Update:
2016-02-15 07:54 PM -0500
TIL
Phonation types: a cross-linguistic overview
phonat-type.htm
Mathew Gordon and Peter Ladefoged , Journal of Phonetics (2001) 29,
383-406,
www.linguistics.ucsb.edu/faculty/gordon/phonation.pdf 071212
Downloaded, set in HTML and edited
by
U Kyaw Tun (UKT) (M.S., I.P.S.T., USA)
and staff of Tun Institute of Learning
(TIL) . Not for sale. No copyright. Free
for everyone. Prepared for students and
staff of TIL Research Station,
Yangon, MYANMAR :
http://www.tuninst.net ,
www.romabama.blogspot.com
index.htm |
Top
HV-indx.htm
This file has sound files: <))
Abstract
01.
Introduction
02.
Cross-linguistic distribution of phonation contrasts
02.01.
Voiced vs. voiceless contrasts (vd. and vl. nasals with sound clips)
02.02.
Breathy voice
02.03.
Creaky voice
02.04.
Glottal stop
03.
Allophonic non-modal phonation
04.
Issues in the timing of non-modal phonation
04.01.
Timing of non-modal phonation in vowels
04.02.
Timing of non-modal phonation in consonants
04.03.
Auditory motivations for timing of non-modal phonation
05.
Phonetic properties associated with phonation types
05.01.
Periodicity
05.02.
Acoustic intensity
05.03.
Spectral tilt : creak in Burmese
05.04.
Fundamental frequency
05.05.
Formant frequencies
05.06.
Duration
05.07.
Aerodynamic properties :
 {gying:hpau:} and
{gying:hpau:} and
 {wa.}
{wa.}
06.
Conclusions
Acknowledgments
References
Appendix: Languages discussed in the text with phonation contrasts
Passages of interest:
•
Jitter values [{a-periodicity ?}] are higher during creaky phonation
than other phonation types, as found for Burmese.
•
Breathiness is characterized by increased spectral noise,
particularly at higher frequencies. [{example given: Newar}]
• Breathy phonation is associated with a decrease in overall
acoustic intensity
in many languages [{example given: Gujarati}]
• We can
use the glottis in totally unexpected ways
UKT note
•
Mpi language
•
Loudness and intensity
• ǃXóõ language
Differences in phonation type signal important linguistic
information in many languages, including contrasts between
otherwise identical lexical items and boundaries of
prosodic constituents.
[UKT ¶]
Phonation differences can be classified along a continuum
ranging from voiceless, through breathy
voiced, to regular, modal voicing, and then on
through creaky voice to glottal closure.
Cross-linguistic investigation suggests that this phonation
continuum can be defined in terms of a recurring set
of articulatory, acoustic, and timing properties.
Nevertheless, there exist several languages whose
phonation contrasts do not neatly fall within
the phonation categories defined by other
languages. -- Available online 26 Feb 2002 [{Abstr. from:
http://www.sciencedirect.com/
E-mail:
mgordon@linguistics.ucsb.edu }]
UKT:
This article deals mainly with three phonations:
creaky, modal, and breathy, of which creaky
 {a.} and modal
{a.} and modal
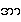 {a} are of interest to us. The term 'non-modal'
usually means 'creaky' and 'breathy'. See the
downloaded pdf file. -- UKT before 2004
{a} are of interest to us. The term 'non-modal'
usually means 'creaky' and 'breathy'. See the
downloaded pdf file. -- UKT before 2004
The term 'breathy' associated with Gujarati is always disturbing to me. Please
note what a Western phonetician "hears" is not the way a native Gujarati
speaker from India would hear it. What Gordon & Ladefoged had termed
'breathy' seems to me 'modal'. For BEPS, I will stick to the continuums:
creaky
{a.} अ ; modal
{a} आ ; emphatic
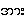 {a:}
{a:}
creaky
 {aa.} ;
modal
{aa} ; emphatic
{a:}
{aa.} ;
modal
{aa} ; emphatic
{a:}
Now to incorporate Skt-Dev, I must include another creaky,
 {a:.} अः . I have come to this conclusion after going through Gayatri Mantra
in Skt-Dev, where
{a:.} अः . I have come to this conclusion after going through Gayatri Mantra
in Skt-Dev, where
 {na:.}
नः 'the personal pronoun possessive' was emphasized. From the meaning it is
equal to
{na:.}
नः 'the personal pronoun possessive' was emphasized. From the meaning it is
equal to
 {ngaa.}.
I am also told that Mon-Myan also has this glyph.
{ngaa.}.
I am also told that Mon-Myan also has this glyph.
Contents of this page
Cross-linguistic phonetic studies have yielded several insights
into the possible states of the glottis.
People can control the glottis so that they produce speech
sounds with not only regular voicing vibrations at a range of different pitches,
but also harsh, soft, creaky, breathy and a variety of other phonation types.
These are controllable variations in the actions of the glottis,
not just personal idiosyncratic possibilities or involuntary pathological actions.
What appears to be an uncontrollable pathological voice quality for one person
might be a necessary part of the set of phonological contrasts for someone else.
For example, some American English speakers may have a very breathy voice
that is considered to be pathological, while Gujarati speakers need
a similar voice quality to distinguish the word /ba̤ɾ/
meaning ‘outside’ from the word /baɾ/ meaning ‘twelve’
(Pandit 1957, Ladefoged 1971). Likewise, an American English speaker
may have a very creaky voice quality similar to the one employed
by speakers of Jalapa Mazatec to distinguish the word /já̰/
meaning ‘he wears’ from the word /já/ meaning ‘tree’
(Kirk et al. 1993). As was noted some time ago, one person's voice disorder
might be another person's phoneme (Ladefoged 1983).
Contents of this page
Ladefoged (1971) suggested that there might be a continuum of
phonation types, defined in terms of the aperture between the arytenoid
cartilages, ranging from voiceless (furthest apart), through breathy voiced, to
regular, modal voicing, and then on through creaky voice to glottal closure
(closest together). This continuum is depicted schematically in Fig. 1.
 [{Click to see original}]
[{Click to see original}]
Although this is somewhat of an oversimplification, there
nevertheless appears to be a linguistic continuum that can be characterized
using these terms as an ordered set. Sections 2.1-2.4 explore some of the ways
in which languages exploit this phonation continuum. Throughout the discussion,
a number of languages with different types of phonation contrasts will be
mentioned. The names of all of these languages are summarized in an Appendix,
along with some additional basic information about each language: genetic
affiliation, where spoken, references, and type of phonations contrasted.
Contents of this page
The majority of languages employ two points along the phonation
continuum in making contrasts: voiced [{vd}] and voiceless [{vl}] sounds. This
contrast is particularly common among stop consonants and is exploited in a
number of widely-spoken languages, such as English, Japanese, Arabic and
Russian. The minimal pair wrangle with a voiced /g/ vs. rankle
with a voiceless /k/ illustrates the contrast between vd and vl stops in
English. In a smaller set of languages, the vd vs. vl contrast is found in
sonorants. For example, Burmese, Hmong, Klamath, and Angami have a voiced
vs. voiceless contrast among the nasals. Sample words illustrating this contrast
in Burmese are given in Table 1. [{p01end}]
Table 1. Vd. and Vl. nasals in Burmese.
Click here
to see the original table.

UKT: What Ladefoged has termed the "voiceless nasals" are a special
case of "secondary articulation" involving <h>.
There are no basic voiceless nasals in Burmese, however by forming
 {ha.hto:} medial we can get "voicelessness".
{ha.hto:} medial we can get "voicelessness".

Burmese-Myanmar readers would notice that Ladefoged's
representations fail to differentiate between the 3 registers of
Burmese-Myanmar. For IPA transcripts I have used the suprasegmentals:
#1.
{a.} /ă/
#2.
{a} /a/
#3.
{a:} /aː/
UKT: The following and the accompanying sound clips are from: Vowels and
Consonants, by P. Ladefoged,
http://hctv.humnet.ucla.edu/departments/linguistics/VowelsandConsonants/vowels/chapter12/burmese.html
080312
(Sound clips downloaded from Vowels and Consonants. You can also go
online to listen to them.)

