voice pharyngeal<))
[from: http://www.ims.uni-stuttgart.de/phonetik/EGG/page11.htm - link chk 130816
As with consonants, air may or may not be flowing through the nose, regardless of what the tongue or lips may be doing. Vowels tend to be oral, but many languages also have a set of nasal vowels (e.g., French). English has a few environments where vowels may be (non-contrastively) nasalized. Nasal vowels are produced with a lowering of the soft palate (velum) so that air escapes both through nose as well as the mouth. The term stands in opposition to the term "oral vowel" refers to an ordinary vowel without this nasalisation. Note that these terms can be slightly misleading as the air does not come exclusively out of the nose in nasal vowels.
In most languages, vowels that are adjacent to nasal consonants are produced partially or fully with a lowered velum in a natural process of assimilation and are therefore technically nasal, though few speakers would notice. This is the case in English: vowels preceding nasal consonants are nasalized, but there is no phonemic distinction between nasal and oral vowels (and all vowels are considered phonemically oral). However, the word "huh" is generally pronounced with a nasal vowel.
UKT: Nasals are: English-Latin <ng, n, m>, and Burmese-Myanmar {nga., Ña./ña., Na., na., ma.}. In Burmese-Myanmar, the inherent vowel is hidden and there is no problem of assimilation. However, in Romabama because we are using the Latin alphabet in the same way as English, we need to show the peak vowel, V, of the CVÇ syllable. Once, the peak vowel is shown the problem of nasality and assimilation comes in.
In French, by contrast, nasal vowels are phonemes distinct from oral vowels, since words exist which differ mainly in the nasal or oral quality of a vowel. For example, the words beau /bo/ "beautiful" and bon /bõ/ "good" are pronounced virtually the same (the vowel in bon is slightly more open, leading many dictionaries to transcribe it /bɔ̃/), except that the former is oral and the latter is nasal.
UKT: Though I cannot speak French, since my alternate home is in Canada which is officially a bilingual country in English and French, I am familiar with French pronunciation. When you speak Romabama as it is spelled, pronouncing your words as if speaking French, you will be able to pronounce Burmese words quite closely. Even if you don't speak French, don't despair - just don't pronounce the end consonants of CVÇ. If you would like to sample French pronunciations, or learn French the easy way, just visit a language teaching site such as www.rocketlanguages.com/french/premium/index.php?hop=hcb25 where you will get free lessons.
In Min Chinese, nasal vowels carry persistent air flow though both the mouth and the nose, producing an invariant and sustainable vowel quality. That is, this type of nasalization is synchronic and suprasegmental to the voicing. In contrast, nasal vowels in French or Portuguese are transitional, where the velum ends up constricting the mouth airway.
In languages which have transitional nasal vowels, it is commonly the case that there are fewer nasal vowels than oral ones. This appears to be due to a loss of distinctivity caused by the nasal articulation.
Abugida scripts, which are used for most Indian languages, use the bindu (.) {þé:þé:tín} symbol and its variations to denote nasal vowels and nasal junctions between consonants.
From: Resonance Disorders & Velopharyngeal Dysfunction: Simple Low-Tech and No-Tech Procedures for Evaluation and Treatment
Ann W. Kummer, Ph.D., CCC-SLP, ASHA Fellow, http://www.speechpathology.com/articles/article_detail.asp?article_id=332 101023
Resonance, as it relates to speech, is the modification of the sound that is generated by the vocal folds as it vibrates (resonates) through the cavities of the vocal tract (pharynx, oral cavity, and nasal cavity). The type and quality of resonance is determined greatly by the function of the velopharyngeal valve. As shown in Figure 1: Velum - normal position, the velopharyngeal valve is open for nasal breathing and remains open for the production of nasal sounds: /m/, /n/ /ŋ/ .
UKT 180715: Whenever nasals are cited, it is usual to cite only /m/, /n/ /ŋ/. This is because, these are the only known nasals in English words. For Bur-Myan speakers, we must think in terms of five or six basic nasal aksharas,
{ma.} /m/,
{na.} /n/,
{Na.} /ɳ/,
{ña.} /ɲ/,
/
{Ña.}/{Ñ.}* /ɲ/,
/
{gna.}/{ng} /ŋ/. We must also think in terms of what are described as voiceless nasals: basic nasals modified by
{ha.hto:} medial function. Lastly, and most importantly, we must think in terms of
{þé:þé:tín}-function which can nasalized all aksharas including plosive-stops such as
{ka.}, africates
{kya.}, and sibilant-fricatives
{þhya.} .
*
 When oral sounds are produced during
speech, the velopharyngeal valve closes,
thus directing both sound energy and
airflow from the pharynx into the oral
cavity (see Figure 2: Velum - raised).
Because airflow and sound travel in a
superior direction from the lungs to
the oropharynx, the velopharyngeal
valve must close completely to
prevent speech distortion.
When oral sounds are produced during
speech, the velopharyngeal valve closes,
thus directing both sound energy and
airflow from the pharynx into the oral
cavity (see Figure 2: Velum - raised).
Because airflow and sound travel in a
superior direction from the lungs to
the oropharynx, the velopharyngeal
valve must close completely to
prevent speech distortion.
The quality of resonance is also determined by the size and shape of the resonating cavities of the vocal tract. Certainly, obstruction in the pharynx, oral cavity, or nasal cavity affects the resonance. In addition, vowels are produced by altering the shape of the oral cavity through adjustments of the tongue and lips.
• Hypernasality
• Hyponasality
• Cul de Sac Resonance
• Mixed Resonance
Hypernasality : Hypernasality is a resonance disorder that occurs when there is too much sound in the nasal cavity during the production of non-nasal (voiced oral) sounds. This is usually due to either velopharyngeal dysfunction or a thin velum secondary to a submucous cleft or following a cleft palate repair. Hypernasality is often described as muffled or characterized by “mumbling.” This is due to the damping (sound absorption) effect as the sound energy passes through the turbinates of the nasal cavity.
Because hypernasality is due to abnormal resonance of sound, it is always associated with voiced speech consonants and vowels. When there is mild-to-moderate hypernasality, nasalization of oral phonemes is common. For example, when the velopharyngeal valve remains open during the attempted production of a voiced plosive, the acoustic product will be similar to the nasal cognate of that sound (i.e., m/b, n/d, and ŋ/g). Nasalization can also occur on other oral sounds, and nasal sounds can even be substituted for voiceless sounds. As a result, there may be predominate use of the nasal sounds (m, n, ŋ) throughout connected speech. Hypernasality on vowels and nasalization of phonemes will often increase in connected speech due to the additional demands on the velopharyngeal mechanism and the oral-motor system.
Hyponasality : In contrast to hypernasality, hyponasality occurs when there is insufficient sound energy resonating in the nasal cavity during the production of nasal consonants (/m/, /n/, /ŋ/). This is usually due to obstruction in the pharynx or nasal cavity. When nasal resonance is reduced, nasal consonants sound similar to their oral phoneme cognates (i.e., b/m, d/n, g/ŋ). Hyponasality can also affect the quality of vowels if it is severe. This is due to the fact that all vowels, particularly high vowels, have some nasal resonance as a result of transmission of sound through the velum.
Cul de Sac Resonance : Cul de sac resonance, like hyponasality, is due to obstruction. However, in this case, sound energy is blocked from exiting through the mouth or nose. For example, large tonsils can block sound from entering the oral cavity, so the sound remains trapped in the pharynx. A deviated septum could block the production of nasal sounds by causing the sound to be trapped in the nasal cavity. Cul de sac speech is also frequently described as “muffled” and low in volume due to the absorption of the sound by the tissues.
Mixed Resonance : Some individuals with blockage and velopharyngeal dysfunction can demonstrate mixed resonance with hypernasality on oral sounds and hyponasality on nasal sounds. Mixed resonance is also common in individuals with apraxia due to poor timing of closure or inappropriate upward movement of the velum on nasal sounds and downward movement of the velum on oral sounds.
UKT: More in the original article.
We must not think that the study of the human voice is
a modern endeavor. It has been studied by the Ancients
in antiquity. Among the ancient scholars, the most
famous was
Panini
, पाणिनि «pāṇini»,
![]() {pa-Ni.ni.}),
an Indian "grammarian" from Gandhara
(traditionally 520–460 BC, but estimates range from
the 7th to 4th centuries BC). (Go online, and use
the string "Panini" to look in Wikipedia. Since
the URL does not usually work, I have to use this search
method every time I wanted to call up the Wikipedia
article: 071219). We have reasons to believe that,
since Panini had mentioned those before him, the study
of human language has had its beginning since humans
appeared on this earth.
