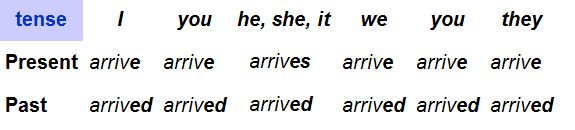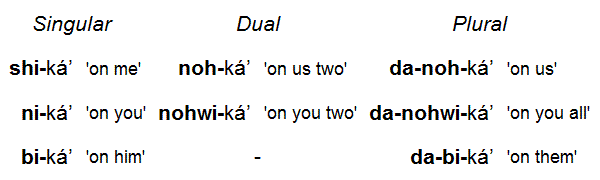IE.htm
by U Kyaw Tun, M.S. (I.P.S.T., U.S.A.). Not for sale. Prepared for
students of TIL Computing and Language Center, Yangon, MYANMAR.
based primarily on An Elementary Pali Course, by Ven. Narada Thera
www.buddhanet.net/pdf_file/ele_pali.pdf 080721
index.htm | |Top
lang-mean-indx.htm
Indo-European languages
History of Indo-European
linguistics
Classification of IE
Inflection
Inflection in various languages
Inflection in Indo-Eurpean languages (fusional)
Inflection in East-Asian
languages
UKT: There is confusion on two words, Indo-European and Indo-Aryan. Indo-Aryan is a subset of Indo-Iranian, which itself is a subset of Indo-European. See Wikipedia: http://en.wikipedia.org/wiki/Indo-Aryan_peoples 101206. Since both Pali and English are Indo-European (IE) languages , the reader should pay particular attention to this and other files dealing with inflection (a hallmark of IE). You should also note that Burmese-Myanmar is not an IE but a Tibeto-Burman (Tib-Bur) language, yet because of the influence of Pali and Sanskrit, literary Burmese (to be differentiated from the colloquial) has come to be highly Pali-tised. Because of this also this file is important.
UKT Notes
• finite verb
• grammatical category
• isolating language (e.g. Burmese-Myanmar)
• lexical category (also word class, lexical
class, or in traditional grammar "part of speech")
• lemmatisation
• marker
• William (Sir) Jones
Noteworthy passages in this file:
• Traditional English grammar is patterned after the European tradition ... ,
and is still taught in schools and used in
dictionaries. It names eight parts of speech:
noun, verb, adjective, adverb, pronoun, preposition, conjunction, and
interjection (sometimes called an exclamation).
-- from Wikipedia:
http://en.wikipedia.org/wiki/Word_class 090804
• Many linguists argue that the formal distinctions between parts of speech must
be made within the framework of a specific language or language family, and
should not be carried over to other languages or language families. -- from Wikipedia:
http://en.wikipedia.org/wiki/Word_class 090804
Based on excerpts from downloads:
• http://en.wikipedia.org/wiki/Indo-European_languages 090724
• http://en.wikipedia.org/wiki/Indo-European_languages 090907
The Indo-European languages are a family (or phylum) of several hundred related languages and dialects, [1] including most major languages of Europe, Iran, and northern India, and historically also predominant in Anatolia and Central Asia. Attested since the Bronze Age, in the form of Mycenaean Greek and Anatolian languages, the Indo-European family is significant to the field of historical linguistics as possessing the longest recorded history after the Afro-Asiatic family.
UKT: Another language group with a similar acronym is Austro-Asiatic, of which Mon-Myan (Mon speech in Myanmar akshara) is of interest to us. -- UKT101207
The languages of the Indo-European group are spoken by approximately three billion native speakers, the largest number of the recognised families of languages. (The Sino-Tibetan family has the second-largest number of speakers, while several disputed proposals merge Indo-European with other major language families.).
Based on excerpts from downloads:
• http://en.wikipedia.org/wiki/Indo-European_languages 090724
• http://en.wikipedia.org/wiki/Indo-European_languages 090907
Suggestions of similarities between Indian and European languages began to be made by European visitors to India in the 16th century. In 1583 Thomas Stephens, an English Jesuit missionary in Goa, noted similarities between Indian languages, specifically Konkani, and Greek and Latin. These observations were included in a letter to his brother which was not published until the twentieth century. [2]
The first account to mention Sanskrit came from Filippo Sassetti (born in Florence, Italy in 1540 AD), a Florentine merchant who traveled to the Indian subcontinent and was among the first European observers to study the ancient Indian language, Sanskrit. Writing in 1585, he noted some word similarities between Sanskrit and Italian (e.g. devaḥ/dio "God", sarpaḥ/serpe "serpent", sapta/sette "seven", aṣṭa/otto "eight", nava/nove "nine"). [2] However, neither Stephens' nor Sassetti's observations led to further scholarly inquiry. [2]
In 1647 Dutch linguist and scholar Marcus Zuerius van Boxhorn noted the similarity among Indo-European languages, and supposed the existence of a primitive common language which he called "Scythian". He included in his hypothesis Dutch, Greek, Latin, Persian, and German, later adding Slavic, Celtic and Baltic languages. However, the suggestions of Van Boxhorn did not become widely known and did not stimulate further research.
Gaston Coeurdoux and others had made observations of the same type. Coeurdoux actually made a thorough comparison of Sanskrit, Latin and Greek conjugations in the late 1760s to suggest a relationship between them, about 20 years before William Jones.
The hypothesis reappeared in 1786 when Sir William Jones first lectured on similarities between four of the oldest languages known in his time: Latin, Greek, Sanskrit, and Persian. It was Thomas Young who first used the term Indo-European in 1813, [3] which became the standard scientific term (except in Germany [4]) through the work of Franz Bopp, whose systematic comparison of these and other old languages supported the theory. Bopp's Comparative Grammar, appearing between 1833 and 1852, counts as the starting point of Indo-European studies as an academic discipline.
UKT: Contd. in Classification of IE.
Excerpt from: http://en.wikipedia.org/wiki/Indo-European_languages 090724
The various subgroups of the I-E language family include ten major branches (in historical order of their first attestation):
1. Anatolian languages, earliest attested branch. Isolated terms in Old Assyrian sources from the 19th century BC, Hittite texts from about the 16th century BC; extinct by Late Antiquity.