Velar:
vl.: 'borrow'
 {ngha:}
<))
(sound clip: ngha3.aif)
{ngha:}
<))
(sound clip: ngha3.aif)
vd.: 'fish'
 {nga:}
<))
(sound clip: nga3.aif)
{nga:}
<))
(sound clip: nga3.aif)
Palatal:
vl.: 'considerate'
 {Ñha}
<))
(sound clip: nyha2.aif)
{Ñha}
<))
(sound clip: nyha2.aif)
vd.: 'right' (direction)
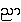 {Ña} <))
(sound clip: nya2.aif)
{Ña} <))
(sound clip: nya2.aif)
Dental:
vl.: 'nasal'
 {nha} <))
(sound clip: nha2.aif)
{nha} <))
(sound clip: nha2.aif)
vd.: 'pain'
 {na} <))
(sound clip: na2.aif)
{na} <))
(sound clip: na2.aif)
Bilabial:
vl.: 'from'
 {mha.}
<))
(sound clip: mha1.aif)
{mha.}
<))
(sound clip: mha1.aif)
vd.: 'lift up'
 {ma.}
<)) (sound clip: ma1.aif)
{ma.}
<)) (sound clip: ma1.aif)
UKT: In the Dentals, the basic akshara is
 {na.} which undergoes a change in shape to
{na.} which undergoes a change in shape to
 {na.} (short leg) when the medial is formed. The glyph
{na.} (short leg) is never used alone: it is only used in conjuncts.
Remember the medial is conjunct which can be pronounced.
{na.} (short leg) when the medial is formed. The glyph
{na.} (short leg) is never used alone: it is only used in conjuncts.
Remember the medial is conjunct which can be pronounced.
No language appears to make a clear voicing distinction in
vowels, though it is common, as in Japanese, for phonologically voiced vowels to
devoice in certain contexts such as in final position and when adjacent to
voiceless consonants (see Gordon 1998 for a cross-linguistic survey of vowel
devoicing).
Contents of this page
Another point on the phonation continuum exploited
by certain languages (far fewer in number than languages
which have voiceless sounds) is breathy voice.
Breathy phonation is characterized by vocal cords
that are fairly abducted (relative to modal and
creaky voice) and have little longitudinal tension
(see Ladefoged 1971, Laver 1980, and Ní Chasaide
and Gobl 1995 for discussion of the articulatory settings
characteristic of breathy phonation); this results
in some turbulent airflow through the glottis and
the auditory impression of “voice mixed in with breath”
(Catford 1977:99). ¶UKT

Certain languages contrast breathy voiced and regular modal
voiced sounds. Some of these languages, e.g. Hindi, Newar, Tsonga,
make this contrast among their nasals. Words illustrating the breathy vs. modal
voiced contrast in Newar appear in Table 2.
UKT:
My interest in Newar is because of a suggestion by a Myanmar monk that they might
be the "relatives" of Gautama Buddha, and because it is a
Tibeto-Burman language. I expect that, being of the same linguistic group as
Burmese-Myanmar, the way the consonants and vowels are articulated would be
similar if not the same.
The following is from Wikipedia, 071213:
The Newar or Newah are the indigenous group of Nepal's Kathmandu valley.
Newars are a linguistic community with multiple ethnicity, race (Mongolian,
Aryan, Austro-Dravidian) and faith, bound together by a common language.
The following is from Wikipedia, 071214:
Nepal Bhasa (नेपाल भाषा, also
known as Newah Bhaye and Newari) is one of the major
languages of Nepal. It is one of roughly five hundred Sino-Tibetan languages,
and belongs to the Tibeto-Burman branch of this family. It is the only
Tibeto-Burman language to be written in the Devanāgarī script. It is spoken
mainly by the Newars, who chiefly inhabit the towns of the Kathmandu Valley.
Although Nepal Bhasa is classified as a Sino-Tibetan language, it has been
greatly influenced by the Indo-Aryan languages.
Waveforms and spectrograms illustrating the breathy vs. modal
voiced contrast for two of these Newar words (uttered in isolation) appear in
Fig.2, with the modal voiced nasal on the left and the breathy voiced one on the
right. The waveforms are excerpted sections from the modal voiced and breathy
voiced nasals, respectively, with the time of the excerpt labeled on the x-axis
of the waveforms. [{p02end}]

The waveform for the breathy voiced nasal is characterized by a
fair amount of noisy energy which contributes a relatively jagged appearance to
the waveform and diminishes the clarity of individual pitch pulses. In
comparison, the modal voiced nasal is not marked by this turbulence and has
relatively well-defined pitch pulses. One of the more salient features
differentiating modal and breathy voiced nasals in the spectrograms is the
visually well-defined nasal-to-vowel transition characteristic of the modal
voiced nasal (at about 130 milliseconds) but not the breathy voiced nasal (at
about 150 milliseconds). In fact, breathiness persists throughout the vowel
following the breathy voiced nasal, resulting in increased formant bandwidths
relative to the modal voiced vowel in the spectrogram on the left. In addition,
the breathy voiced nasal has some high frequency noise not present in the modal
voiced nasal. The aperiodic energy characteristic of breathy nasals in Newar, as
seen in the waveform and, to a lesser extent, in the spectrogram, in Fig.2, is a
general feature of breathiness in other languages discussed below (see also the
discussion of the acoustic correlates of breathiness in section 5).
As it turns out, Newar also makes a breathy vs. modal voiced
contrast in their stops. Languages with contrastively breathy voiced obstruents
are relatively rare cross-linguistically, although they are common in Indo-Aryan
and other languages spoken in Asia, e.g. Hindi, Maithili, Telugu, in addition to
Newar (see Ladefoged and Maddieson 1996 for further examples).
UKT:
Since Hindi is related to Sanskrit the language of the Brahmins
it may be considered to be an Indo-European
(the term "Indo-Aryan" is now considered in
some circles as "racist" and should be avoided).
However, Newar in spite of its usage of Devanagari script
is related to Magadhi Prakrit and Pali Prakrit.
The following is from Wikipedia 071214
Prakrit (also spelt Pracrit)
(Skt-Dev:prākṛta
प्राकृत
(from pra-kṛti प्रकृति),
"original, natural, artless, normal, ordinary, usual",
i.e. "vernacular", in contrast to
saṃskṛtā "excellently made",
both adjectives
elliptically referring to vāk "speech")
refers to the broad family of the Indic languages and
dialects spoken in ancient India. The Prakrits became literary languages,
generally patronized by kings identified with the Kshatriya caste
[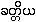 {hkût~ti.ya.} is not a "caste" -- it is a class.
They are the rulers, whereas the Brahmins were scholars
and scribes in the employ of {hkût~ti.ya.}],
but were regarded as illegitimate by the Brahmin orthodoxy.
The earliest extant use of Prakrit are the inscriptions of Asoka,
emperor of Northern India, and while the various Prakrit languages
are associated with different patron dynasties,
with different religions and different literary traditions,
none of them were at any time an informal "mother tongue"
in any area of India.
{hkût~ti.ya.} is not a "caste" -- it is a class.
They are the rulers, whereas the Brahmins were scholars
and scribes in the employ of {hkût~ti.ya.}],
but were regarded as illegitimate by the Brahmin orthodoxy.
The earliest extant use of Prakrit are the inscriptions of Asoka,
emperor of Northern India, and while the various Prakrit languages
are associated with different patron dynasties,
with different religions and different literary traditions,
none of them were at any time an informal "mother tongue"
in any area of India.
Some languages contrast breathy and modal voicing in their
vowels rather than consonants. Gujarati, which was mentioned earlier in
the introduction, is one such language. Representative pairs illustrating this
contrast appear in Table 3. (We will see waveforms and spectrograms illustrating
breathy voiced vowels in the discussion of Jalapa Mazatec and San Lucas Quiaviní
Zapotec in section 2.3) [{p03end}]

Contents of this page
Another type of phonation along the continuum in Fig.1 is creaky
voice, which contrasts with modal voice in many languages and with both modal
voice and breathy voice in other languages. Creaky phonation (also termed vocal
fry) is typically associated with vocal folds that are tightly adducted but open
enough along a portion of their length to allow for voicing (Ladefoged 1971,
Laver 1980, Ní Chasaide and Gobl 1995). The acoustic result of this laryngeal
setting is a series of irregularly spaced vocal pulses that give the auditory
impression of a “rapid series of taps, like a stick being run along a railing” (Catford
1964:32). Like the contrast between breathy and modal voiced among obstruents,
contrasts between creaky and modal voice are also relatively rare in obstruents,
though Hausa and certain other Chadic languages make such a contrast for stops.