{pa-Ni.ni.}),
an Indian "grammarian" from Gandhara
(traditionally 520–460 BC, but estimates range from
the 7th to 4th centuries BC). (Go online, and use
the string "Panini" to look in Wikipedia. Since
the URL does not usually work, I have to use this search
method every time I wanted to call up the Wikipedia
article: 071219). We have reasons to believe that,
since Panini had mentioned those before him, the study
of human language has had its beginning since humans
appeared on this earth.


Panini पाणिनि «pāṇini», a patronymic
meaning "descendant of Pani") was
an ancient Indian grammarian from Gandhara . Perhaps,
the use of the word "grammar" to describe his
work is somewhat misleading. The word in Bur-Myan is
![]() {þûd~da} meaning "sound" (MEDict517), and so
it would be more fitting to refer to Panini as a
phonetician.
{þûd~da} meaning "sound" (MEDict517), and so
it would be more fitting to refer to Panini as a
phonetician.
Was Panini a Brahmin? I wonder. Since he was a scholar, he probably was a Brahmin. Brahmins were in the employ of the rulers as secretaries and scribes. In all Myanmar classical plays the Brahmin-secretary was the master mind, the villain, well hated by the audience.
Panini is known for his Sanskrit grammar, particularly for his formulation of the 3,959 rules of Sanskrit morphology in the grammar known as Ashtadhyayi (meaning "eight chapters"), the foundational text of the grammatical branch of the Vedanga, the auxiliary scholarly disciplines of Vedic religion.
The Sanskrit language is an ancient spoken language of
the Indian subcontinent. It is well known in Myanmar as
![]() {þak~ka.ta.} after the usage in Pali. It is also known as
{þak~ka.ta.} after the usage in Pali. It is also known as
![]() {þïn~þa.ka.reik} (MEDict507). However, Pali
{þïn~þa.ka.reik} (MEDict507). However, Pali
![]() {pa-Li.} (derived from Old Magadhi and Lanka speech) is more familiar to most of
the people because of commonality of many words between Pal-Myan (the sacred
language of Theravada Buddhism) and Bur-Myan. Pali and its parent Magadhi are also ancient Indic languages, and are
described as Prakrit or "proto-languages" or
{pa-Li.} (derived from Old Magadhi and Lanka speech) is more familiar to most of
the people because of commonality of many words between Pal-Myan (the sacred
language of Theravada Buddhism) and Bur-Myan. Pali and its parent Magadhi are also ancient Indic languages, and are
described as Prakrit or "proto-languages" or
![]() {pra-ka.reik}. Which language is more ancient, Sanskrit or
Pali, is debatable, but it is a fact that the most ancient
inscriptions found in India (those of Asoka) are written
in Pali in Asokan
{pra-ka.reik}. Which language is more ancient, Sanskrit or
Pali, is debatable, but it is a fact that the most ancient
inscriptions found in India (those of Asoka) are written
in Pali in Asokan Brahmi script
![]() {brah~mi ak~hka.ra}. Many people in Myanmaré, particularly
the Buddhist monks have to learn Pali as a language, a
sacred language. In Pali grammar, words are classified
into 10 classes depending on how they are formed:
{brah~mi ak~hka.ra}. Many people in Myanmaré, particularly
the Buddhist monks have to learn Pali as a language, a
sacred language. In Pali grammar, words are classified
into 10 classes depending on how they are formed:
1.
{þûm~bûn~Da.} (close juncture).
2.{wa.wût~hti.ta.} (open juncture). ... (MEDict517)
The Ashtadhyayi is the earliest known grammar of Sanskrit (though scholars agree it likely built on earlier works), and the earliest known work on descriptive linguistics, generative linguistics, and together with the work of his immediate predecessors (Nirukta, Nighantu, Pratishakyas) stands at the beginning of the history of linguistics itself.
Panini's comprehensive and scientific theory of grammar is
conventionally taken to mark the end of the period of
Vedic Sanskrit, by definition introducing Classical
Sanskrit.
One of the rare works (written in Bur-Myan) on
Phonology is by
![]() {hkín-kri:hpyau} -- the Abbot of Taung-dwin-gyi
of the Ava period (15th century AD?). It is
my intention to translate his works eventually,
among which is
{hkín-kri:hpyau} -- the Abbot of Taung-dwin-gyi
of the Ava period (15th century AD?). It is
my intention to translate his works eventually,
among which is
![]() {þûd~da.byu-ha kyûm:} ( {þad~da.} means
human voice). But before I could do so, I must first
learn Phonetics and Phonology the Western way, and
my present work is one of the foundation stones
that I am laying.
{þûd~da.byu-ha kyûm:} ( {þad~da.} means
human voice). But before I could do so, I must first
learn Phonetics and Phonology the Western way, and
my present work is one of the foundation stones
that I am laying.
Whether, the study of human voice had been recorded, and how
(other than by oral tradition from master to pupil), and by
what means (on stone, baked clay, metal, vegetable matter,
etc.) is entirely different from the study of the human voice
itself. Permanent record of "language" in the form
of "script" on stone appeared some 2000 years ago
in the time of Emperor Asoka (? - 232 BC) --
![]() {a.þau-ka.} in Bur-Myan. The script on Asoka pillars
is now known erroneously as Brahmi script (the script of the Brahmins),
from which the Myanmar script, in which Burmese language is written,
has descended. A sister script is Devanāgarī
{a.þau-ka.} in Bur-Myan. The script on Asoka pillars
is now known erroneously as Brahmi script (the script of the Brahmins),
from which the Myanmar script, in which Burmese language is written,
has descended. A sister script is Devanāgarī
![]() {dé-wa.na-ga.ri} in which modern Hindi is written. We must emphasize
at this point that Asokan
{dé-wa.na-ga.ri} in which modern Hindi is written. We must emphasize
at this point that Asokan Brahmi and its descendents use a method
of writing entirely different from Latin and its descendents:
English, French, Spanish, etc. Asokan Brahmi group uses an alpha-syllabic
script known as abugida, whereas Latin group uses an alphabet.
A hallmark of the Asoka scripts (Brahmi) is their phonology basis,
because of which there is a one-to-one correspondence between the phonemes (if
you compensate for the dialects and the idiolects), and between the respective
graphemes and glyphs. If you know the spelling of a word in one language, you can easily
derive at the spelling in another. It was obviously the aim of the Buddhist Emperor Asoka to
unify the languages of all his subjects and even of their neighbours, and thus
bring in unity and peace among the inhabitants of the region.
The British author H. G. Wells [1866-1946] wrote of Asoka: "In the history of the world there have been thousands of kings and emperors who called themselves 'Their Highnesses', 'Their Majesties' and 'Their Exalted Majesties' and so on. They shone for a brief moment, and as quickly disappeared. But Asoka shines and shines brightly like a bright star, even unto this day." -- http://www.indopedia.org/Ashoka.html 071114
The works of
Panini
![]() {þa-Ni.ni.} पाणिनि
«pāṇini»,
is now available in Devanagari script.
Though I do not know either Hindi or Sanskrit which are written in Devanagari,
I can still derive at the spelling in Bur-Myan. With this gift of Asoka,
I expect to be able to "learn" (without expecting to speak)
the various languages of Myanmarpré and her neighbours,
which will undoubtedly help me in my work on the medicinal plants of Myanmar,
and also on the cultures of the region. (See my work on the Myanmar Medicinal
Plants in
Para-Medicine -- MP-Para-indx.htm
(link chk 161125) The following is
an example of how transliteration from one script to another,
say from Devanagari to Myanmar may be done.
{þa-Ni.ni.} पाणिनि
«pāṇini»,
is now available in Devanagari script.
Though I do not know either Hindi or Sanskrit which are written in Devanagari,
I can still derive at the spelling in Bur-Myan. With this gift of Asoka,
I expect to be able to "learn" (without expecting to speak)
the various languages of Myanmarpré and her neighbours,
which will undoubtedly help me in my work on the medicinal plants of Myanmar,
and also on the cultures of the region. (See my work on the Myanmar Medicinal
Plants in
Para-Medicine -- MP-Para-indx.htm
(link chk 161125) The following is
an example of how transliteration from one script to another,
say from Devanagari to Myanmar may be done.
देवनागरी (in Devanagari script) = ?