2. Hellenic (Greek) languages, fragmentary records in Mycenaean Greek from the late 15th - early 14th century BC; Homeric traditions date to the 8th century BC. (See : Wikipedia articles on Proto-Greek language, History of the Greek language.)
3. Indo-Iranian languages, descending from a common ancestor, Proto-Indo-Iranian (dated to the late 3rd millenium BC)
¤ Indo-Aryan languages, attested epigraphically from the 3rd century BC in the form of Prakrit (Edicts of Ashoka) , but assumed to preserve intact records via oral tradition dating from about the mid 2nd millennium BC in the form of Vedic Sanskrit (Rigveda).UKT:
• Are we sure that the 'Prakrit' such as Magadhi was IE? Is it possible that Magadhi was Tib-Bur because the areas where it was spoken was populated mostly by Tib-Bur speakers.
How can we explain the presence of dedicated grapheme representing velar nasal /ŋ/ in Asoka (Brahmi) script, but is absent in Devanagari used to write Hindi. To make up for the absence, Devanagari has to borrow the grapheme from retroflex ड /ɖ/ and add a 'dot' to give ङ . /ŋ/ sound is quite common in Bur-Myan but absent in IE.
Then there is Thibilant-Sibilant problem. Bur-Myan, typical Tib-Bur, is rich in /θ/ sounds, whereas IE languages uses /ʃ/ and /s/ sounds in their place. I am waiting for input from my peers. -- UKT101206
• 2nd millennium BC would correspond to the past 4000 years from the present day.¤ Iranian languages, attested from roughly 1000 BC in the form of Avestan. Epigraphically from 520 BC in the form of Old Persian (Behistun inscription)
¤ Dardic languages
¤ Nuristani languages4. Italic languages, including Latin and its descendants (the Romance languages), attested from the 7th century BC.
5. Celtic languages, descended from Proto-Celtic. Gaulish inscriptions date as early as the 6th century BC; Old Irish manuscript tradition from about the 8th century AD.
6. Germanic languages (from Proto-Germanic), earliest testimonies in runic inscriptions from around the 2nd century AD, earliest coherent texts in Gothic, 4th century AD. Old English manuscript tradition from about the 8th century AD.
7. Armenian language, alphabet writings known from the beginning of the 5th century AD.
8. Tocharian languages, extant in two dialects, attested from roughly the 6th to the 9th century AD. Marginalized by the Old Turkic Uyghur Khaganate and likely extinct by the 10th century.
9. Balto-Slavic languages, believed by most Indo-Europeanists [5] to form a phylogenetic unit, while a minority ascribes similarities to prolonged language contact.
¤ Slavic languages (from Proto-Slavic), attested from the 9th century AD, earliest texts in Old Church Slavonic.
¤ Baltic languages, attested from the 14th century AD, and, for languages attested that late, they retain unusually many archaic features attributed to Proto-Indo-European (PIE).10. Albanian language, attested from the 15th century AD; Proto-Albanian likely emerged from "Paleo-Balkanic" predecessors. [6] [7]
In addition to the classical ten branches listed above, several extinct and little-known languages have existed:
• Illyrian languages — possibly related to Messapian or Venetic; relation to Albanian also proposed.
• Venetic language — close to Italic.
• Liburnian language — apparently grouped with Venetic.
• Messapian language — not conclusively deciphered.
• Phrygian language — language of ancient Phrygia, possibly close to Greek, Thracian, or Armenian.
• Paionian language — extinct language once spoken north of Macedon.
• Thracian language — possibly including Dacian.
• Dacian language — possibly close to Thracian or to Proto-Albanian – or both.
• Ancient Macedonian language — related to Greek; some propose relationships to Illyrian, Thracian or Phrygian.
• Ligurian language — possibly not Indo-European; possibly close to or part of Celtic.
• Lusitanian language — possibly related to (or part of) Celtic, or Ligurian, or Italic.
UKT: More in the Wikipedia article.
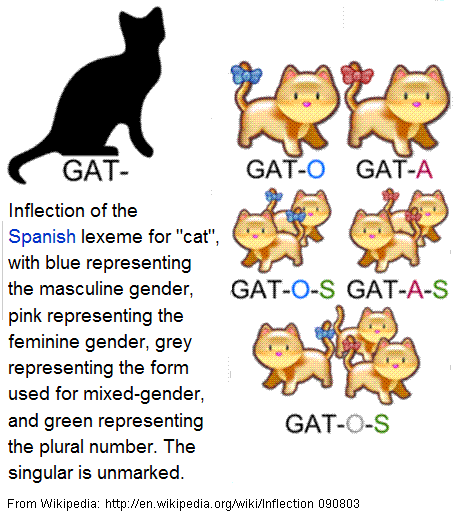
From: Wikipedia: http://en.wikipedia.org/wiki/Inflection 090803
UKT: Neither Burmese or Pali is mentioned in this article. I suggest that you include Burmese in the group where Chinese is mentioned and Pali in the Sanskrit group.
In grammar, inflection or inflexion is the way language handles
grammatical relations and relational categories such as
tense,
mood,
voice,
aspect (conjugation only) [see
inflect2.htm],
person,
number (conjugation and declension),
gender,
case (declension only) .
Beside conjugation and declension there is
comparison with its maximum category number of two ('direction', i. e. more or
less, and 'degree', i. e. positive, comparative, superlative, elative etc.). It
is a question of definition whether or not comparison is considered a kind of
inflection. In covert inflection, such categories are not overtly expressed.
(wiki-inflect-fn01b).
Overt inflection typically distinguishes
lexical
items (such as lexemes) from functional ones (such as
affixes,
clitics,
particles and
morphemes
in general) and has functional items acting as
markers on lexical ones.
(wiki-inflect-fn02b).
Lexical items that do not respond to overt inflection are typically
invariant. (wiki-inflect-fn03b) .
Constraining cross-referencing inflection at the sentence level is known as concord or
agreement.
In English many nouns are inflected for number with the inflectional plural affix -s (as in "dog" → "dog-s"), and most English verbs are inflected for tense with the inflectional past tense affix -ed (as in "call" → "call-ed").