The creaky stops in these languages are implosives and involve larynx lowering
as well as a creaky voice quality (see Ladefoged and Maddieson 1996 for
discussion).
Some languages contrast creaky and modal voicing among their
sonorants. This type of contrast is particularly common in Northwest American
Indian languages, e.g. Kwakw’ala, Montana Salish, Hupa, and Kashaya Pomo, among
many others. Representative words illustrating the creaky vs. modal voiced
contrast among nasals in Kwakw’ala (Boas 1947) appear in Table 4.

Fig.3 contains (in the top figure) a waveform and spectrogram
for a word (uttered in isolation) with three creaky voiced nasals in Kwakw’ala:
one occurs word-initially and the others after vowels. The waveform is excerpted
from the transition from the vowel preceding the creaky /m̰/
into the nasal itself. The waveform and spectrogram on the bottom illustrate for
comparative purposes modal voiced nasals occurring in the same language; the
waveform is from the modal voiced /m/. Differences in phonation type are
indicated in the phonetic transcription below the spectrograms in Fig.3
(and in subsequent spectrograms throughout the paper). [{p04end}]

 [{p05end}]
[{p05end}]
Looking at the waveforms, the creaky phonation is characterized
by irregularly spaced pitch periods and decreased acoustic
intensity relative to
modal phonation. Furthermore, there are fewer pitch periods per second in the
creaky token than in the modal one (particularly at the beginning of the
waveform up to 660 milliseconds when creak is strongest), indicating a lowered
fundamental frequency for the creaky nasal. These properties differentiating
creaky and modal voice are discussed further in section 5. The spectrogram on
the left indicates that creak is realized primarily at the beginning of the
creaky voiced nasals, visually reflected in increased distance between the
vertical striations reflecting pitch pulses, before modal voicing commences in
the latter portion of the nasals (indicated by modal voiced nasals in the
transcription below the spectrogram). The localization of creak to the beginning
of sonorants is a common timing pattern in languages with creaky voiced
sonorants (see section 4.2 for further discussion of the timing issues involved
in the realization of creaky voicing associated with sonorants.) Of particular
interest in Fig.3 are the creaky voiced pitch periods at the beginning of the
word-initial nasal in the spectrogram on the left, as word-initial creaky nasals
are comparatively rare in languages of the world (see section 4.2 for
discussion).
Creaky voicing is also found among vowels in certain languages,
including some languages which also use breathy voice to create a three-way
phonation contrast. Table 4 contains words illustrating the three-way contrast
between modal voiced, breathy voiced, and creaky voiced vowels in Jalapa Mazatec.
Spectrograms illustrating each of the three vowel types in Jalapa Mazatec
(from words uttered in isolation) appear in Fig.4.

Both the breathy voiced and the creaky voiced vowel are
characterized by decreased intensity in the waveform, as well as a lowered
fundamental frequency relative to the modal voiced vowel. In addition, the
breathy voiced vowel is marked by substantial turbulent energy which makes it
difficult to discern individual pitch pulses. As Silverman (1997) points out,
creakiness and breathiness tend not to be co-extensive with entire vowels in
Jalapa Mazatec. It is thus apparent from the spectrograms that the breathy phase
of the breathy vowel is largely localized to the first portion of the vowel. In
the breathy token in Fig.4, there is even a short portion of the vowel during
which phonation temporarily ceases as the larynx opens too wide for vocal fold
vibration to continue. In the creaky voiced vowel, creakiness is most pronounced
during the middle of the vowel, as reflected in the widely spaced vertical
striations reflecting lowered fundamental frequency (210 to 260 milliseconds).
It is also interesting to note that both the breathy and creaky vowels have
greater overall duration than their modal voiced counterparts. This additional
length associated with nonmodal vowels in Jalapa Mazatec is shared with other
languages (see section 5 for discussion). [{p06end}]

 [{p07end}]
[{p07end}]
A similar three way contrast between modal, breathy voiced, and
creaky voiced vowels is also found in San Lucas Quiaviní Zapotec (Munro and
Lopez 1999). Words (uttered in isolation) illustrating the modal vs. breathy vs.
creaky contrast in this language appear in Table 5.

Representative waveforms and spectrograms of some of these words
as uttered by a female speaker appear in Fig. 5. [{p08end}]

 [{p09end}]
[{p09end}]
The waveform for breathy voice shows the same noisiness and
reduced intensity characteristic of breathy voice in Newar (figure 2) and
Jalapa Mazatec (figure 4). Creakiness is associated with less frequent pitch
periods which are very irregular in their duration. From the spectrogram it is
clear that the breathy exemplar becomes progressively more breathy and thus
noisier throughout the vowel culminating in a completely voiceless offset. Note
that the modal vowel also ends somewhat breathy, most likely because the words
were said in isolation where the vowel is in utterance-final position, a common
environment for allophonic breathiness (see section 3). Like the breathy vowel,
the creaky vowel starts off fairly modal before non-modal phonation commences.
In the spectrogram for the creaky vowel, the irregular pitch periods indicative
of creak are particularly noticeable at the end of the vowel, which culminates
in a glottal stop. It is interesting to note that another speaker of San Lucas
Quiaviní Zapotec from whom data have been collected, a male, sustains creaky
phonation throughout the entire duration of the phonemically creaky vowel,
rather than localizing the creakiness to the latter portion of the vowel.
Conversely, the female speaker whose spectrograms appear in Fig.5 tends to have
noticeably breathier vowels than the male speaker. Gender dependent differences
of this sort, particularly increased breathiness for female speakers, have also
been observed in languages with allophonic rather than contrastive non-modal
phonation, including English (e.g. Henton and Bladon 1985, Klatt and
Klatt 1990, Hanson and Chuang 1999).
Certain languages employ voice qualities which resemble
creaky voice in involving increased constriction in the laryngeal area, but
which do not neatly fall under the rubric of creaky voice. For example,
Mpi has
a tense phonation type which clearly differs from creaky phonation in other
languages, though it shares certain properties with creaky voice (such as
increased spectral tilt; see section 5 for discussion of phonetic correlates of
phonation differences). Furthermore, Bruu has contrasts that might be described
as involving stiff vs. slack vocal folds. But the stiffness is not the same as
that in creaky voice of the kind used in Jalapa Mazatec, nor does the slackness
sound like breathy voice in Gujarati. The stiffness seems to include not
only some compression of the glottis, but also increased tension of the
pharyngeal walls. This could be classified as a creaky voice, with a ‘helping
feature’ (Stevens, Keyser & Kawasaki, 1986). In addition, certain vowels in
!Xóõ
employ a voice quality which is typically referred to as “strident” in the
literature (Ladefoged and Maddieson 1996). Traill (1985) has given a good
description of this voice quality, including x-ray pictures of his own
pronunciation of the sound. (His language consultants attest to the high quality
of his pronunciation.) It has a narrowing above the glottis that involves the
aryepiglottic fold [{authors' spelling: "aryeppiglottic fold"}]
that affects the vibration of the true vocal folds. Strident
vowels are associated with irregular noisy vibrations and higher first and
second formant values due to the pharyngeal constrictions associated with the
movement of the aryepiglottic fold and backing of the epiglottis
(Ladefoged and Maddieson 1996).
Contents of this page
Before concluding discussion of the nature of linguistic
phonation contrasts, a few words about the fifth step along Ladefoged’s
continuum of phonation types are in order. This fifth step, complete glottal
closure, entails an absence of vocal fold vibration, as occurs in the middle of
the English interjection uh-oh. Glottal stops like the one occurring in
this English example are quite common in languages of the world often
contrasting with oral stops, unlike in English where glottal stop is
noncontrastive. Often phonemic glottal stops are realized as creaky
phonation on neighboring sounds rather than with complete glottal closure (Ladefoged
and Maddieson 1996: 75).