द U0926 {da.} + े U0947 {tha.wé-hto:} --> दे {dé}
व U0935 {wa.} --> व {wa.}
न U0928 {na.} + ा U093E {weik-hkya.} --> ना {na}
ग U0917 {ga.} --> ग {ga.}
र U0930 {ra.} + ी U0940 {loän:ting-hsän-hkat} --> री {ri}
(Whenever, I have to transliterate from Devanagari to Myanmar, I use the above method.)Therefore: देवनागरी =
{dé-wa.na-ga.ri} (in Myanmar script). Since, most people in Myanmarpré knows some Pali and a bit of Sanskrit, we at once know that it is a script which is derived from the Nagari script (MEDict222), to which the prefix Deva meaning 'god' (MEDict210) has been added. Of course, being of different languages the pronunciations would be different, but close enough for the Hindi speaking Indian and Burmese speaking Myanmar to understand each other.
Note the sound of the second
grapheme in Asoka and
![]() {a.þau-ka.}. (The modern Hindi-Dev is अशोकः
{a.þau-ka.}. (The modern Hindi-Dev is अशोकः
![]() -- Wikipedia 071219).
-- Wikipedia 071219).
The Hindi-Dev pronunciation of this grapheme, स, is [s], but that of Bur-Myan is [θ]. (In the fricative consonants, the rule of correspondence between Devanagari and Myanmar breaks down which is due the way peoples of different ethnic groups articulate a particular sound. However, in this case, we can understand the reason. The two consonants [θ] and [s] are articulated very close to one another in the mouth: both [θ] and [s] are Dental-fricatives. However [c] present in Bur-Myan is a Palatal-plosive-stop. Bur-Myan is in need of [s] and I have to introduce a new phoneme-grapheme pair for it and present it also as killed-aksharas.
Palatal-stop
{sa.}/
{c}
Dental-fricative{Sa.}/
{S}
Bur-Myan ![]() {þa.} phoneme is best articulated with the tip of the tongue (how the Canadian
TV anchors - especially the females do) held lightly between the upper and lower
teeth.
This grapheme,
{þa.} phoneme is best articulated with the tip of the tongue (how the Canadian
TV anchors - especially the females do) held lightly between the upper and lower
teeth.
This grapheme,
![]() {þa.} /θ/, occupies the
6th row and 5th column (r6c5) in the akshara matrix
and is written in different ways in different abugidas:
{þa.} /θ/, occupies the
6th row and 5th column (r6c5) in the akshara matrix
and is written in different ways in different abugidas:
• Asoka script (Brahmi)
(my rendition based on http://www.ancientscripts.com/brahmi.html download 071109)
• Bengali স (U09B8)
• Devanagari स (U0938)
• Gurmukhi ਸ (U0A38)
• Gujarati સ (U0AB8)
• Bur-Myan{þa.}
• *English-Latin (digraph) <th> (Both Burmese and English has pronunciation [θ], but not German)
• Tamil ஸ (UBB8)
• Telugu స (U0C38)
(*English-Latin is an alphabet -- not abugida) (Bengali group is the northern Indic group, whereas the Tamil group is southern. It is up to you to decide to which group Myanmar script is allied to. To say that Myanmar is descended from a south Indian script is unacceptable.)
My study is part of my overall attempt to come up with a
reliable method of transcription (not transliteration) of Bur-Myan to Bur-Latin which I
have named Romabama
![]() {ro:ma.ba.ma} 'Backbone of Bur-Myan' which could be easily mistaken for
{ro:ma.ba.ma} 'Backbone of Bur-Myan' which could be easily mistaken for
![]() {rau:ma.ba.ma} 'Romanized Burmese.
{rau:ma.ba.ma} 'Romanized Burmese.
Human voice sounds can be divided into three broad
classes: the classifiable
![]() {wag}-sounds, the nasals, and the non-classifiable
{wag}-sounds, the nasals, and the non-classifiable
![]() {a.wag}-sounds. The oral sounds of the {wag} class are
also described as plosives or stops from the way
they are produced. The first four consonantal akshara in Bur-Myan
{a.wag}-sounds. The oral sounds of the {wag} class are
also described as plosives or stops from the way
they are produced. The first four consonantal akshara in Bur-Myan
![]() {ka.}-{hka.}-{ga.}-{Ga.} can be "identified" with:
{ka.}-{hka.}-{ga.}-{Ga.} can be "identified" with:
-- IPA [k] , tense voiceless (vl) velar stop,
![]() (Bur-Myan), क (Hindi-Devan), ক (Bangla-Bengali)
(Bur-Myan), क (Hindi-Devan), ক (Bangla-Bengali)

-- IPA [kʰ] , lax vl velar stop,
![]() {hka.}
(Bur-Myan), ख (Hindi-Devan) , খ (Bangla-Bengali)
{hka.}
(Bur-Myan), ख (Hindi-Devan) , খ (Bangla-Bengali)
-- IPA [g] (tense vd velar stop),
![]() (Bur-Myan), ग (Hindi-Devan) , গ (Bangla-Bengali)
(Bur-Myan), ग (Hindi-Devan) , গ (Bangla-Bengali)
-- IPA [gʰ] (lax vd velar stop).
![]() (Bur-Myan), घ (Hindi-Devani), ঘ (Bangla-Bengali)
(Bur-Myan), घ (Hindi-Devani), ঘ (Bangla-Bengali)
The so-called Brahmi script found on the oldest stone inscriptions in India, the Asoka inscriptions, bears a striking resemblance to the Myanmar script. This has led me to believe that Myanmar script is directly descended from the Asoka script, and not from a southern Indic script as is believed by the present day Western scholars, and by some in Myanmar.
See also:
• The Phonetic Description of Voice quality,
J. Laver, 1980, p.156.
• Speech considered as modulated voice by
H. Traumüller, 2001? --
http://www.ling.su.se/staff/hartmut/speech_considered.pdf
071130).
(I still have to work on Traumüller's work.)
Here you should note that English-Latin <k> sounds
more like [kʰ] than [k]. These two sounds are
described as allophones of /k/. Allophones are not present
in Bur-Myan except in
![]() {þa.}, which like its English counterpart <th> has
two sounds [θ] as in <thin> and [ð] as in
<that>.
{þa.}, which like its English counterpart <th> has
two sounds [θ] as in <thin> and [ð] as in
<that>.
Notice that, I have given
The IPA plosive consonant phonemes (aka stops) /k/-/g/ ;
/c/-/ɟ/ ; /ʈ/-/ɖ/ ; /t/-/d/
; /p/-/b/ on one hand, and Sanskrit-Hindi and Pali-Burmese
![]() {wag}-akshara oral sounds are different fundamentally because - for example, /k/
from
{wag}-akshara oral sounds are different fundamentally because - for example, /k/
from
![]() {ka.} and क ka - because /k/ lacks a vowel. If to each IPA phoneme a vowel
sound something like an English short <a> /æ/ or /a/ is
added.
{ka.} and क ka - because /k/ lacks a vowel. If to each IPA phoneme a vowel
sound something like an English short <a> /æ/ or /a/ is
added.
Within Bur-Myan and Hindi-Dev (in fact within all scripts derived from the
Asoka script), there is a strong correspondence in sounds because all are based
on phonemic principles, thus: /क/ =
/![]() /
, /ग/ = /
/
, /ग/ = /![]() / ; /च/
= /
/ ; /च/
= /![]() / ; /ज/
= /
/ ; /ज/
= /![]() / ; /ट/
= /
/ ; /ट/
= /![]() / ; /ड/
= /
/ ; /ड/
= /![]() / ; /त/ = /
/ ; /त/ = /![]() /
; /द/ = /
/
; /द/ = /![]() / ; /प/
= /
/ ; /प/
= /![]() / ; /ब/
= /
/ ; /ब/
= /![]() /.
Of course you would argue that there is no correspondence between /च/ vs /
/.
Of course you would argue that there is no correspondence between /च/ vs /![]() /
and /ज/ vs /
/
and /ज/ vs /![]() /.
However, please remember that one language is an IE (Indo-European), and the
other is Tib-Bur (Tibeto-Burman), and IE uses lots of friction where /s/ and /ʃ/
are common and /θ/ is not known, and also that it is the opposite in Tib-Bur
where /θ/ is quite common and /ʃ/ is rare. Speakers of the two groups should be
expected to use different sets of muscles.
/.
However, please remember that one language is an IE (Indo-European), and the
other is Tib-Bur (Tibeto-Burman), and IE uses lots of friction where /s/ and /ʃ/
are common and /θ/ is not known, and also that it is the opposite in Tib-Bur
where /θ/ is quite common and /ʃ/ is rare. Speakers of the two groups should be
expected to use different sets of muscles.