English also inflects verbs by affixation to mark the third person singular in the present tense (with -s), and the present participle (with -ing). English short adjectives are inflected to mark comparative and superlative forms (with -er and -est respectively).
In addition, English also shows inflection by ablaut (mostly in verbs) and umlaut (mostly in nouns), as well as the odd long-short vowel alternation. For example:
• Write, wrote, written (ablaut, and also suffixing in the participle)
• Sing, sang, sung (ablaut)
• Foot, feet (umlaut)
• Mouse, mice (umlaut)
• Child, children (vowel alternation, and also suffixing in the plural)
In the past, writers sometimes gave words such as doctor, Negro, dictator, professor, and oratorLatin inflections to mark them as feminine, thus forming doctress, Negress, dictatrix, professress, and oratress. These inflected forms were never frequently used, although many English users continue to use Latin endings today in somewhat more common constructions such as actress, waitress, executrix, and dominatrix.
German, which is closely related to English, employs many of these inflectional devices, but the umlaut and ablaut are widespread, while in English they are generally considered as exceptions.
Two traditional grammatical terms refer to inflections of specific word classes:
• Nominals: nouns, and often pronouns, adjectives, and determiners as well; often involving number, case, and/or gender; and
• Verbs, often involving tense, mood, voice, and/or aspect, as well as agreement with one or more arguments in number, gender, and/or person.
Inflecting a nominal word is known as declining it, while inflecting a verb is called conjugating it. An organized list of the inflected forms of a given lexeme is also called its inflection, declension, or conjugation, as the case may be.
Below is an example of the declension of the English pronoun < I >, which is inflected for case and number.
The pronoun who is also inflected in conservative English, though only according to case. One can say that its declension is defective, in the sense that it lacks a reflexive form.
The following table shows the conjugation of the verb to arrive in the indicative mood. It is inflected for person, number, and tense by suffixation.
The non-finite forms arrive (bare infinitive), arrived (past participle) and arriving (gerund/present participle), although not inflected for person or number, can also be regarded as part of the conjugation of the verb to arrive. Compound verb forms like I have arrived, I had arrived, or I will arrive can be included also in the conjugation of this verb for didactical purposes, but are not conjugations of arrive in the strictest morphological sense. Rather, they should be analysed as complex verb phrases with the structure
pronoun + conjugated auxiliary verb + non-finite form of main verb.
A class of words with similar inflection rules is called an inflectional paradigm. Nominal inflectional paradigms are also called declensions, and verbal inflectional paradigms are called conjugations. For example, in Old English nouns could be divided into two major declensions, the strong and the weak, inflected as is shown below:
These two terms, however, seem to be biased toward well-known dependent-marking languages (such as the Indo-European languages, or Japanese). In dependent-marking languages, nouns in adpositional phrases can carry inflectional morphemes. (Adpositions include prepositions and postpositions.) In head-marking languages, the adpositions can carry the inflection in adpositional phrases. This means that these languages will have inflected adpositions. In Western Apache (San Carlos dialect), the postposition -ká’ 'on' is inflected for person and number with prefixes.
Traditional grammars have specific terms for inflections of nouns and verbs, but not for those of adpositions.
Inflection is the process of adding inflectional morphemes (atomic meaning units) to a word, which may indicate grammatical information (for example, case, number, person, gender or word class, mood, tense, or aspect). Compare with derivational morphemes, which create a new word from an existing word, sometimes by simply changing grammatical category (for example, changing a noun to a verb).
Words generally do not appear in dictionaries with inflectional morphemes. But they often do appear with derivational morphemes. For instance, English dictionaries list readable and readability, words with derivational suffixes, along with their root read. However, no traditional English dictionary will list book as one entry and books as a separate entry nor will they list jump and jumped as two different entries.
In some languages, inflected words do not appear in a fundamental form (the root morpheme) except in dictionaries and grammars.
Languages that add inflectional morphemes to words are sometimes called inflectional languages. Morphemes may be added in several different ways:
• Affixation, or simply adding morphemes onto the word without changing the root,
• Reduplication, doubling all or part of a word to change its meaning,
• Alternation, exchanging one sound for another in the root (usually vowel sounds, as in the ablaut process found in Germanic strong verbs and the umlaut often found in nouns, among others).
• Suprasegmental variations, such as of stress, pitch or tone, where no sounds are added or changed but the intonation and relative strength of each sound is altered regularly. For an example, see Initial-stress-derived noun.
Affixing includes prefixing (adding before the base), and suffixing (adding after the base), as well as the much less common infixing (inside) and circumfixing (a combination of prefix and suffix).
Inflection is most typically realized by adding an inflectional morpheme (that is, affixation) to the base form (either the root or a stem).
Languages that add inflectional morphemes to words are sometimes called inflectional languages. Morphemes may be added in several different ways:
• Affixation, or simply adding morphemes onto the word without changing the root,
• Reduplication, doubling all or part of a word to change its meaning,
• Alternation, exchanging one sound for another in the root (usually vowel sounds, as in the ablaut process found in Germanic strong verbs and the umlaut often found in nouns, among others).
• Suprasegmental variations, such as of stress, pitch or tone, where no sounds are added or changed but the intonation and relative strength of each sound is altered regularly. For an example, see Initial-stress-derived noun.
Affixing includes prefixing (adding before the base), and suffixing (adding after the base), as well as the much less common infixing (inside) and circumfixing (a combination of prefix and suffix).
Inflection is most typically realized by adding an inflectional morpheme (that is, affixation) to the base form (either the root or a stem).