Contents of this page
Thus far, we have only considered languages in which phonation
differences are used contrastively. Non-modal phonation types also commonly
arise as allophonic variants of modal phonation in certain contexts. Segmentally
conditioned allophonic non-modal phonation on vowels is extremely common in the
vicinity of consonants that are not produced with modal phonation. For example,
allophonic breathiness is characteristically found on vowels adjacent to /h/ and
allophonic creak is often associated with vowels adjacent to glottal stop, with
languages differing in the duration [{p10end}] of this allophonic non-modal
phonation (see Blankenship 1997). Final voiceless stops in certain varieties of
English also trigger a short creaky phase on the end of the immediately
preceding vowel. In many languages, particularly those of the Pacific Northwest,
e.g. Hupa, Quileute, Yana, Takelma (Sapir 1912), allophonic non-modal phonation
occurs on vowels preceding stops (subject to certain prosodic restrictions in
some languages; see section 4.1), breathiness before voiceless stops and creak
before ejectives. In Chitimacha (Swadesh 1934), underlying glottalized stops are
realized as preglottalized stops in syllable-final position.
Non-modal phonation, especially creaky voice, is commonly used
cross-linguistically as a marker of prosodic boundaries, either initially and/or
finally, as, for example, in Swedish (Fant and Kruckenberg 1989), English
(Lehiste 1979, Kreiman 1982, Dilley et al. 1996), Finnish (Lehiste 1965), Czech
(Lehiste 1965), and Serbo-Croatian (Lehiste 1965). Vowel-initial words
frequently have a creaky onset in many languages, where creakiness is more
common at the beginning of larger prosodic units than smaller ones (Pierrehumbert
and Talkin 1992, Dilley et al. 1996) and more frequent in accented than
unaccented syllables (Pierrehumbert 1995, Dilley et al. 1996). There are
numerous other factors in addition to accent and constituency, e.g. grammatical
category, frequency of occurrence, segmental context, etc., which influence the
likelihood of non-modal phonation occurring (see Dilley et al. 1996 for an
overview of some of the relevant literature on prosodically conditioned
glottalization).
Contents of this page
Thus far in our discussion of segmental phonation contrasts, we
have not talked about the timing of phonation events. In many cases, sounds
which are described as being realized with non-modal phonation do not extend
their non-modal phonation over an entire segment. Rather, non-modal phonation is
often confined to a portion of the sound and/or spills over onto an adjacent
sound. An especially common timing feature of non-modal phonation is its
confinement to contexts in which its potentially detrimental effects on other
perceptually important properties are minimized.
Contents of this page
Among contrastively non-modal voiced vowels, creakiness and
breathiness are localized to a portion of the vowel in Jalapa Mazatec (see
spectrograms in Fig.4; also, Silverman et al. 1995, Blankenship 1997). Silverman
(1995, 1997) suggests a link between the confinement of non-modal phonation to a
portion of vowels and the use of contrastive tone in Jalapa Mazatec. He
hypothesizes, and then corroborates for breathy phonation in later experimental
work (Silverman to appear) that, because non-modal phonation influences
fundamental frequency (see discussion in section 5), it adversely affects the
ability of vowels to support tonal contrasts. By preserving modal phonation on a
portion of the vowel, there is sufficient space remaining on which to realize
tonal contrasts effectively, particularly since the overall duration of
non-modal vowels is substantially longer than that of modal vowels. Thus,
preservation of non-modal phonation on a portion of the vowel does not come at
the expense of rendering information about voice quality less salient.
Confinement of non-modal phonation to portions of vowels is not
only a feature of languages that use tone contrastively. In Hupa (Golla 1970,
1977, Gordon 1998), which does not have contrastive tone, creaky voice and
breathy voice spread from syllable-final ejectives and voiceless obstruents,
respectively, onto only the latter half of a preceding long vowel and not onto
short vowels at all. By asymmetrically spreading non-modal phonation in this
way, there is always a portion of the vowel which is characterized by modal
phonation, the entire vowel in the case of short vowels and the first half of
long vowels. A similar spreading asymmetry conditioned by vowel length is found
in Quileute (Powell and Woodruff 1976), with the added restriction that
non-modal phonation does not spread onto unstressed long vowels. It is thus only
those vowels that are presumably longest, namely the stressed long vowels, that
support non-modal phonation in Quileute and only for a portion of their
duration. One might hypothesize that the Hupa and Quileute patterns stem from a
detrimental effect of non-modal phonation on not only the ability to realize
tonal information, as shown by [{p11end}] Silverman (to appear), but also on the
ability to realize place information in vowels. In support of this hypothesis,
non-modal phonation types often alter formant structure (see section 5). The
additional length associated with breathy vowels in languages like Kedang (Samely
1991) could also reflect an attempt to enhance the overall salience of place
information in the face of the reduced salience at any one point in time due to
non-modal phonation.
Contents of this page
Non-modal phonation realized on consonants displays interesting
timing patterns. We discuss here some of the timing properties characteristic of
the most common type of non-modally voiced consonants: creaky voiced
sonorants. Creaky voiced sonorants, also termed “glottalized” sonorants,
show an overwhelming cross-linguistic tendency to realize their creak early in
the sonorant, often sharing it with the immediately preceding vowel, an as yet
poorly understood timing preference presumably driven by auditory considerations
(see Kingston 1985, Silverman 1995, Steriade 1999). These “pre-creaked”
sonorants are reported in a number of North American Indian languages, including
Montana Salish (Flemming et al. 1994), Klamath (Barker 1964, Blevins 1993),
Yokuts (Newman 1944), Coast Tsimshian (Dunn 1979), Nuuchahnulth (Shank and
Wilson 2000), Nez Perce (Aoki 1970a), Kalispel (Vogt 1940), Heiltsuk (Rath
1981), Ineseño Chumash (Applegate 1972), Squamish (Kuipers 1967). In Fig.3,
we saw examples of pre-creaked sonorants in Kwakw’ala.
In a number of other languages, the location of the creak is
dependent on the context in which the creaky voiced sonorant occurs. In the most
typical case, glottalized sonorants realize their creak primarily at the
beginning (often shared with the preceding vowel) in prevocalic position, but
shift their creak towards the end when they do not precede a vowel. This timing
asymmetry is found, for example, in Caddo (Chafe 1976), Shuswap (Kuipers 1974),
Chitimacha (Swadesh 1934), Bella Coola (Nater 1984). In Kashaya Pomo (Buckley
1990, 1992), glottalized sonorants are restricted to preconsonantal and final
(i.e. coda), positions, where their creak is realized near the end. This timing
pattern is consistent with the tendency for glottalized sonorants in many
languages to realize their creak at the beginning in positions that are not
prevocalic. Typically, context-dependent timing differences of the type just
discussed are implicitly described in primary sources with reference to isolated
words; it is conceivable that investigation of words in phrasal contexts could
reveal further interesting timing properties.
Hupa (Golla 1970, 1977, Gordon 1996) has turned what once was a
predictable timing asymmetry between preglottalized nasals in prevocalic
position and postglottalized nasals in preconsonantal and final position into a
morphologically contrastive timing difference due to a chronologically later
apocope process (loss of word-final vowels) affecting final short vowels. Thus,
preglottalized sonorants appear in root-final position of stems which
historically ended in a short vowel (which still surfaces before
consonant-initial clitics), while postglottalized nasals occur in
consonant-final stems. Because of final vowel loss, we thus find pairs of words
differing in whether they end in a pre- or post-glottalized nasal. In practice,
this contrast typically does not rely solely on the timing of glottalization,
since nasals originally occurring before a vowel are alveolar whereas those not
followed by a vowel are velar. However, place assimilation affecting final
nasals can turn a velar nasal to an alveolar one, thereby eliminating the
place difference between pre and postglottalized nasals. Fig.6 contains
spectrograms (from words uttered in isolation) illustrating pre- (on the left)
and post- (on the right) glottalized nasals in Hupa (with an accompanying place
difference). [{p12end}]
UKT: Remember that velars in Bur-Myan are: {ka.} {ga.} {nga.},
and alveolars are: {ta.} {da.} {na.}. And so, "turn a velar nasal to an
alveolar" means turning the sound of {nga.} to that of {na.}.