Until I came to study "Voice Quality", I could not appreciate why should there be a difference. Ancient linguist would be unable to relate sound to the movement of muscles and action of the voice box which could not be studied directly until the development of modern surgical methods. In fact, many facts about language came to be known from the field of surgery.
I have tested the "equivalence" between the Indic speeches (Bengali, Gujarati, Hindi, Tamil, Malayalam, etc.) of my Indian friends in Deep River, Ontario, Canada, and myself (Burmese), and we came to realize that the two aksharas Devanagari and Myanmar represent "almost" the same sounds if we take into consideration the fricative and rhotic nature of the Indic speeches. Then we could communicate on the terms used in Buddhism, Hinduism, Jainism and medicine. One Indian friend went as far as to comment "Joe (my Canadian name) you are just one of us!" . It was a crowning remark on my work of building bridges across communities and language groups.
The same relation is found in nasal
consonant phonemes /ŋ/ = /ङ/
= /![]() / ; /ɲ/
= /ञ/ = /
/ ; /ɲ/
= /ञ/ = /![]() /
; /ɳ/ = /ण/ = /
/
; /ɳ/ = /ण/ = /![]() /
; /n/ = /न/ = /
/
; /n/ = /न/ = /![]() /
; /m/ = /म/ = /
/
; /m/ = /म/ = /![]() / .
Even in the approximants, we find the same relationship.
/ .
Even in the approximants, we find the same relationship.
There is another class of sounds known as the vowel sounds, exemplified by and characterized by a minimum of three or four vowels for every human language. They are:
/a/ = /अ/ = /
{a.}/
/i/ = /इ/ = /{i.}/ = /
{I.}/
/u/ = /उ/ = /{u.}/ = /
{U}/
/ɑ/ = /ओ/ = /{au:}/ = /
{AU:}/
The vowels are all voiced (vd.). The
![]() {wag}-consonants and the
{wag}-consonants and the
![]() {a.wag}-consonants are either vd or vl, whereas the
nasal-consonants are all vd. The so-called Burmese
"voiceless nasals" referred by Ladefoged and others
are not basic aksharas but
{a.wag}-consonants are either vd or vl, whereas the
nasal-consonants are all vd. The so-called Burmese
"voiceless nasals" referred by Ladefoged and others
are not basic aksharas but
![]() {ha.hto:}-medials.
{ha.hto:}-medials.
See http://hctv.humnet.ucla.edu/departments/linguistics/VowelsandConsonants/vowels/chapter12/burmese.html 080322
You can also listen to sound files. The "voiceless nasals" given are:
velar:{ngha:} "to borrow" <))
palatal:{Ñha} "to be considerate" <))
dental:{nha} "nose" <))
bilabial:{mha.} "from" <))
This failure to differentiate the basic aksharas from the medials by the Western phoneticians (in fact the above 4 sounds given by Ladefoged) had given me great difficulty in understanding what was meant by voiced and voiceless. Moreover, the problem was compounded because what we could hear was only one segmental -- not that of the "complete" word. For example,{ngha:rûm:} (MEDict099). It is not well known that Bur-Myan words usually come in pairs known as
{sa.ka:hpo sa.ka:ma.} in which only one phoneme has the direct meaning. In
The ![]() {a.}-wag consonants referred to above consisted of
sounds represented by 7 aksharas. They include the four
(or five) "medial formers"
{a.}-wag consonants referred to above consisted of
sounds represented by 7 aksharas. They include the four
(or five) "medial formers"
![]() {ya.} /j/ <y>;
{ya.} /j/ <y>;
![]() {ra.} /ɹ/ <r>;
{ra.} /ɹ/ <r>;
![]() {la.} /l/ <l>;
{la.} /l/ <l>;
![]() {wa.} /w/ <w>;
{wa.} /w/ <w>;
![]() {ha.} /h] <h/; and
{ha.} /h] <h/; and
![]() {þa.} /θ/ <th> and
{þa.} /θ/ <th> and
![]() {a.} /a/ or /æ/. You will notice that
{a.} /a/ or /æ/. You will notice that
![]() {a.} is also described as a vowel (the "checked tone" of
{a.} is also described as a vowel (the "checked tone" of
![]() {a}).
{a}).
The members of the
![]() {a.}-wag class are variably grouped
and described as "semi-vowels", "fricatives",
"sibilants", "approximants", etc.
These terms have perplexed and confused me again
and again even to the present.
{a.}-wag class are variably grouped
and described as "semi-vowels", "fricatives",
"sibilants", "approximants", etc.
These terms have perplexed and confused me again
and again even to the present.
Of course, sound can be made by means other than air flowing out of the lungs. These would include clicking of the tongue, and of flow of air from outside the mouth to the interior. These by themselves could hardly convey any information, and play only small parts in the human voice communication.
Our study at this stage involves the production of sound or voice by the human body. (The various parts of the human body are usually shown in the sagittal plane as in Fig.1.3. above.) Our job is to show where the sound is produced and how.
One interesting question remains: at what age can a human baby start to talk on the basis of production of vowels. The following is the abstract on:
The Emergence of Vowels in an Infant, Robert D. Buhr, Brown Univ., Providence, Rhode Island, Journal of Speech and Hearing Research, vol.23 73-94 March 1980 - http://jslhr.asha.org/cgi/content/abstract/23/1/73 100414
"Recordings of vocal production of an infant (age 16–64 weeks) [ 4 months to over a year] were subjected to perceptual and acoustic analysis. Sounds resembling the vowel sounds of English were identified, and formant frequency measurements were made from spectrograms. Significant longitudinal trends for individual vowel sounds were not apparent during this period, although formant relationships for some vowels after 38 weeks were consistent with the notion of restructuring of the infant's vocal tract. However, analysis of F1/F2 plots over time revealed the emergence of a well-developed vowel triangle, resembling that of older children and adults. The acute axis of this triangle seems to develop before the grave axis. Implications for anatomical, neuromuscular, and linguistic development are discussed."
UKT: Note to TIL editors: this section should be moved to frica.htm
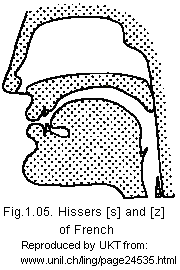
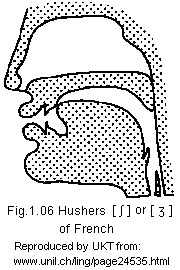 Though IPA [θ] sound is quite common in spoken Burmese language (speech),
the hissing and hushing sounds represented by [s] and [ ʃ ]
are noticeably rare.
Though IPA [θ] sound is quite common in spoken Burmese language (speech),
the hissing and hushing sounds represented by [s] and [ ʃ ]
are noticeably rare.
Hissers:
![]() {sa.} [s]
<))
;
{sa.} [s]
<))
;
![]() {za.} [z]<))
{za.} [z]<))
Hushers:
![]() {þhya.}
[ ʃ ]<))
; { -} [ ʒ ]<))
{þhya.}
[ ʃ ]<))
; { -} [ ʒ ]<))
The terms "hisser" and "husher" are from UNIL
http://www.unil.ch/ling/page30184_fr.html -- 070823)
A few years after the Second World War, I as a child of 11 or 12, had the chance to attend a European Code school, and my reading (English) was greatly improved. After those years, due to our change of residence, I had to go to an Anglo-vernacular school, where the students read rather poorly. After having been asked to read aloud in class, my classmates, in particular one Maung Kyi, started making fun of me for pronouncing my hissers and hushers. He would open his mouth, stuck out his tongue, and fanned it with his palm, saying "Oh, my tongue is itching, my tongue is itching", and everyone in class laughed at me. The reaction of my classmates in those days, was understandable. In fact, the usual remark one would hear in Myanmar in those days after hearing a Myanmar speak with somewhat of a Western accent is that "he or she speaks {tis-swut-swut} like a {bo}" (literally meaning "speaks like an English person with hissers and hushers."
Probably because of the paucity of hissers and hushers,
MLC had difficulty in deciding how to represent the
[ ʃ ] sound for some years in the 1960s. Finally
they were pressured by the government to come up with
a firm decision, and they adopted the spelling
![]() {rha.}, but to use
{rha.}, but to use
![]() {þhya.} especially in the names of some medicinal plants.
{þhya.} especially in the names of some medicinal plants.