Excerpt from Wikipedia: http://en.wikipedia.org/wiki/Inflection 090803
Excerpt from Wikipedia: http://en.wikipedia.org/wiki/Inflection 090803
All Indo-European languages, such as Albanian, English, German, Russian, Persian (Fârsi), Italian, Spanish, French, Sanskrit, Bengali and Hindi are inflected to a greater or lesser extent. In general, older Indo-European languages such as Latin,Ancient Greek,Old English, Old Norse, and Sanskrit are extensively inflected. Deflexion has caused modern versions of some languages that were previously highly inflected to be much less so; an excellent example is Modern English, as compared to Old English. However, some branches of Indo-European have generally tended to retained more inflection. The branch of Indo-European that has retained the most extensive systems of inflection is the Balto-Slavic branch: Modern Baltic languages are considered the most conservative of all Indo-European languages, and Slavic languages also tend to be highly inflected, with only few exceptions (e.g. Bulgarian). Branches notable for resulting in virtually no highly inflected modern languages include that of the romance languages (although most of these have conserved a good deal of inflection in verb conjugation, case declension is generally restricted to personal pronouns). Other branches resulted in more of a mixed bag: for example, the Germanic branch gave rise to some very inflected languages (such as German and Icelandic, while also giving rise to very uninflected languages, like Modern English, Swedish, and Afrikaans.
Old English was a moderately inflected language, using an extensive case system similar to that of modern Icelandic or German. Middle and Modern English lost progressively more of the Old English inflectional system. Modern English is considered a weakly inflected language, since its nouns have only vestiges of inflection (plurals, the pronouns), and its regular verbs have only four forms: an inflected form for the past indicative and subjunctive (looked), an inflected form for the third-person-singular present indicative (looks), an inflected form for the present participle (looking), and an uninflected form for everything else (look). While the English possessive indicator 's (as in "Jane's book") is a remnant of the Old English genitive case suffix, it is now not a suffix but a clitic. See also Declension in English.
Old Norse was inflected, but modern Swedish, Norwegian and Danish have, like English, lost almost all inflection. Icelandic preserves almost all of the inflections of Old Norse and has added its own. Modern German remains moderately inflected, retaining four noun cases, although the genitive had already started falling into disuse in all but formal writing in Early New High German, inspiring the title of the 2004 bestseller Der Dativ ist dem Genitiv sein Tod ("the dative is the death of the genitive", using the dative where archaic or formal writing would use the genitive). The case system of Dutch, simpler than German's, is also becoming more simplified in common usage. Afrikaans, recognized as a distinct language in its own right rather than a Dutch dialect only in the early 20th century, has lost almost all inflection.
The Romance languages, such as Spanish, Italian, French, Portuguese and Romanian, have more inflection than English, especially in verb conjugation. A single morpheme usually carries information about person, number, tense, aspect and mood, and the verb paradigm may be quite complex. Adjectives, nouns and articles are considerably less inflected, but they still have different forms according to number and grammatical gender.
Latin was even more inflected; nouns and adjectives had different forms according to their grammatical case (with several patterns of declension, and three genders instead of the two found in most Romance tongues), and there were synthetic perfective and passive voice verb forms.
The Baltic languages (presented nowadays by Lithuanian and Latvian) are moderately inflected retaining a number of archaic Indo-European features in their grammar. Nouns and adjectives are declined in seven cases. Some grammars define more cases based on two principles:
• Syncretism of case forms in Latvian where certain preposition govern different cases in the singular and in the plural. For example, the Instrumental case is identical to the Accusative in the singular and to the Dative in the plural. These forms could be described as irregular case government of certain prepositions, but there are constructions in which the Instrumental case, for example, is used without any prepositions.
• dialectal and rare use of old case forms, such as Illative in modern Lithuanian which is widely used in the singular but extinct in the plural: "mišk-an (ill.), į mišk-ą (prep. + acc.) - (in)to the forest" and "į mišk-us (prep. + acc.) - (in)to the forests"
Modern Baltic languages have also retained the old dual number. However, it is nowadays considered obsolete and included in grammar books as a reference and not as compulsory learning material. For instance, in standard Lithuanian it is normal to say "dvi varnos (pl.) - two crows" instead of "dvi varni (du.)".
Adjectives, pronouns, and numerals are declined for number, gender, and case to agree with the noun they modify/substitute. With a set of special pronominal forms, as well as four degrees of comparison, Lithuanian adjectives, for example, have the total of 147 synthetic forms.
Baltic verbs are inflected for tense, mood, aspect, and voice. They also agree with the subject in person and number (not in all forms in modern Latvian). They also demonstrate moderate fusion and high irregularity with the old morpheme seams dimmed by further evolution.
The Slavic languages, including Russian, Polish, Macedonian, Czech, Slovak, Serbian, Croatian, Bosnian, Ukrainian, Bulgarian, and Slovenian among others, all make use of a high degree of inflection, typically having six or seven cases and three genders (however, the case system has disappeared almost completely in modern Bulgarian and Macedonian, except for the vocative).
Declensional endings depend on case (nominative, genitive, dative, accusative, locative, instrumental, vocative), number (singular, dual or plural), gender (masculine, feminine, neuter) and animacy (animate vs inanimate). Unusual in other language families, declension in most Slavic languages also depends on whether the word is a noun or an adjective. Slovenian and Sorbian languages use a rare third number, (in addition to singular and plural numbers) known as dual. In addition, in some Slavic languages, such as Polish, word stems are frequently modified by the addition or absence of endings, resulting in consonant and vowel alternation.
Arabic (اللغة العربية الفصحى, "Al-Luġah al-‘Arabiyyah al-Fuṣḥā"), or more precisely " Modern Standard Arabic (also called "Literary Arabic"), is a highly-inflected language. It uses a complex system of pronouns and their respective prefixes and suffixes for verb, noun, adjective and possessive conjugation. In addition, the system known as al-‘Irāb places vowel suffixes on each verb, noun, adjective, and adverb, according to its function within a sentence and its relation to surrounding words.[4]
The following table ([5]) is an example of present-tense case applications in Arabic:
Arabic regional dialects (e.g. Moroccan Arabic, Egyptian Arabic, Gulf Arabic), used for everyday communication, tend to have less inflection than the more formal Literary Arabic. For example, in Jordanian Arabic, the second- and third-person feminine plurals (أنتنّ /antunna/ and هنّ /hunna/) and their respective unique conjugations are lost and replaced by the masculine (أنتم /antum/ and هم /hum/).
The Uralic languages (comprising Finno-Ugric and Samoyedic) are agglutinative, following from the agglutination in Proto-Uralic. The largest languages are Hungarian, Finnish and Estonian, all European Union official languages. Uralic inflection is, or is developed from, affixing. Grammatical markers directly added to the word perform the same function as prepositions in English. Almost all words are inflected according to their roles in the sentence: verbs, nouns, pronouns, numerals, adjectives, and some particles.