In the case of the preglottalized nasal on the left, creak is
realized primarily on the end of the preceding vowel (450 to 550 milliseconds).
In the postglottalized nasal at the end of the word on the right, creak is
realized at the end of the velar nasal (210 to 230 milliseconds).
Contents of this page
A unifying feature of languages which asymmetrically realize
creak at the beginning of prevocalic sonorants and at the end of sonorants in
other positions is their avoidance of creaky voice on transitions from the
sonorant into the following vowel. Shifting non-modal phonation away from the CV
transition is plausibly driven by considerations similar to those hypothesized
above to account for the dispreference for non-modal phonation to be coextensive
with entire vowels. Transitions from consonants into an adjacent vowel,
particularly those into a following vowel, provide important information about
place and manner of the consonant (see experimental data in Malécot 1956, 1958,
Recasens 1983, Kurowski and Blumstein 1984, Manuel 1991, inter alia, and its
implications for phonological neutralization patterns in Jun 1995, 1996). By
realizing non-modal phonation at the beginning of a prevocalic sonorant, the
transitions into a following vowel, which are perceptually most valuable, remain
modal voiced and thus clearer from an auditory standpoint. In positions that are
not prevocalic, i.e. in final or preconsonantal position, sonorants are adjacent
to a vowel on only one side, the left side. By shifting the glottalization to
the end of the sonorant in these contexts, the sole consonant-vowel transition
is realized with modal voicing and thus retains maximal perceptual salience.
Other languages display asymmetries in the timing of glottalized
sonorants based on vowel length and stress in ways that fit in with the
hypothesis that non-modal phonation adversely affects the perception of place
information. In Saanich (Montler 1986), creaky voiced sonorants share their
creak with a preceding vowel if it is stressed, otherwise with the following
vowel. In Cowichan (Bianco 1999), glottalized sonorants in intervocalic position
realize their glottalization at the beginning if the preceding vowel is full,
i.e. long, otherwise at the end. (In preconsonantal and final position,
glottalization is consistently realized at the end of the sonorant, a pattern
similar to one reported above for Caddo, Shuswap, Chitimacha, Bella Coola, Hupa,
and Kashaya Pomo.) Similarly, [{p13end}] creak migrates onto stressed vowels in Shuswap (Kuipers 1974). These timing patterns are amenable to the same
explanation claimed earlier to drive the timing patterns seen in non-modal
vowels: non-modal phonation is realized in environments where its effect on
other perceptually significant properties is minimized.
Clearly, however, it is not only the realization of information
about place and manner which is relevant in accounting for timing patterns
associated with non-modal phonation. In many languages, e.g. Nez Perce (Aoki
1970b), Hupa (Golla 1970), Thompson Salish (Thompson and Thompson 1992), Yokuts
(Newman 1944), glottalized sonorants either do not occur or are rare in
word-initial position or after another consonant. As Steriade (1999) suggests,
this phonological restriction likely results from the rigid language-specific
phonetic preference for realizing creaky voice at the beginning of sonorants,
combined with a requirement that creak be realized at least partially on an
adjacent vowel, thereby enhancing the salience of the creaky phonation. Because
a sonorant in wordinitial or postconsonantal position has no preceding vowel on
which to realize its creak, creaky sonorants are banned in these positions
in many languages.
In contrast to languages that restrict glottalized sonorants in
word-initial and postconsonantal position, Nuuchahnulth (Shank and Wilson 2000)
restricts word-final and preconsonantal glottalized sonorants. This phonological
restriction is presumably also driven from a combination of auditorily driven
requirements on timing, albeit a slightly different combination than is
responsible for the restriction against word-final and postconsonantal sonorants
seen in other languages. In Nuuchahnulth, glottalized sonorants must realize
their creak at the beginning, while simultaneously preserving modal voiced
transitions into at least one adjacent vowel. In final and preconsonantal
positions, both requirements cannot be satisfied; the result is a phonological
ban on glottalized sonorants in these positions.
As this section’s preliminary hypotheses suggest,
cross-linguistic exploration of phonation timing patterns is in its relative
infancy. As a greater amount of phonetic and phonological data on the
distribution and realization of phonation contrasts comes to light, we will be
in a better position to describe and explain the rich set of timing patterns
observed in languages of the world.
Contents of this page
Ladefoged and Traill (1980) and Ladefoged (1983), following
suggestions from Ken Stevens (p.c.), showed that phonation differences can be
quantified through a number of phonetic measurements, even if certain
physiological or auditory properties defining these phonation types are harder
to define. Much work on linguistic voice quality (e.g. Fischer-Jørgensen 1967,
Bickley 1982, Maddieson and Ladefoged 1985, Huffman 1987, Traill and Jackson
1988, Ladefoged et al. 1988, Thongkum 1988, Kirk et al. 1993, Blankenship 1997,
etc.) has focused on discovering these phonetic dimensions along which contrasts
in phonation type are realized. This body of work has revealed a number of
cross-linguistic similarities in the realization of phonation differences, but
has also indicated some differences. Some of the properties used to describe
phonation differences have been discussed in the context of the examples in
section 2. We summarize here some of these results, focusing on differences
between modal voice and the two most common non-modal phonation types,
breathy voice and creaky voice.
There are a number of acoustic, articulatory, and aerodynamic
properties that potentially distinguish creaky and breathy phonation (as well as
other non-modal phonation types) from each other and from modal phonation.
Languages differ in the precise set of properties used to distinguish these
phonation types, though there is generally some agreement between languages in
how phonation contrasts are signaled. We focus here on some acoustic and
aerodynamic characteristics defining phonation differences in naturally
occurring non-pathologic speech (see Gerratt and Kreiman this volume for
discussion of phonation differences in vocal pathologies). These include
periodicity (section 5.1), intensity (section 5.2), spectral tilt (section 5.3),
fundamental frequency (section 5.4), formant frequencies (section 5.5), duration
(section 5.6), and airflow (section 5.7). [{p14end}] Further discussion of the
physiological characteristics of various laryngeal settings can be found in Catford (1964), Ladefoged (1971), Laver (1980), Hirose (1995), and Ní Chasaide
and Gobl (1995).
Contents of this page
Creaky phonation is characteristically associated with
aperiodic glottal pulses. This feature of creak was evident in the waveforms
and spectrograms of creak in figures in section 2. The degree of aperiodicity in
the glottal source can be quantified by measuring the “jitter”,
the variation in the duration of successive fundamental frequency cycles. Jitter
values are higher during creaky phonation than other phonation types, as found
for Burmese by Javkin and Maddieson (1985) and Jalapa Mazatec (Kirk et al.
1993). Breathiness is characterized by increased
spectral noise, particularly at higher frequencies, as we saw earlier in
waveforms and spectrograms of breathy sounds in Newar, Jalapa Mazatec,
and San Lucas Quiaviní Zapotec. This noise reflects the presence of substantial
random noise during breathy vowels (particularly at high frequencies) due to the
persistent leakage of air through the glottis (see Ladefoged et al. 1988 for !Xóõ
and Blankenship 1997 for Jalapa Mazatec and Chong).
Contents of this page
Breathy phonation is associated with a decrease in overall
acoustic intensity in many languages, e.g. Gujarati (Fischer-Jørgensen
1967), Kui and Chong (Thongkum 1988), Tsonga (Traill and Jackson 1988), Hupa
(Gordon 1998). Creakiness also triggers a reduction in intensity (relative to
modal phonation) in certain languages, e.g. Chong (Thongkum 1988) and Hupa
(Gordon 1998). The reduction in intensity characteristic of both creaky and
breathy vowels relative to modal ones was evident in the waveforms and
spectrograms in section 2.