The IPA [θ] sound, though classed as fricative is entirely different from the hissers and hushers which are collectively described as 'sibilants' or 'sibilant dentals'. The IPA [θ] sound also commonly described as a "dental" is best described as a 'thibilant' or thibilant dental'. Since it is produced with the tongue tip held lightly between the upper and lower teeth as usually done by Canadian TV anchors especially the females the preferred term should be 'inter-dental' and not 'dental'. We will see more of them in later sections.
From: http://en.wikipedia.org/wiki/Acoustic_phonetics 101028
Acoustic phonetics is a subfield of phonetics which deals with acoustic aspects of speech sounds. Acoustic phonetics investigates properties like the mean squared amplitude of a waveform, its duration, its fundamental frequency, or other properties of its frequency spectrum, and the relationship of these properties to other branches of phonetics (e.g. articulatory or auditory phonetics), and to abstract linguistic concepts like phones, phrases, or utterances.
The study of acoustic phonetics was greatly enhanced in the late 19th century by the invention of the Edison phonograph. The phonograph allowed the speech signal to be recorded and then later processed and analyzed. By replaying the same speech signal from the phonograph several times, filtering it each time with a different band-pass filter, a spectrogram of the speech utterance could be built up. A series of papers by Ludimar Hermann published in Pflüger's Archiv in the last two decades of the 19th century investigated the spectral properties of vowels and consonants using the Edison phonograph, and it was in these papers that the term formant was first introduced. Hermann also played back vowel recordings made with the Edison phonograph at different speeds to distinguish between Willis' and Wheatstone's theories of vowel production.
Further advances in acoustic phonetics were made possible by the development of the telephone industry. (Incidentally, Alexander Graham Bell's father, Alexander Melville Bell, was a phonetician.) During World War II, work at the Bell Telephone Laboratories (which invented the spectrograph) greatly facilitated the systematic study of the spectral properties of periodic and aperiodic speech sounds, vocal tract resonances and vowel formants, voice quality, prosody, etc.
On a theoretical level, acoustic phonetics really took off when it became clear that speech acoustic could be modeled in a way analogous to electrical circuits. Lord Rayleigh was among the first to recognize that the new electric theory could be used in acoustics, but it was not until 1941 that the circuit model was effectively used, in a book by Chiba and Kajiyama called "The Vowel: Its Nature and Structure". (Interestingly, this book by Japanese authors working in Japan was published in English at the height of World War II.) In 1952, Roman Jakobson, Gunnar Fant, and Morris Halle wrote "Preliminaries to Speech Analysis", a seminal work tying acoustic phonetics and phonological theory together. This little book was followed in 1960 by Fant "Acoustic Theory of Speech Production", which has remained the major theoretical foundation for speech acoustic research in both the academy and industry. (Fant was himself very involved in the telephone industry.) Other important framers of the field include Kenneth N. Stevens, Osamu Fujimura, and Peter Ladefoged.
Go back acoustic-phonetics-note-b
- UKT 180714: I had thought that speech is made up of Vowels and Consonants
only. Years later, I found that there are in-betweens: the Approximants
and the Nasals. Moreover, I realized it, my problem of finding correspondence
between Burmese (Bamah) speech and English speech had come to a dead-end when I
came to the back vowels
![]() {u},
{u},
![]() {o} and
{o} and
![]() {au}. I
realised that these should be compared using formants, F0, F1 and F2, which is
beyond me. So, I had to study Articulatory Phonetics. And then I came
across Articulatory Phnology. I now I am fully "stumped".
{au}. I
realised that these should be compared using formants, F0, F1 and F2, which is
beyond me. So, I had to study Articulatory Phonetics. And then I came
across Articulatory Phnology. I now I am fully "stumped".
UKT 180714: See articles in TIL HD-PDF and SD-PDF libraries:
¤ See a part of lecture on Speech Production and Phonetics, 2013,
- CsTutFi-SpPrdPhonetics<Ô> / Bkp<Ô> (link chk 180714)
¤ See also, Articulatory Phonology: A phonology for public language use, by Louis Goldstein and Carol A. Fowler, 2003
- LGoldsteinCAFowler-Artoculatory Phonolgy<Ô> / Bkp<Ô> (link chk 180714)
"A seminal idea is that language forms (that is, those entities of various grain sizes that theories of phonology characterize) are the means that languages provide to make between-person linguistic communication possible, and, as such, they are kinds of public action, not the exclusively mental categories of most theories of phonology, production and perception. A theory of phonology, then, should be a theory about the properties of those public actions, a theory of speech production should be about how those actions are achieved, and a theory of speech perception should be about how the
actions are perceived".
From: Wikipedia http://en.wikipedia.org/wiki/Articulatory_phonetics 071007
The field of Articulatory phonetics is a subfield of Phonetics. In studying articulation, phoneticians attempt to document how humans produce speech sounds (Vowels, Consonants, and Approximants - the in-betweens). That is, articulatory phoneticians are interested in how the different structures of the vocal tract, called the articulators (tongue, lips, jaw, palate, teeth etc.), interact to create the specific sounds.
Palatography: In order to understand how sounds are made, experimental procedures are often adopted. Palatography is one of the oldest instrumental phonetic techniques used to record data regarding articulators. In traditional, static palatography, a speaker's palate is coated with a dark powder. The speaker then produces a word, usually with a single consonant. The tongue wipes away some of the powder at the place of articulation. The experimenter can then use a mirror to photograph the entire upper surface of the speaker's mouth. This photograph, in which the place of articulation can be seen as the area where the powder has been removed, is called a palatogram.
Technology has since made possible electropalatography (or EPG). In order to collect EPG data, the speaker is fitted with a special prosthetic palate, which contains a number of electrodes. The way in which the electrodes are "contacted" by the tongue during speech provides phoneticians important information, such as how much of the palate is contacted in different speech sounds, or which regions of the palate are contacted, or what the duration of the contact is.
UKT: The last time I looked under this head in Wikipedia is in 2007, and the above is what I had copied. The following is from the same source again - three years later in 2010. From: Wikipedia: http://en.wikipedia.org/wiki/Articulatory_phonetics 101027
The field of articulatory phonetics is a subfield of phonetics. In studying articulation, phoneticians explain how humans produce speech sounds via the interaction of different physiological structures.
Generally, articulatory phonetics is concerned with the transformation of aerodynamic energy into acoustic energy. Aerodynamic energy refers to the airflow through the vocal tract. Its potential form is air pressure; its kinetic form is the actual dynamic airflow. Acoustic energy is variation in the air pressure that can be represented as sound waves, which are then perceived by the human auditory system as sound. [1]
The vocal tract can viewed through an aerodynamic-biomechanic model which includes three main components: 1. air cavities, 2. pistons , and, 3. air valves.
Air cavities are containers of air molecules of specific volumes and masses. The main air cavities present in the articulatory system are the supraglottal cavity and the subglottal cavity. They are so-named because the glottis, the openable space between the vocal folds internal to the larynx, separates the two cavities. The supraglottal cavity or the orinasal cavity is divided into an oral subcavity (the cavity from the glottis to the lips excluding the nasal cavity) and a nasal subcavity (the cavity from the velopharyngeal port which can be closed by raising the velum to the nostrils). The subglottal cavity consists of the trachea and the lungs. The atmosphere external to the articulatory stem may also be consisted an air cavity whose potential connecting points with respect to the body are the nostrils and the lips.
Pistons are initiators. The term initiator refers to the fact that they are used to initiate a change in the volumes of air cavities, and, by Boyle's Law, the corresponding air pressure of the cavity. The term initiation refers to the change. Since changes in air pressures between connected cavities lead to airflow between the cavities, initiation is also referred to as an airstream mechanism. The three pistons present in the articulatory system are the larynx, the tongue body, and the physiological structures used to manipulate lung volume (particularly the floor and the walls of the chest). The lung pistons are used to initiate a pulmonic airstream (found in all human languages). The larynx is used to initiate the glottalic airstream mechanism by changing the volume of the supraglottal and subglottal cavities via vertical movement of the larynx (with a closed glottis). Ejectives and implosives are made with this airstream mechanism. The tongue body creates a velaric airsteam by changing the pressure within in the oral cavity: the tongue body changes the mouth subcavity. Click consonants use the velaric airstream mechanism. Pistons are controlled by various muscles.
Valves regulate airflow between cavities. Airflow occurs when an air valve is open and there is a pressure difference between in the connecting cavities. When an air valve is closed, there is no airflow. The air valves are the vocal folds (the glottis) which regulate between the supraglottal and subglottal cavities, the velopharyngeal port which regulates between the oral and nasal cavities, the tongue which regulates between the oral cavity and the atmosphere, and the lips which also regulate between the oral cavity and the atmosphere. Like the pistons, the air valves are also controlled by various muscles.