Hungarian and Finnish, in particular, often simply concatenate suffixes. For example, Finnish talossanikinko "in my house, too?" consists of talo-ssa-ni-kin-ko. However, in the Finnic languages (Finnish, Estonian, Sami), there are processes which affect the root, particularly consonant gradation. The original suffixes may disappear (and appear only by liaison), leaving behind the modification of the root. This process is extensively developed in Estonian and Sami, and makes them also inflected, not only agglutinating languages. The Estonian accusative case, for example, is expressed by a modified root: maja →majja (historical form *majam).
Basque, a language isolate, is an extremely inflected language, heavily inflecting both nouns and verbs. A Basque noun is inflected in 17 different ways for case, multiplied by 4 ways for its definiteness and number. These first 68 forms are further modified based on other parts of the sentence, which in turn are inflected for the noun again. It is estimated that at two levels of recursion, a Basque noun may have 458,683 inflected forms.[6] Verb forms are similarly complex, agreeing with the subject, the direct object and several other arguments.
Excerpt from Wikipedia: http://en.wikipedia.org/wiki/Inflection 090803
Some of the major Eastern Asian languages (such as the various Chinese languages, Vietnamese, and Thai) are not overtly inflected, or show very little overt inflection (though they used to show more), so they are considered analytic languages (also known as isolating languages).
Japanese shows a high degree of overt inflection on verbs, less so on adjectives, and very little on nouns, but it is always strictly agglutinative and extremely regular. Formally, every noun phrase must be marked for case, but this is done by invariable particles (clitic postpositions). (Many grammarians consider Japanese particles to be separate words, and therefore not an inflection, while others consider agglutination a type of overt inflection, and therefore consider Japanese nouns as overtly inflected.)
The Chinese family of languages, in general, does not possess overt inflectional morphology. Chinese words generally comprise of one or two syllables, each of which corresponds to a written character and individual morpheme. Since most morphemes are monosyllabic in the Chinese languages, [7] Chinese is quite resistant to inflectional changes; instead, Chinese uses lexical means for achieving covert inflectional transparency.
While European languages more often use overt inflection to mark a word's function in a sentence, the Chinese languages tend to use word order as a grammatical marking system. Whereas in English the first-person singular nominative "I" changes to "me" when used in the accusative - that is, when "I" is the object of a verb - Chinese simply uses word order to mark such a distinction. An example from Mandarin: 我給了他一本書 (wǒ gěile tā yī běn shū) 'I gave him a book'. Here 我 (wǒ) means 'I' and 他 (tā) means 'him'. However, 'He gave me a book' would be: 他給了我一本書 (tā gěile wǒ yī běn shū). 我 (Wǒ) and 他 (Tā) simply change places in the sentence to indicate that their case has switched: there is no overt inflection in the form of the words. In classical Chinese, pronouns were overtly inflected as to case. However, these overt case forms are no longer used; most of the alternative pronouns are considered archaic in modern Mandarin Chinese. Classically, 我 (wǒ) was used solely as the first person accusative. 吾 (Wú) was generally used as the first person nominative. [8]
Auxiliary languages, such as Esperanto, Ido, and Interlingua have comparatively simple inflectional systems.
In Esperanto, nouns and adjectives are inflected for case (nominative, accusative) and number (singular, plural), according to a simple paradigm without irregularities. Verbs are not inflected for person or number, but they are inflected for tense (past, present, future) and mood (indicative, infinitive, conditional, jussive). They also form active and passive participles, which may be past, present or future. All verbs are regular. (See main article on Esperanto grammar.)
Ido has a different form for each verbal tense (past, present, future, volitive and imperative) plus an infinitive, and both a present and past participle. There are though no inflections for person or number and all verbs are regular.
Nouns are marked for number (singular and plural), and the accusative case may be shown in certain situations, typically when the direct object of a sentence precedes its verb. On the other hand, adjectives are unmarked for gender, number or case (unless they stand on their own, without a noun, in which case they take on the same desinences as the missing noun would have taken). The definite article "la" ("the") remains unaltered regardless of gender or case, and also of number, except when there is no other word to show plurality. Pronouns are identical in all cases, though exceptionally the accusative case may be marked, as for nouns.
Interlingua, in contrast with the Romance languages, has no irregular verb conjugations, and its verb forms are the same for all persons and numbers. It does, however, have compound verb tenses similar to those in the Romance, Germanic, and Slavic languages: ille ha vivite, "he has lived"; illa habeva vivite, "she had lived". Nouns are inflected by number, taking a plural -s, but rarely by gender: only when referring to a male or female being. Interlingua has no noun-adjective agreement by gender, number, or case. As a result, adjectives ordinarily have no inflections. They may take the plural form if they are being used in place of a noun: le povres, "the poor".
UKT: End of Wikipedia article
wiki-inflect-fn01: For example, gender-neutral languages only have covert gender, i.e. semantically-implied genderness. wiki-inflect-fn01b
wiki-inflect-fn02: For example, in English cats versus cat, the affix -s expresses overtly an underlying category and, in speech recognition by actual speakers, the noun cat thus marked permits to uncover the grammatical relation in which the noun cat is embedded. wiki-inflect-fn02b
wiki-inflect-fn03: Uninflected words do not need to be lemmatized in linguistic descriptions or in language computing. On the other hand, inflectional paradigms (such as sing, sang, sung, sings, singing, singer, singers, song, songs, songstress, songstresses in English) need to be analyzed according to criteria uncovering the underlying lexical stem (here s*ng-), the accompaning functional items (-i-, -a-, -u-, -s, -ing, -er, -o-, -stress, -s) and their functional categories. wiki-inflect-fn03b
^
4. A Reference Grammar of Modern Standard Arabic, Karin C. Ryding (2005)
^
5.
http://islambase.co.uk/index.php?option=com_content&task=view&id=18&Itemid=172
^
6. Agirre et al., 1992
^
7. Norman, p. 84.
^
8. Norman, p. 89.
From Wikipedia: http://en.wikipedia.org/wiki/Afro-Asiatic 101207
The Afroasiatic languages constitute a language family with about 375 living languages[2] and more than 350 million speakers spread throughout North Africa, the Horn of Africa, and Southwest Asia, as well as parts of the Sahel, and East Africa. The most widely spoken Afroasiatic language is Arabic, with 230 million speakers (all the colloquial varieties).[3] In addition to languages now spoken, Afroasiatic includes several ancient languages, such as Ancient Egyptian, Biblical Hebrew, and Akkadian.