Contents of this page
One of the major acoustic parameters that reliably
differentiates phonation types in many languages is spectral tilt, i.e. the
degree to which intensity drops off as frequency increases. Spectral tilt
can be quantified by comparing the amplitude of the fundamental to that of
higher frequency harmonics, e.g. the second harmonic, the harmonic closest to
the first formant, or the harmonic closest to the second formant. Spectral tilt
is characteristically most steeply positive for creaky vowels and most steeply
negative for breathy vowels. In other words, the fall off in energy at higher
frequencies is least for creaky voice and most for breathy voice. Subtracting
the amplitude of the fundamental from the amplitude of higher harmonics thus
yields the greatest values for creaky vowels and the smallest values for breathy
vowels, with intermediate values for modal vowels. Spectral tilt reliably
differentiates phonation types in a number of languages, including Jalapa
Mazatec (Kirk et al. 1993, Silverman et al. 1995), which contrasts creaky,
breathy, and modal vowels, !Xóõ (Bickley 1982, Ladefoged 1983, Jackson et al.
1988), which distinguishes between breathy and modal vowels (as well as a third
type of phonation, strident, discussed in section 2.3), Gujarati
(Fischer-Jørgensen 1967), which contrasts breathy and modal vowels, Kedang (Samely
1991), which contrasts modal and breathy vowels, Hmong (Huffman 1987), which
distinguishes breathy and modal vowels, Tsonga (Traill and Jackson 1988), which
contrasts breathy and modal nasals, some minority languages of China (Jingpho,
Haoni, Wa, Yi) examined by Maddieson and Ladefoged (1985), which contrast
a “tense” phonation somewhat different from creaky phonation with a more modal
phonation type, and, finally, Mpi, which also contrasts tense and non-tense (or
“lax”) phonation.

Different measures of spectral tilt do not always behave
uniformly in differentiating phonation types in a single language. In Mpi, which
uses tone contrastively, Blankenship (1997) found interactions between tone
level and measurements of spectral tilt. The amplitude difference between the
fundamental and the second harmonic was a more reliable indicator of phonation
type for high tone than for either mid or low tone, whereas the amplitude
difference between the fundamental and [{p15end}] the harmonic closest to
the second formant was more useful for differentiating phonation contrasts in
mid and low tone vowels than in high tone vowels.
Differences in spectral tilt between creaky, breathy, and modal
vowels in San Lucas Quiaviní Zapotec are illustrated in Fig.7 by means of FFT
spectra from a male speaker.
UKT: The rime in the third word 'lets go of' is interesting:
/a̰ʔ/ is probably comparable to Bur-Myan {a.þût}. Here, all the three
f0, h2 and F1, have the same Hz.
In the creaky vowel, the amplitude of the second harmonic is
slightly greater than that of the fundamental. At the other extreme, in the
breathy vowel, the amplitude of the second harmonic is [{p16end}]
considerably less than that of the fundamental. The modal vowel occupies middle
ground between the creaky and breathy vowels: its second harmonic has slightly
less amplitude than the fundamental. Similar differences between phonation types
can be seen by comparing the amplitude of the harmonic closest to the first
formant relative to that of the fundamental. In the breathy vowel, the harmonic
closest to the first formant has much lower amplitude than the fundamental. In
the creaky vowel, on the other hand, the harmonic closest to the first formant
has much greater amplitude than the fundamental. The modal vowel is
intermediate, characterized by very similar amplitude values for the fundamental
and the first formant. Spectral tilt values, as defined by two measurements,
h2-f0 and F1-f0, thus form a continuum differentiating the three phonation types
of San Lucas Quiaviní Zapotec: breathy vowels have the greatest drop off (or
smallest increase depending on the particular measure) in energy as frequency
increases, while creaky vowels display the largest boost in energy as frequency
is increased.
Spectral tilt has been associated with various physiological
characteristics. Holmberg et al. (1995) found that intensity differences between
the fundamental and the second harmonic correlate with the percentage of the
glottal cycle during which the glottis is open (the open quotient): the less the
amplitude of the second harmonic relative to that of the fundamental, the
greater the open quotient. Stevens (1977) has suggested that a general measure
of spectral slope, quantified in terms of amplitude differences between the
fundamental and higher harmonics, correlates with the abruptness (or
gradualness) of vocal fold closure: the less the amplitude of higher harmonics
relative to that of the fundamental, the less abrupt the glottal closing
gesture. Both an increased open quotient and a less abrupt glottal closing
gesture are physiological correlates of breathiness (see Huffman 1987 on
breathiness in Hmong). Conversely, a decreased open quotient and a more
precipitous closing gesture are potentially associated with creakiness (see
Javkin and Maddieson 1985 on creak in Burmese). Consequently, it is not
surprising that both measures of spectral tilt (h2-f0 and F1-f0) often pattern
together in languages.
Contents of this page
Non-modal phonation types are commonly associated with lowering
of fundamental frequency, a tendency which was evident in earlier waveforms in
section 2 and in the spectra in Fig.7. Creaky voice is associated with lowered
fundamental frequency values (relative to modal phonation) in many languages,
synchronically or diachronically, e.g. Mam (England 1983), Northern Iroquoian
languages such as Mohawk, Cayuga, and Oneida (Chafe 1977, Michelson 1983,
Doherty 1993). It should, however, be noted that this lowering effect is not
universal, as certain languages have developed high tone as a reflex of glottal
constriction (see Hombert et al. 1979 for discussion). The historical
development of Athabaskan languages from proto-Athabaskan provides a nice
example of how glottalization can be associated with high tone in some languages
but with low tone in closely related languages (Leer 1979). Breathy phonation
appears to be more consistently associated with lowered tone in the majority of
languages (see Hombert et al. 1979 for an overview).
Contents of this page
Formant frequencies may also vary as a function of phonation
type. For example, Kirk et al. (1993) observe that frequency values for the
first formant are higher during creaky phonation than either breathy or
modal phonation in Jalapa Mazatec, which they speculate is due to a raising of
the larynx and concomitant shortening of the vocal tract during creaky voice.
Maddieson and Ladefoged (1985) also report raised first formant values for tense
vowels in Haoni. Conversely, Thongkum (1988) reports that breathiness is
associated with a lowering of the first formant in Chong, though she does not
observe this difference in the related languages Nyah Kur and Kui. Based on
observations of other scholars (Henderson 1952, Gregerson 1976), Thongkum
suggests that the lowering of the first formant during breathy phonation in
Chong might be attributed to larynx lowering; this explanation would fit in with
the suggestion of Kirk et al. (1993) that the opposite effect, the raising of
the first formant during creaky phonation, is an acoustic correlate of larynx [{p17end}]
raising. Samely (1991) also found that breathy vowels have lower first and
second formant values than modal vowels in Kedang, though it should be pointed
out that breathy vowels in this language are associated with increased
pharyngeal width which could contribute to the observed formant differences.
Contents of this page
Non-modal phonation types are in some languages, though not all,
associated with increased duration. This is not true of Hmong (Huffman 1987) and
is not true of the San Lucas Quiaviní Zapotec data in Fig.5. Breathy vowels are
substantially longer than modal vowels, however, in Kedang (Samely 1991) and
Jalapa Mazatec (Kirk et al. 1993, Silverman et al. 1995), and creaky vowels are
longer than modal vowels in Jalapa Mazatec (Kirk et al. 1993, Silverman et al.
1995). A related observation in keeping with the greater duration characteristic
of non-modal phonation types is that non-modal phonation may occur on
phonemic long vowels but not on phonemic short vowels in Hupa (Golla
1970, 1977, Gordon 1998). Quileute (Powell and Woodruff 1976) displays a similar
restriction, with the added proviso that the long vowels must be stressed to
support non-modal phonation (see section 4 for further discussion of duration
and timing issues relevant for non-modal phonation).
Contents of this page
Phonation contrasts also appear to be associated with
aerodynamic differences, at least as far as the limited amount of relevant data
show. Ladefoged and Maddieson’s (1985) study of four minority languages of China
(Jingpho, Wa, Yi, Haoni) shows that the tense vowels in the four
languages are generally associated with less airflow for a given subglottal
pressure than the lax vowels, suggesting that the tense vowels are associated
with a more constricted glottis that allows less air flow.
UKT: Jingpho and Wa are minority groups in Myanmar:
{gying:hpau:}
and {wa.}
Contents of this page
In summary, investigation of phonation differences is an
important area of research, as many languages employ distinctions which rely
solely on differences in voice quality. As we have seen, these distinctions may
involve two or more different phonation types and may affect consonants, vowels,
or both consonants and vowels. In addition, many other languages regularly use
non-modal phonation types as variants of modal voice in certain prosodic
contexts. Languages also differ in their timing of non-modal phonation relative
to other articulatory events in interesting ways, although there are certain
recurrent timing patterns and distributional restrictions which warrant
explanation.