In order to understand how sounds are made, experimental procedures are often adopted. Palatography is one of the oldest instrumental phonetic techniques used to record data regarding articulators. [4] In traditional, static palatography, a speaker's palate is coated with a dark powder. The speaker then produces a word, usually with a single consonant. The tongue wipes away some of the powder at the place of articulation. The experimenter can then use a mirror to photograph the entire upper surface of the speaker's mouth. This photograph, in which the place of articulation can be seen as the area where the powder has been removed, is called a palatogram. [5]
Technology has since made possible electropalatography (or EPG). In order to collect EPG data, the speaker is fitted with a special prosthetic palate, which contains a number of electrodes. The way in which the electrodes are "contacted" by the tongue during speech provides phoneticians with important information, such as how much of the palate is contacted in different speech sounds, or which regions of the palate are contacted, or what the duration of the contact is.
UKT: More in the Wiki article.
Go back articula-phonet-wiki-b
formant n. 1. Any of several frequency regions of relatively great intensity in a sound spectrum, which together determine the characteristic quality of a vowel sound. [German from Latin fōrmāns fōrmant-, present participle of fōrmāreto form from fōrma form] - AHTD
Go back formant-note-b
From:
• Wikipedia http://en.wikipedia.org/wiki/Grapheme 071111
• Wikipedia http://en.wikipedia.org/wiki/Phonemic_orthography 080309From Wikpediax 071111
In typography, a grapheme is the fundamental unit in written language. Graphemes include alphabetic letters, Chinese characters, numerals, punctuation marks, and all the individual symbols of any of the world's writing systems.
In a phonemic orthography, a grapheme corresponds to one phoneme. In spelling systems that are non-phonemic — such as the spellings used most widely for written English — multiple graphemes may represent a single phoneme. These are called digraphs (two graphemes for a single phoneme) and trigraphs (three graphemes). For example, the word ship contains four graphemes (s, h, i, and p) but only three phonemes, because sh is a digraph.
Different glyphs can represent the same grapheme, meaning they are allographs. For example, the minuscule letter a can be seen in two variants, with a hook at the top, and without. Not all glyphs are graphemes in the phonological sense; for example the logogram ampersand (&) represents the Latin word et (English word and), which contains two phonemes.
From: Wikipedia 080309
A phonemic orthography is a writing system where the written graphemes correspond to phonemes, the spoken sounds of the language. These are sometimes termed true alphabets, but non-alphabetic writing systems like syllabaries can be phonemic as well.
Languages with a good grapheme-to-phoneme correspondence include Bulgarian, Basque, Finnish, Georgian, Hungarian, Macedonian Mongolian in Cyrillic, Sanskrit, Turkish, Croatian and Serbian. Most constructed languages such as Esperanto and Lojban have phonemic orthographies.
UKT 180714: It is stated:
Burmese-Myanmar is a phonemic orthography similar to Sanskrit because both are descended from Asoka script now known as Asokan (or Brahmi) script.
As dialects of the English language vary significantly, it would be difficult to create a phonemic orthography that encompassed all of them. However, it is fairly easy to create one based on a standard accent such as Received Pronunciation. This would, however, exclude certain sound differences found in other accents, such as the bad-lad split in Australian English. With time, pronunciations change and spellings become out of date, as has happened to English and French. In order to maintain a phonemic orthography such a system would need periodic updating, as has been attempted by various language regulators and proposed by other spelling reformers.
Go back grapheme-wiki-b1
From: J J O'Connor and E F Robertson http://www-history.mcs.st-and.ac.uk/Biographies/Panini.html 101023
Panini was born in Shalatula, a town near to Attock on the Indus river in present day Pakistan. The dates given for Panini are pure guesses. Experts give dates in the 4th, 5th, 6th and 7th century BC and there is also no agreement among historians about the extent of the work which he undertook. What is in little doubt is that, given the period in which he worked, he is one of the most innovative people in the whole development of knowledge. We will say a little more below about how historians have gone about trying to pinpoint the date when Panini lived.
Panini was a Sanskrit grammarian who gave a comprehensive and scientific theory of phonetics, phonology, and morphology. Sanskrit was the classical literary language of the Indian Hindus and Panini is considered the founder of the language and literature. It is interesting to note that the word "Sanskrit" means "complete" or "perfect" and it was thought of as the divine language, or language of the gods.
A treatise called Astadhyayi (or Astaka ) is Panini's major work. It consists of eight chapters, each subdivided into quarter chapters. In this work Panini distinguishes between the language of sacred texts and the usual language of communication. Panini gives formal production rules and definitions to describe Sanskrit grammar. Starting with about 1700 basic elements like nouns, verbs, vowels, consonants he put them into classes. The construction of sentences, compound nouns etc. is explained as ordered rules operating on underlying structures in a manner similar to modern theory. In many ways Panini's constructions are similar to the way that a mathematical function is defined today. Joseph [G G Joseph, The crest of the peacock (London, 1991).] writes in [2]:- (ch1 is available in SD TIL library - Joseph-Hist-Math-ch1<Ô> 150819 )
[Sanskrit's] potential for scientific use was greatly enhanced as a result of the thorough systemisation of its grammar by Panini. ... On the basis of just under 4000 sutras [rules expressed as aphorisms], he built virtually the whole structure of the Sanskrit language, whose general 'shape' hardly changed for the next two thousand years. ... An indirect consequence of Panini's efforts to increase the linguistic facility of Sanskrit soon became apparent in the character of scientific and mathematical literature. This may be brought out by comparing the grammar of Sanskrit with the geometry of Euclid - a particularly apposite comparison since, whereas mathematics grew out of philosophy in ancient Greece, it was ... partly an outcome of linguistic developments in India.
Joseph goes on to make a convincing argument for the algebraic nature of Indian mathematics arising as a consequence of the structure of the Sanskrit language. In particular he suggests that algebraic reasoning, the Indian way of representing numbers by words, and ultimately the development of modern number systems in India, are linked through the structure of language.
Panini should be thought of as the forerunner of the modern formal language theory used to specify computer languages. The Backus Normal Form was discovered independently by John Backus [1924-2007] in 1959, but Panini's notation is equivalent in its power to that of Backus and has many similar properties. It is remarkable to think that concepts which are fundamental to today's theoretical computer science should have their origin with an Indian genius around 2500 years ago.
At the beginning of this article we mentioned that certain concepts had been attributed to Panini by certain historians which others dispute. One such theory was put forward by B Indraji in 1876. He claimed that the Brahmi numerals developed out of using letters or syllables as numerals. Then he put the finishing touches to the theory by suggesting that Panini in the eighth century BC (earlier than most historians place Panini) was the first to come up with the idea of using letters of the alphabet to represent numbers.
There are a number of pieces of evidence to support Indraji's theory that the Brahmi numerals developed from letters or syllables. However it is not totally convincing since, to quote one example, the symbols for 1, 2 and 3 clearly do not come from letters but from one, two and three lines respectively. Even if one accepts the link between the numerals and the letters, making Panini the originator of this idea would seem to have no more behind it than knowing that Panini was one of the most innovative geniuses that world has known so it is not unreasonable to believe that he might have made this step too.
There are other works which are closely associated with the Astadhyayi which some historians attribute to Panini, others attribute to authors before Panini, others attribute to authors after Panini. This is an area where there are many theories but few, if any, hard facts.
We also promised to return to a discussion of Panini's dates. There has been no lack of work on this topic so the fact that there are theories which span several hundreds of years is not the result of lack of effort, rather an indication of the difficulty of the topic. The usual way to date such texts would be to examine which authors are referred to and which authors refer to the work. One can use this technique and see who Panini mentions.
There are ten scholars mentioned by Panini and we must assume from the context that these ten have all contributed to the study of Sanskrit grammar. This in itself, of course, indicates that Panini was not a solitary genius but, like Newton [Issac Newton, 1643-1727], had "stood on the shoulders of giants". Panini must have lived later than these ten but this is absolutely no help in providing dates since we have absolutely no knowledge of when any of these ten lived.
What other internal evidence is there to use? Well of course Panini uses many phrases to illustrate his grammar any these have been examined meticulously to see if anything is contained there to indicate a date. To give an example of what we mean: if we were to pick up a text which contained as an example "I take the train to work every day" we would know that it had to have been written after railways became common. Let us illustrate with two actual examples from the Astadhyayi which have been the subject of much study. The first is an attempt to see whether there is evidence of Greek influence. Would it be possible to find evidence which would mean that the text had to have been written after the conquests of Alexander the Great? There is a little evidence of Greek influence, but there was Greek influence on this north east part of the Indian subcontinent before the time of Alexander. Nothing conclusive has been identified.