The term "Afroasiatic" (often now spelled as Afro-Asiatic) was coined by Maurice Delafosse (1914). It did not come into general use until it was adopted by Joseph Greenberg (1950) to replace the earlier term "Hamito-Semitic", following his demonstration that Hamitic is not a valid language family. The term "Hamito-Semitic" remains in use in the academic traditions of some European countries. Some authors now replace "Afro-Asiatic" with "Afrasian", or, reflecting an opinion that it is more African than Asian, "Afrasan". Individual scholars have called the family "Erythraean" (Tucker 1966) and "Lisramic" (Hodge 1972).
UKT: More in the Wiki article.
Go back Afr-Asia-lang-note-b
The Austro-Asiatic languages are a large language family of Southeast Asia, also scattered throughout India and Bangladesh. The name comes from the Latin word for "south" and the Greek name of Asia, hence "South Asia". Among these languages, only Khmer, Vietnamese, and Mon {mwun} have a long established recorded history, and only Vietnamese and Khmer have official status (in Vietnam and Cambodia, respectively). The rest of the languages are spoken by minority groups. Ethnologue identifies 168 Austro-Asiatic languages. These are traditionally divided into two families, Mon-Khmer and Munda. Two recent classifications have abandoned Mon-Khmer as a valid node, although this is tentative and not generally accepted.
Austro-Asiatic languages have a disjunct distribution across India, Bangladesh and Southeast Asia, separated by regions where other languages are spoken. It is widely believed that the Austro-Asiatic languages are the autochthonous languages of Southeast Asia and the eastern Indian subcontinent, and that the other languages of the region, including the IE , Kradai, Dravidian, Austronesian, and Sino-Tibetan languages, are the result of later migrations of people.
UKT: More in Wiki article.
Go back Aus-Asia-lang-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Finite_verb 090801
A finite verb is a verb that is inflected for person and for tense according to the rules and categories of the languages in which it occurs. Finite verbs can form independent clauses, which can stand by their own as complete sentences.
The finite forms of a verb are the forms where the verb shows tense, person or number. Non-finite verb forms have no person or number, but some types can show tense.
• Finite verb forms include: I go, she goes, he went
• Non-finite verb forms include: to go, going, gone
In the Indo-European languages (such as English), only verbs in certain moods are finite. These include:
• the indicative mood (expressing a state of affairs);
e. g., "The bulldozer demolished the restaurant," "The leaves were yellow and stiff."• the imperative mood (giving a command);
e. g., "Come here!", "Be a good boy!"• the subjunctive mood (typically used in dependent clauses);
e. g., "It was required that we go to the back of the line." (The indicative form would be "went".)• the optative mood (expressing a wish or hope)
Verb forms that are not finite include:
• the infinitive
• the participles
(e. g., "The broken window...", "The wheezing gentleman...")• the gerund
(e. g., "I like swimming.")• the gerundive
• the supine
It might seem that every grammatically complete sentence or clause must contain a finite verb. However, sentences lacking a finite verb were quite common in the old Indo-European languages. The most important type of these are nominal sentences . [1]
Another type are sentence fragments described as phrases or minor sentences. In Latin and some Romance languages, there are a few words that can be used to form sentences without verbs, e.g.:
Latin : ecce,
Portuguese : eis,
French : voici and voilà
Italian : ecco,
all of these translatable as here ... is or here ... are.
Some interjections can play the same role. Even in English, a sentence like Thanks for your help! has an interjection where it could have a subject and a finite verb form (compare I appreciate your help!).
UKT: End of Wikipedia article
Go back finite-verb-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Grammatical_category 090813
UKT: This article listed the following 18 as grammatical categories:
01. Animacy 02. Aspect
03. Case 04. Clusivity
05. Definiteness 06. Degree of comparison
07. Evidentiality
08. Focus
09. Gender
10. Mood
11. Noun class 12. Number
13. Person 14. Polarity
15. Tense 16. Topic 17. Transitivity
18. Voice
A grammatical category is a semantic distinction which is reflected in a morphological paradigm. Grammatical categories can have one or more exponents. For instance, the feature [number] has the exponents [singular] and [plural]. The members of one category are mutually exclusive; a noun cannot be marked for singular and plural at the same time, nor can a verb be marked for present and past at the same time. Exponents of grammatical categories are often expressed in the same position or 'slot' (prefix, suffix, enclitic, etc.). An examples for this are the Latin cases, which are all suffixal: rosa, rosae, rosae, rosam, rosā. ("rose", in nominative, genitive, dative, accusative, ablative)
For example, in English, the grammatical number of a noun such as bird in:
is either singular or plural, which is expressed overtly by the absence or presence of the suffix -s. Furthermore, the grammatical number is reflected in verb agreement, where the singular number triggers is, and the plural number, are.
Grammatical categories are often expressed by affixes, but clitics and particles are also common.
Go back gram-categ-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Isolating_language 090802
In morphological typology (in linguistics), an isolating language (in fact the most extreme case of an analytic language) is any language in which words are composed of a single morpheme. This is in contrast to a synthetic language which can have words composed of multiple morphemes.
Although historically languages were divided into three basic types (isolating, flectional, agglutinative), these traditional morphological types are best divided into two distinct parameters:
1. morpheme-per-word ratio
2. degree of fusion between morphemes
An isolating language can thus be defined as a language that has a one-to-one correspondence between word and morpheme. To illustrate, the English word-form
boy
- is a single word (namely boy) consisting of only a single morpheme (also boy). This word-form would then have a 1:1 morpheme-word ratio. The English word-formantiestablishment
- is a single word-form consisting of three morphemes (namely, anti-, establish, -ment). This word-form would then have a 3:1 morpheme-word ratio.