Differences in phonation type can be signaled by a large number
of quantifiable phonetic properties in the acoustic, aerodynamic, and
articulatory domains, the last of which has been relatively unstudied due to the
invasive measurement techniques required. It is unlikely, however, that future
research will yield many truly universal observations about the range and
realization of phonation types in languages of the world. We can never know
whether some language in the past had or in the future will have a novel method
of using the vocal folds to make a linguistic contrast. The occurrence of
phonetic rarities such as the strident voice quality that occurs in !Xóõ
(section 2.3) and a few neighboring languages shows that
we can use the glottis in totally unexpected
ways. If the Xóõ did not exist, and someone had suggested that a sound of
this kind could be used in a language, scholars would probably have said that
this was a ridiculous notion. !Xóõ is an endangered language, and we are lucky
to have been able to hear these sounds. But who knows what other phonation types
could occur in a language?
Contents of this page
The authors wish to thank Stefanie Shattuck-Hufnagel for helpful
comments on earlier drafts of this paper, as well as participants at the 1999
Workshop on Non-modal Vocal Fold Vibration and Voice Quality (held in
conjunction with [{p18end}] the 14th International Conference of
Phonetic Sciences) for their insightful feedback on the presentation on which
this paper is based. Also, thanks to Felipe and Silvia Lopez for providing the
Zapotec material discussed in this paper, Pamela Munro for invaluable discussion
of the Zapotec data as well as crucial logistical assistance, for which we also
thank Melissa Epstein, Bruce Gerratt, and Jody Kreiman. Also, thanks to Greg
Brown for providing the Kwakw’ala data and to the speakers of the other
languages discussed in the text who so generously contributed material for the
paper. Finally, thanks to Melissa Epstein and Paul Barthmaier for their
assistance in analyzing the Zapotec data.
Contents of this page
• Aoki, H. (1970a). A note on glottalized consonants,
Phonetica 21, 65-75
• Aoki, H. (1970b). Nez Perce grammar. Berkeley: University of California
Press.
• Applegate, R. (1972). Ineseño Chumash grammar. University of
California, Berkeley Ph.D dissertation.
• Barker, M. (1964). Klamath grammar. Berkeley:
University of California Press.
• Benguerel, A. & Bhatia, T. K. (1980). Hindi stop consonants: an acoustic and
fiberscopic study. Phonetica 37, 134-48.
• Bianco, V. (1999). Weight-by-sonority in Cowichan. Ms. University of
California, Santa Barbara.
• Bickley, C. (1982). Acoustic analysis and perception of breathy vowels. In
Speech communication group working papers, pp. 71-82. Cambridge:
Massachusetts Institute of Technology.
• Blankenship, B. (1997). The time course of breathiness and laryngealization
in vowels. University of California, Los Angeles Ph.D. dissertation.
• Blevins, J. (1993). Klamath laryngeal phonology, International Journal of
American Linguistics 59, 237-280
• Boas, F. (1947). Kwakiutl grammar with a glossary of the suffixes,
edited by Helene Boas Yampolsky & Zelig Harris. Transactions of the American
Philosophical Society 37:3, 201-377.
• Buckley, E. (1990). Glottalized and aspirated sonorants in Kashaya. In M.
Langdon (Ed.), Papers from the 1990 Hokan-Penutian Workshop, pp. 75-91.
Carbondale, IL: Southern Illinois University.
• Buckley, E. (1992). Theoretical aspects of Kashaya phonology and morphology.
University of California, Berkeley Ph.D. dissertation. [Published by CSLI 1994]
• Catford, J. (1964). Phonation types: the classification of
some laryngeal components of speech production. In D. Abercrombie, D.B. Fry,
P.A.D. MacCarthy, N.C. Scott and J.L.M. Trim (Eds.), In honour of Daniel
Jones, pp. 26-37. London: Longmans.
• Catford, J. (1977). Fundamental problems in phonetics. Edinburgh:
Edinburgh University Press.
• Chafe, W. (1976). The Caddoan, Iroquoian, and Siouan languages [Trends
in Linguistics, State of the Art Reports 3]. The Hague: Paris.
• Chafe, W. (1977). Accent and related phenomena in the Five Nations Iroqouis
languages. In L. Hyman (Ed.), Studies in stress and accent [Southern
California Occasional Papers in Linguistics 4], pp.169-8. Los
Angeles: University of Southern California.
• Dilley, L., Shattuck-Hufnagel, S., & Ostendort, M. (1996).
Glottalization of word-initial vowels as a function of prosodic structure,
Journal of Phonetics 24, 423-44.
• Dixit, R. P. (1989). Glottal gestures in Hindi plosives, Journal of Phonetics
17, 213-37.
• Doherty, B. (1993). The acoustic-phonetic correlates of Cayuga word-stress.
Harvard University Ph.D. dissertation.
• Dunn, J. (1979). A reference grammar for the Coast Tsimshian language.
Ottawa: National Museums of Canada.
• England, N. (1983). A grammar of Mam, a Mayan language.
Austin: University of Texas Press.
• Fant, G. & Kruckenberg, A. (1989). Preliminaries to the study
of Swedish prose reading and reading style, Speech Transmission Laboratory—Quaterly
Progress and Status Report 2, pp. 1-83. Stockholm: Royal Institute of
Technology.
• Fischer-Jorgensen, E. (1967). Phonetic analysis of breathy (murmured) vowels
in Gujarati, Indian Linguistics 28, 71-139.
• Flemming, E., Ladefoged, P., & Thomason, S. (1994). Phonetic structures of
Montana Salish, UCLA Working Papers in Phonetics 87, 1-33.
• Golla, V. (1970). Hupa grammar. University of California, Berkeley
Ph.D. dissertation [{p19end}]
• Golla, V. (1977). A note on Hupa verb stems, International Journal of
American Linguistics 43(4), 355-8.
• Gordon, M. (1996). The phonetic structures of Hupa, UCLA Working Papers in
Phonetics 93, 164-87.
• Gordon, M. (1998). The phonetics and phonology of non-modal vowels: a
cross-linguistic perspective, Berkeley Linguistics Society 24,
93-105.
• Gregerson, K. (1976). Tongue-root and register in Mon-Khmer. In P. Jenner (Ed.),
Austroasiatic Studies I, pp. 323-66. Honolulu: University of Hawai’i.
• Hanson, H. and Chuang, E. (1999). Glottal characteristics of
male speakers: acoustic correlates and comparison with female data. Journal
of the Acoustical Society of America 106, 1064-77.
• Henderson, E. (1952). The main features of Cambodian pronunciation.
Bulletin of the School of Oriental and African Studies 14, 149-74.
• Henton, C.G., & Bladon, R.A.W. (1985). Breathiness in normal female speech:
Inefficiency versus desirability. Language & Communication, 5, 221-227.
• Hirose, H. (1995). Investigating the physiology of laryngeal structures. In W.
Hardcastle & J. Laver (eds.), The handbook of phonetic sciences, pp.
116-36. Cambridge, MA: Blackwells.
• Holmberg, E., Hillman, R., Perkell, J., Guiod, P., & Goldman, S. (1995).
Comparisons among aerodynamic, electroglottographic, and acoustic spectral
measures of female voice, Journal of Speech and Hearing Research 38,
1212-23.
• Hombert, J.-M., Ohala, J., &. W. Ewan. (1979). Phonetic explanations for the
development of tones, Language 55(1), 37-58.
• Huffman, M.K. (1987). Measures of phonation type in Hmong, Journal of the
Acoustical Society of America 81, 495-504.
• Javkin, H. & Maddieson, I. (1985). An inverse filtering study
of creaky voice. UCLA Working Papers in Phonetics 57, 115-25.
• Jun, J. (1995). Perceptual and articulatory factors in place assimilation:
An Optimality-theoretic approach. UCLA Ph.D dissertation.
• Jun, J. (1996). Place assimilation as the result of conflicting perceptual and
articulatory constraints, West Coast Conference on Formal Linguistics
14, 221-38.