Another angle is to examine a reference Panini makes to nuns. Some argue that these must be Buddhist nuns and therefore the work must have been written after Buddha. A nice argument but there is a counter argument which says that there were Jaina nuns before the time of Buddha and Panini's reference could equally well be to them. Again the evidence is inconclusive.
There are references by others to Panini. However it would appear that the Panini to whom most refer is a poet and although some argue that these are the same person, most historians agree that the linguist and the poet are two different people. Again this is inconclusive evidence.
Let us end with an evaluation of Panini's contribution by Cardona in [G Cardona, Panini : a survey of research (Paris, 1976).] [1]:-
Panini's grammar has been evaluated from various points of view. After all these different evaluations, I think that the grammar merits asserting ... that it is one of the greatest monuments of human intelligence.
Go back Panini-note-b
From Wikipedia, http://en.wikipedia.org/wiki/Phonotactics 071230
UKT: See also sonority hierarchy in hv7.htm.
Phonotactics (in Greek phone = voice and tactic = course) is a branch of phonology that deals with restrictions in a language on the permissible combinations of phonemes. Phonotactics defines permissible syllable structure, consonant clusters, and vowel sequences by means of phonotactical constraints.
 Phonotactic constraints are language specific. For example,
in Japanese, consonant clusters like /st/ are not allowed,
although they are in English. Similarly, the sounds
/kn/ and /ɡn/ [obviously the
Phonotactic constraints are language specific. For example,
in Japanese, consonant clusters like /st/ are not allowed,
although they are in English. Similarly, the sounds
/kn/ and /ɡn/ [obviously the
![]() {nga.} [ŋ] sound] are not permitted at the beginning of
a word in Modern English but are in German and Dutch.
{nga.} [ŋ] sound] are not permitted at the beginning of
a word in Modern English but are in German and Dutch.
UKT 180715: In English both /sw/ and /st/ are allowed, whereas in Burmese, though /sw/ is allowed /st/ is not.
This shows that English /t/ is more sonorous than Burmese /t/. Whatever the case may be, in transliterating English to Burmese, we have to accept
Syllables have the following internal segmental structure:
• Onset (optional)
• Rime (obligatory, comprises Nucleus and Coda):
- Nucleus (obligatory)
- Coda (optional)
Both onset and coda may be empty, forming a vowel-only syllable, or alternatively, the nucleus can be occupied by a syllabic consonant.
English Phonotactics: The English syllable (and word) twelfths /twɛlfθs/ is divided into the onset /tw/, the nucleus /ɛ/, and the coda /lfθs/, and it can thus be described as CCVCCCC (C = consonant, V = vowel). On this basis it is possible to form rules for which representations of phoneme classes may fill the cluster. For instance, English allows at most three consonants in an onset, but among native words under standard accents, phonemes in a three-consonantal onset are limited to the following scheme:
/s/ + pulmonic + approximant:
• /s/ + /m/ + /j/
• /s/ + /t/ + /j ɹ/
• /s/ + /p/ + /j ɹ l/
• /s/ + /k/ + /j ɹ l w/
This constraint can be observed in the pronunciation of the word blue: originally, the vowel of blue was identical to the vowel of cue, approximately [iw]. In most dialects of English, [iw] shifted to [juː]. Theoretically, this would produce ** [bljuː]. The cluster [blj], however, infringes the constraint for three-consonantal onsets in English. Therefore, the pronunciation has been reduced to [bluː] by elision of the [j].
Other languages don't share the same constraint: compare Spanish pliegue [ˈpljeɣe] or French pluie [plɥi].
Sonority hierarchy: In general, the rules of phonotactics operate around the sonority hierarchy, stipulating that the nucleus has maximal sonority and that sonority decreases as you move away from the nucleus. The voiceless alveolar fricative [s] is lower on the sonority hierarchy than the alveolar lateral approximant [l], so the combination /sl/ is permitted in onsets and /ls/ is permitted in codas, but /ls/ is not allowed in onsets and /sl/ is not allowed in codas. Hence slips /slɪps/ and pulse /pʌls/ are possible English words while *lsips and *pusl are not. There are of course exceptions to this rule, but in general it holds for the phonotactics of most languages.
Go back phonotactics-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Quintilian 101031
 Marcus Fabius Quintilianus (ca. 35 – ca. 100) was a
Roman
rhetorician from
Hispania [old name for present day Spain], widely referred to in
medieval schools of rhetoric and in
Renaissance writing. In English translation, he is usually referred
to as Quintilian, although the alternate spellings of
Quintillian and Quinctilian are occasionally seen, the latter
in older texts.
Marcus Fabius Quintilianus (ca. 35 – ca. 100) was a
Roman
rhetorician from
Hispania [old name for present day Spain], widely referred to in
medieval schools of rhetoric and in
Renaissance writing. In English translation, he is usually referred
to as Quintilian, although the alternate spellings of
Quintillian and Quinctilian are occasionally seen, the latter
in older texts.
Quintilian was born ca. 35 in Calahorra, La Rioja in Hispania. His father, a well-educated man, sent him to Rome to study rhetoric early in the reign of Nero. While there, he cultivated a relationship with Domitius Afer, who died in 59. "It had always been the custom … for young men with ambitions in public life to fix upon some older model of their ambition … and regard him as a mentor" (Kennedy, 16). Quintilian evidently adopted Afer as his model and listened to him speak and plead cases in the law courts. Afer has been characterized as a more austere, classical, Ciceronian speaker than those common at the time of Seneca, and he may have inspired Quintilian’s love of Cicero.
Sometime after Afer's death, Quintilian returned to Spain, possibly to practice law in the courts of his own province. However, in 68, he returned to Rome as part of the retinue of Emperor Galba, Nero's short-lived successor. Quintilian does not appear to have been a close advisor of the Emperor, which probably ensured his survival after the assassination of Galba in 69.
After Emperor Galba's death, and during the chaotic Year of the Four Emperors which followed, Quintilian opened a public school of rhetoric. Among his students were Pliny the Younger, and perhaps Tacitus. The Emperor Vespasian made him a consul. The emperor "in general was not especially interested in the arts, but…was interested in education as a means of creating an intelligent and responsible ruling class" (19). This subsidy enabled Quintilian to devote more time to the school, since it freed him of pressing monetary concerns. In addition, he appeared in the courts of law, arguing on behalf of clients.
Of his personal life, little is known. In the Institutio Oratoria, he mentions a wife who died young, as well as two sons who predeceased him.
Quintilian retired from teaching and pleading in 88, during the reign of Domitian. His retirement may have been prompted by his achievement of financial security and his desire to become a gentleman of leisure. Quintilian had also survived under several emperors; the reigns of Vespasian and Titus were relatively peaceful, but Domitian was reputed to be difficult even at the best of times. Domitian’s increasing cruelty and paranoia may have prompted the rhetorician to quietly distance himself. The emperor does not appear to have taken offence; in the year 90, Quintilian was made tutor of Domitian's two grand-nephews and heirs. Even this may not have been a vote of confidence; "by the time [Quintilian] finished the Institutio Oratoria, the two young men —potential rivals to a shaky throne — had vanished into exile" (Murphy, xx). Otherwise, Quintilian spent his retirement writing his Institutio Oratoria. The exact date of his death is not known, but is believed to be sometime around 100. He does not appear to have long survived Domitian, who was assassinated in 96.
... ... ...
“My aim, then, is the education of the perfect orator” (Quintilianus, 1.Preface.9). Book I of Institutio Oratoria discusses at length the proper method of training an orator, virtually from birth. This focus on early and comprehensive education was in many ways a reflection of Quintilian’s career; Emperor Vespasian’s influence on the official status of education marked the period as one of conscientious education. Quintilian’s contribution to this line of thought, aside from his long career as a public educator, was the opening of his text, and it is regarded as a highlight of the discussion:
“Quintilian’s Institutio Oratoria is a landmark in the history of Roman education: it is the culmination of a long development, and it had no successor… [No] teacher was found who could speak with Quintilian’s authority, no orator sufficiently interested in the theory of his art to produce a second de Oratore” (Gwynn, 242).