Languages that are considered to be isolating have a tendency for all words to have a 1:1 morpheme-word ratio. Because of this tendency, these languages are said to "lack morphology" since every word would not have an internal compositional structure in terms of word pieces (i.e. morphemes) — thus they would also lack bound morphemes like affixes. Isolating languages use independent words while synthetic languages tend to use affixes and internal modifications of roots for the same purpose.
The morpheme-per-word ratio should be thought of as a scalar category ranging from low morpheme-per-word ratio (near 1.0) on the isolating pole of the scale to a high morpheme-per-word ratio on the other pole. Languages with a tendency to have morpheme-per-word ratios greater than 1.0 are termed synthetic. The flectional (or fusional) and agglutinative types of the traditional typology can then be considered subtypes of synthetic languages which are distinguished from each other according to the second degree-of-fusion parameter.
Isolating languages are especially common in Southeast Asia, and examples are Vietnamese[1] [2] and classical Chinese (as distinct from modern Chinese languages) [3]. Outside China, the majority of mainland Southeast Asian languages are isolating languages with the exception of Malay. Mainland Southeast Asia is home to many of eastern Asia's analytic language families including Tibeto-Burman, Kradai, Hmong-Mien, and Mon-Khmer. Even some Austronesian languages in the region, such as Cham, are more isolating than the rest of their respective family. Burmese, Thai, Khmer, Lao and Vietnamese are all major isolating languages spoken in mainland southeast Asia.
Since words are not marked by morphology showing their role in the sentence, word order tends to carry a lot of importance in isolating languages. For example, Chinese makes use of word order to show subject–object relationships. Chinese (of all varieties) is perhaps the best-known analytic language. To illustrate:
As can be seen, comparing the Chinese sentence to the English translation, while English is fairly isolating, it contains a synthetic feature, in the use of the bound morpheme -s (a suffix) to mark plurality. Note that "my" in the English translation is not composed of two morphemes, as may be wrongly supposed by comparing with the Chinese translation, but is a one morpheme word that conveys the same meaning as two one morpheme words in the Chinese translation.
Verb tense can also be implied with adverbs:
Similarly, in Burmese, whose word order is subject-object-verb [UKT: SOV], sentence constructs are isolating.
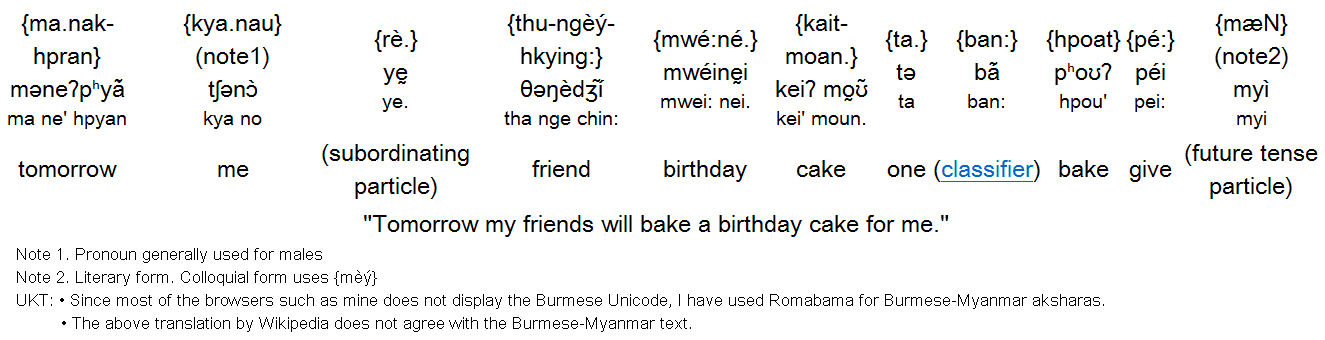
UKT: Not copied
The term analytic, referring to a morphological type, is synonymous with the term isolating in most contexts. However, it is possible to define analytic as referring to the expression of syntactic information via separate grammatical words instead of via morphology (with bound morphemes). Obviously, using separate words to express syntactic relationships would lead to a more isolating tendency while using inflectional morphology would lead to the language having a more synthetic tendency.
By definition, all isolating languages would also be analytic (in the sense defined in this section). However, it is possible that a language may have virtually no inflectional morphology but have a larger number of derivational affixes. For example, Indonesian has only two inflectional affixes but about 25 derivational morphemes. Indonesian can be considered slightly synthetic (and thus not isolating) and, in terms of the expression of syntactic information, mostly analytic.
UKT: The following excerpts are from Wikipedia http://en.wikipedia.org/wiki/Synthetic_language 090802
A synthetic language, in linguistic typology, is a language with a high morpheme-per-word ratio in one word. This linguistic classification is largely independent of morpheme-usage classifications (such as fusional, agglutinative, etc.), although there is a common tendency for agglutinative languages to exhibit synthetic properties.
Synthetic languages are frequently contrasted with isolating languages. It is more accurate to conceive of languages as existing on a continuum, with strictly isolating (consistently one morpheme per word) at one end and highly polysynthetic (in which a single word may contain as much information as an entire English sentence) at the other extreme. Synthetic languages tend to lie around the middle of this scale.
Synthetic languages are numerous and well-attested, the most commonly cited being Indo-European languages such as Spanish, Greek, Latin, German, Italian, Russian, Polish and Czech, as well as many languages of the Americas, including Navajo, Nahuatl, Mohawk and Quechua.
UKT: Wikipedia article has a note: "This article appears to contradict another article. Please see discussion on the linked talk page. Please do not remove this message until the contradictions are resolved."
UKT: End of Wikipedia article
Go back isolating-lang-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Marker 090801
In linguistics, a marker is a free or bound morpheme that indicates the grammatical function of the marked word or sentence. In analytic languages and agglutinative languages, markers are generally easily distinguished. In fusional languages and polysynthetic languages, this is often not the case. In the Latin word amo, "I love", for instance, the suffix -o marks indicative mood, active voice, first person, singular, present tense. Latin is a highly fusional language.