His theory of education is one area in which Quintilian differs from Cicero. Cicero called for a broad, general education; Quintilian was more focused. He lays out the educational process step by step, from “hav[ing] a father conceive the highest hopes of his son from the moment of his birth” (Quintilianus, 1.1.1) [1]. Other concerns are that the child’s nurse should speak well (“The ideal according to Chrysippus, would be that she should be a philosopher” (1.1.4)), and that both the parents and the teachers of the child should be well-educated. [1] With respect to the parents, Quintilian “do[es] not restrict this remark to fathers alone” (1.1.6); [1] a well-educated mother is regarded as an asset to the growing orator. Quintilian also presents a wide review of suitable literary examples, and this work is also an important work of literary criticism. While he clearly favors certain writers, his fairness is notable, as even writers, such as Sallust, an influential practitioner of the sort of style that Quintilian opposed, are afforded some consideration. Above all, Quintilian holds up Cicero as an example of a great writer and orator.
Quintilian discusses many issues of education that are still relevant today. He believed that education should be begun early, as mentioned above, but also that it should be pleasurable for the child. “Above all things we must take care that the child, who is not yet old enough to love his studies, does not come to hate them and dread the bitterness which he had once tasted, even when the years of infancy are left behind. His studies must be made an amusement” (1.1.20). [1] The proliferation of educational toys available for pre-school aged children shows that this view still has power. He also examines the various pros and cons of public schooling versus homeschooling, eventually coming out in favour of public school, so long as it is a good school. His view is that public schools teach social skills along with their studies, and a student would benefit more from this than from studying in seclusion. One must note, however, that Quintilian makes a point of declaring that “a good teacher will not burden himself with a larger number of pupils than he can manage, and it is further of the very first importance that he should be on only friendly and intimate terms with us and make his teaching not a duty but a labor of love” (1.2.15).
Quintilian’s most arresting point about the growing orator, however, is that he should be educated in morality above all else. To Quintilian, only a good man could be an orator. This is another aspect where he differs from Cicero, or rather pushes further Cicero’s injunction that an orator should be a good man. Quintilian quite literally believed that an evil man could not be an orator, “[f]or the orator’s aim is to carry conviction, and we trust those only whom we know to be worthy of our trust” (Gwynn, 231). This was quite possibly a reaction to the corrupt and dissolute times in which Quintilian lived; he may have attributed the decline in the role of the orator to the decline in public morality. Only a man free from vice could concentrate on the exacting study of oratory. But “the good man does not always speak the truth or even defend the better cause…what matters is not so much the act as the motive” (Clarke, 117). Therefore, Quintilian’s good orator is personally good, but not necessarily publicly good.
UKT: More in the Wikipedia article.
Go back Quintilian-note-b
From: http://courses.nus.edu.sg/course/elltankw/history/Phon/D.htm 101028
Accents of English can be either rhotic or non-rhotic. A rhotic accent generally has /r/ more or less whenever it appears in the spelling. A non-rhotic accent, however, does not have the /r/ in final or pre-consonantal positions (this is sometimes known as the post-vocalic /r/, although others use the more accurate, but perhaps more cumbersome term, the non-prevocalic /r/). What this means is that speakers of non-rhotic accents have this rule: if the <r> in the spelling does not occur before a vowel sound, don’t pronounce it. (NOTE: vowel sound, not vowel letter.)
Here are examples of words and phrases where the <r> won’t be pronounced by non-rhotic speakers:
• department
• party pooper
• utter nonsense and balderdash
• Mr Carter, you are so argumentative, aren’t you
The phenomenon of non-rhoticity can be found in some other languages as well, such as Malay. Malay in Malaysia (Bahasa Melayu, Bahasa Malaysia) is non-rhotic whilst Malay in Indonesia (Bahasa Indonesia) is distinctively rhotic.
Indeed most southern Chinese languages like Hokkien, Teochew and Cantonese do not make use of /r/ at all, whereas northern Chinese languages like Mandarin make use of it extensively, so that some Singaporean versions of Mandarin are also non-rhotic, with the non-prevocalic <r> not pronounced (eg er ‘two’ pronounced [@] or [3]) and <r> in other positions pronounced [l] (eg ren ‘person’ pronounced [l@n]).
Turning back to English, we can say that all English accents were rhotic up until the early MnE period and non-rhoticity was a relatively late development. (Remember, spelling reflects pronunciation in the early MnE period.) What is particularly interesting about the non-prevocalic /r/ is that before it was lost, it affected the vowel preceding it. It did three kinds of things: (1) lengthened the preceding vowel sound; (2) changed the quality of the vowel sound; (3) caused diphthongisation.
UKT: More in the original article.
Go back rhoticity-note-b

From: Wikipedia http://en.wikipedia.org/wiki/Sagittal_plane 071219
A sagittal plane of the human body is an imaginary plane that travels from the top to the bottom of the body.
From a broader perspective, it is one of the planes of the body used to
describe the location of body parts in relation to each other. The other
reference planes used in anatomy are:
• The coronal (or frontal) plane divides the body into dorsal and ventral
(back and front) portions.
• A transverse (or horizontal) plane divides the body
into cranial and caudal (top and bottom) portions.
Go back sagittal-plane-note-b
From: Wolfgang von Kempelen's speaking machine and its successors, http://www.ling.su.se/staff/hartmut/kemplne.htm 071107

The first attempts to produce human speech by machine were made in the 2nd half of the 18th century. Ch. G. Kratzenstein, professor of physiology in Copenhagen, previously in Halle and Petersburg, succeeded in producing vowels using resonance tubes connected to organ pipes (1773). At that time, Wolfgang von Kempelen had already begun with his own attempts that led him to construct a speaking machine. Von Kempelen was an ingenious person in the service of empress Maria Theresa in Vienna. He was born in 1734 in Bratislava, then capital of Hungary, and he died in Vienna in 1804. While he became known for various additional feats, his main concern was the study of human speech production, with therapeutic applications in mind. He has been called the first experimental phonetician. ...
As late as in 1937, R. R. Riesz (USA) constructed a device similar to those mentioned above, but with a vocal tract shape that was close to the natural.
UKT: In the diagram, you will notice two valves in the larynx (the glottal area), and one at the velum. The nature of the sound can be changed by Manipulating these valves.
Go back: mech-model-b
UKT: I would like to represent every Bur-Myan
akshara-grapheme with single letter of the English-Latin alphabet.
Unfortunately, there are some akshara-graphemes
that cannot be represented by single letter of English-Latin alphabet because
the latter has only 26 letters. Among the Bur-Myan akshara-graphemes, there are
three that are in dire need:
![]() r1c5,
r1c5,
![]() r2c5 and
r2c5 and
![]() r6c5.
r6c5.
For ![]() r2c5, I could choose the Spanish Ñ.
r2c5, I could choose the Spanish Ñ.
For
![]() r1c5, I have to use digraph <ng>
(of the English word <sing>). Remember
that a "digraph" is a grapheme (unit of typography)
made up of two letters such as <n> and <g>.
The pronunciation of <ng> is different from either <n>
or <g>. This reminds me of Chemistry where a compound
such as NaCl has properties entirely different from either of its
constituent-elements: Na or Cl. Without explaining that <ng>
is a digraph, we are simply told of its changing pronunciation
in different environments:
r1c5, I have to use digraph <ng>
(of the English word <sing>). Remember
that a "digraph" is a grapheme (unit of typography)
made up of two letters such as <n> and <g>.
The pronunciation of <ng> is different from either <n>
or <g>. This reminds me of Chemistry where a compound
such as NaCl has properties entirely different from either of its
constituent-elements: Na or Cl. Without explaining that <ng>
is a digraph, we are simply told of its changing pronunciation
in different environments:
<sing> /sɪŋ/ -- DJPD16-490 (<g> is not pronounced)
<singer> /sɪŋ.əʳ/ -- DJPD16-490 (<g> is pronounced)
<finger> /fɪŋ.gʳəʳ/ -- DJPD16-204 (<g> is pronounced -- the implication is that it is not part of the digraph)
This has led me to point out to Myanmars NOT to pronounce English words according to their spellings. This is exactly opposite to our saying that "what is written is correct, but what is pronounced is just sound".
For
![]() r6c5 , and <th> (of English <the> and <thin>).
At one time there was a character to represent <th>.
It is known as "thorn".
r6c5 , and <th> (of English <the> and <thin>).
At one time there was a character to represent <th>.
It is known as "thorn".
thorn n. 4. The runic letter [ þ ] originally representing either sound of the Modern English <th>, as in <the> and <thin> , used in Old English and Middle English manuscripts. [Middle English from Old English] -- AHTD
Go back thorn-note-b
Contents of this page
End of TIL file.