Markers should be distinguished from the linguistic concept of markedness. An unmarked form is the basic "neutral" form of word, typically used as its dictionary lemma, such as – in English – for nouns the singular (e.g. cat versus cats), and for verbs the infinitive (e.g. to eat versus eats, ate and eaten). Unmarked forms (like the nominative case in certain languages) tend to be less likely to have markers, but this is not true for all languages (compare Latin). Conversely, a marked form may happen to have a zero affix, like the genitive plural of some nouns in Russian.
• English: the suffix -s in dogs is a plural marker.
• Latin: the suffix -is in flaminis is a case marker, specifically a genitive marker.
• Spanish: the word hay in hay muchos libros en la biblioteca is an existential marker.
• Japanese: the Japanese particle が (ga) in ジョンがリーダーです。 [Jon ga riidaa desu.] 'John is the leader.' is a subject marker.
¤ UKT: Burmese-Myanmar colloquial:
the particle{ka.} in
{gywan ka. hkaung:hsaung hpric-tèý} 'John is the leader.' is a subject marker.
• Korean: the Korean particle 은/는 (eun, neun) is a topic marker, also known as a contrast particle.
UKT: End of Wikipedia article
Go back marker-note-b
Sir William Jones (28 September 1746 – 27 April 1794) was a English philologist
and student of ancient India, particularly known for his proposition of the existence
of a relationship among Indo-European languages. He was also the founder of the
Asiatic Society.
-- Wikipedia:
http://en.wikipedia.org/wiki/William_Jones 090724
Go back W-Jones-note-b
From Wikipedia: http://en.wikipedia.org/wiki/Word_class 090804
In grammar, a lexical category (also word class, lexical class, or in traditional grammar part of speech) is a linguistic category of words (or more precisely lexical items), which is generally defined by the syntactic or morphological behaviour of the lexical item in question. Common linguistic categories include noun and verb, among others. There are open word classes, which constantly acquire new members, and closed word classes, which acquire new members infrequently if at all.
Different languages may have different lexical categories, or they might associate different properties to the same one. For example, Japanese has as many as three classes of adjectives where English has one; Chinese, Korean and Japanese have measure words while European languages do not grammaticalize these units of measurement (a pair of pants, a grain of rice); many languages don't have a distinction between adjectives and adverbs, adjectives and verbs (see stative verbs) or adjectives and nouns , etc. Many linguists argue that the formal distinctions between parts of speech must be made within the framework of a specific language or language family, and should not be carried over to other languages or language families.
The classification of words into lexical categories is found from the earliest moments in the history of linguistics.[1] In the Nirukta, written in the 5th or 6th century BCE, the Sanskrit grammarian Yāska defined four main categories of words:[2]
1. nāma - nouns or substantives
2. ākhyāta - verbs :{a-hkya-ta.} PMDict-152
3. upasarga - pre-verbs or prefixes
4. nipāta - particles, invariant words (perhaps prepositions)
These four were grouped into two large classes: inflected (nouns and verbs) and uninflected (pre-verbs and particles).
A century or two later, the Greek scholar Plato wrote in the Cratylus dialog that "... sentences are, I conceive, a combination of verbs [rhēma] and nouns [ónoma]".[3] Another class, "conjunctions" (covering conjunctions, pronouns, and the article), was later added by Aristotle.
By the end of the 2nd century BCE, the classification scheme had been expanded into eight categories , seen in the Tékhnē grammatiké:
1. Noun: a part of speech inflected for case, signifying a concrete or abstract entity
2. Verb: a part of speech without case inflection, but inflected for tense, person and number, signifying an activity or process performed or undergone
3. Participle: a part of speech sharing the features of the verb and the noun
4. Article: a part of speech inflected for case and preposed or postposed to nouns (the relative pronoun is meant by the postposed article)
5. Interjection: a part of speech
6. Pronoun: a part of speech substitutable for a noun and marked for person
7. Preposition: a part of speech placed before other words in composition and in syntax
8. Adverb: a part of speech without inflection, in modification of or in addition to a verb
9. Conjunction: a part of speech binding together the discourse and filling gaps in its interpretation
The Latin grammarian Priscian (fl. 500 CE) modified the above eightfold system, substituting " interjection" for "article". It wasn't until 1767 that the adjective was taken as a separate class.[4]
Traditional English grammar is patterned after the European tradition above, and is still taught in schools and used in dictionaries. It names eight parts of speech: noun, verb, adjective, adverb, pronoun, preposition, conjunction, and interjection (sometimes called an exclamation).
Since the Greek grammarians of 2nd century BCE, parts of speech have been defined by morphological, syntactic and semantic criteria. However, there is currently no generally agreed-upon classification scheme that can apply to all languages, or even a set of criteria upon which such a scheme should be based.
Linguists recognize that the above list of eight word classes is drastically simplified and artificial.[5] For example, "adverb" is to some extent a catch-all class that includes words with many different functions. Some have even argued that the most basic of category distinctions, that of nouns and verbs, is unfounded,[6] or not applicable to certain languages.[7]
Common ways of delimiting words by function include:
• Open word classes:
¤ adjectives
¤ adverbs
¤ interjections
¤ nouns
¤ verbs (except auxiliary verbs)• Closed word classes:
¤ auxiliary verbs
¤ clitics
¤ coverbs
¤ conjunctions
¤ Determiners (articles, quantifiers, demonstrative adjectives, and possessive adjectives)}
¤ particles
¤ measure words
¤ adpositions (prepositions, postpositions, and circumpositions)
¤ preverbs
¤ pronouns
¤ contractions
¤ cardinal numbers
English frequently does not mark words as belonging to one part of speech or another. Words like neigh, break, outlaw, laser, microwave and telephone might all be either verb forms or nouns. Although -ly is an adverb marker, not all adverbs end in -ly and not all words ending in -ly are adverbs. For instance, tomorrow, fast, crosswise can all be adverbs, while early, friendly, ugly are all adjectives (though early can also function as an adverb).
In certain circumstances, even words with primarily grammatical functions can be used as verbs or nouns, as in "We must look to the hows and not just the whys" or "Miranda was to-ing and fro-ing and not paying attention".
End of Wikipedia article
Go back word-class-note-b
End of TIL file