• Kagaya, R. & Hirose, H. (1975). Fiberoptic, electromyographic
and acoustic analyses of Hindi stop consonants. Annual Bulletin of the
Research Institute of Logopedics and Phoniatrics 9, 27-46.
• Kingston, J. (1985). The phonetics and phonology of the timing of oral and
glottal events. University of California, Berkeley Ph.D. dissertation.
• Kirk, P. L.,Ladefoged, J., & Ladefoged, P. (1993). Quantifying acoustic
properties of modal, breathy and creaky vowels in Jalapa Mazatec. In A. Mattina
& T. Montler (Eds.), American Indian linguistics and ethnography in honor of
Laurence C. Thompson. Missoula, MT: University of Montana Press.
• Klatt, D.& Klatt, L. (1990). Analysis, synthesis, and perception of voice
quality variations among female and male talkers. Journal of Acoustical
Society of America, 87, 820-57.
• Kreiman, J. (1982). Perception of sentence and paragraph boundaries in natural
conversation. Journal of Phonetics 10, 163-175.
• Kuipers, A. (1967). The Squamish language: grammar, texts, dictionary.
The Hague: Mouton.
• Kuipers, A. (1974). The Shuswap language. The Hague: Mouton.
• Kurowski, K. & Blumstein, S. (1984). Perceptual integration of the murmur and
formant transitions for place of articulation in nasal consonants. Journal of
the Acoustical Society of America 76, 383-90.
• Ladefoged, P. & Maddieson, I. (1996). The sounds of the
world’s languages. Cambridge, MA: Blackwells.
• Ladefoged, P. (1971) Preliminaries to linguistic phonetics. Chicago:
University of Chicago.
• Ladefoged, P. (1983). The linguistic use of different phonation types. In D.
Bless & J. Abbs (Eds.), Vocal fold physiology: Contemporary research and
clinical issues (pp. 351-360). San Diego: College Hill Press.
• Ladefoged, P., & Traill, A. (1980). Phonological features and phonetic details
of Khoisan languages. In J. W. Snyman (Eds.), Bushman and Hottentot
Linguistic Studies 1979. Pretoria: University of South Africa. [{p20end}]
• Ladefoged, P. & Antoñanzas-Barroso, N. (1985). Computer measures of breathy
phonation. UCLA Working Papers in Phonetics 61, 79-86.
• Ladefoged, P., Maddieson, I., & Jackson, M. (1988). Investigating phonation
types in different languages. In O. Fujimura (Ed.), Vocal fold physiology:
voice production, mechanisms and functions, pp. 297-317. New York: Raven
Press.
• Laver, J. (1980). The phonetic description of voice quality.
Cambridge: Cambridge University Press.
• Leer, J. (1979), Proto-Athabaskan verb stem variation, part one: phonology.
Fairbanks: Alaska [Native Language Center Research Papers 1].
• Lehiste, I. (1965). Juncture. Proceedings of the 5th International Congress
of Phonetic Sciences, pp. 172-200.
• Lehiste, I. (1979). Sentence boundaries and paragraph boundaries—perceptual
evidence. In The Elements: a Parasession on Linguistic Units and Levels,
Chicago Linguistics Society 15, pp. 99-109.
• Maddieson, I & Ladefoged, P. (1985). ‘Tense’ and ‘lax’ in four
minority languages of China, Journal of Phonetics 13, 433-54.
• Malécot, A. (1956). Acoustic cues for nasal consonants: an experimental study
involving tapesplicing technique. Language 32, 274-84.
• Malécot, A. (1958). The role of releases in the identification of released
final stops, Language 34, 370-80.
• Manuel, S. (1991). Some phonetic bases for the relative malleability of
syllable-final versus syllableinitial consonants. Actes du XIIème Congres
International des Sciences Phonetiques, August 1991, pp.118-21.
• Michelson, K. (1988). A comparative study of Lake-Iroquoian accent.
Dordrecht: Kluwer.
• Montler, T. (1986). An outline of the morphology and phonology of Saanich,
North Straits Salish. Missoula, MT: University of Montana.
• Munro, P. & Lopez, F. (1999). Di’csyonaary X:tèe’n Dìi’zh Sah Sann Lu’uc.
Los Angeles: UCLA Chicano Studies Research Center.
• Nater, H. F. (1984). The Bella Coola language. Ottawa:
National Museums of Canada.
• Newman, S. (1944). Yokuts language of California. New York: Viking Fund
Publications in Anthropology.
• Newman, S. (1947). Bella Coola phonology. International Journal of American
Linguistics 13, 129-34.
• Ní Chasaide, A. & Gobl, C. (1995). Voice source variation. In W. Hardcastle &
J. Laver (eds.), The handbook of phonetic sciences, pp. 427-61.
Cambridge, MA: Blackwells.
• Pandit, P. (1957) Nasalization, aspiration and murmur in
Gujarati, Indian Linguistics 17, 165-72.
• Powell, J. & Woodruff, F. (1976). Quileute dictionary. Moscow, Idaho:
University of Idaho.
• Rath, J. (1981). A practical Heiltsuk-English dictionary,
with a grammatical introduction. Ottawa: National Museums of Canada.
• Recasens, D. (1983). Place cues for nasal consonants with special reference to
Catalan, Journal of the Acoustical Society of America 73, 1346-53.
• Samely, U. (1991). Kedang (Eastern Indonesia), some aspects
of its grammar. Hamburg: Helmut Buske Verlag.
• Sapir, E. (1912). The Takelma language of southwestern Oregon.
Republished in V. Golla (1990), The collected works of Edward Sapir
VIII, New York: Mouton de Gruyter.
• Shank, S. & Wilson, I. (2000). Acoustic evidence for as a glottalized
pharyngeal glide in Nuuchah-nulth. In S. Gessner & S. Oh (Eds.), Proceedings
of the Thirty-Fifth International Conference on Salish and Neighboring Languages,
pp. 185-197. Vancouver: University of British Columbia, Department of
Linguistics.
• Silverman, D. (1995). Phasing and recoverability. University of
California, Los Angeles Ph.D. dissertation. [Published by Garland 1997]
• Silverman, D. (1997). Laryngeal complexity in Otomanguean vowels, Phonology
14, 235-62.
• Silverman, D. (to appear). Pitch discrimination during breathy versus modal
phonation, Papers in Laboratory Phonology VI. Cambridge: Cambridge
University Press. [{p21end}]
• Silverman, D., Blankenship, B., Kirk, P., & Ladefoged, P. (1995). Phonetic
structures in Jalapa Mazatec, Anthropological Linguistics 37,
70-88.
• Steriade, D. (1999). Phonetics in phonology: The case of laryngeal
neutralization. UCLA Working Papers in Phonology 3, 25-146.
• Stevens, K. (1977). Physics of laryngeal behavior and larynx modes,
Phonetica 34, 264-79.
• Stevens, K. N.,Keyser, S. J., & Kawasaki, H. (1986). Toward a phonetic and
phonological theory of redundant features. In J. Perkell & D. Klatt (Eds.),
Invariance and variability in speech processes, pp. 426-449. Hillsdale, NJ:
Lawrence Erlbaum Associates.
• Swadesh, M. (1934). A phonetic study of Chitimacha, Language 10,
345-62.
• Thompson, L. & Thompson, M. T. (1992). The Thompson
language. Missoula, MT: University of Montana.
• Thongkum, T. (1988). Phonation types in Mon-Khmer languages. In O. Fujimura
(Ed.), Vocal fold physiology: voice production, mechanisms and functions,
pp. 319-334. New York: Raven Press.
• Traill, A. & Jackson, M. (1988). Speaker variation and phonation type in
Tsonga nasals, Journal of Phonetics 16, 385-400.
• Traill, A. (1985). Phonetic and phonological studies of !Xóõ Bushman.
Hamburg: Helmut Buske Verlag.
• Vogt, H. (1940) The Kalispel language, an outline of the
grammar with text, translations and dictionary. Oslo: J. Dybwad.
• Yadav, R. (1984). Voicing and aspiration in Maithili: a
fiberoptic and acoustic study. Indian Linguistics 45, 27-35. [{p22end}]
Contents of this page
Appendix: Languages discussed in the
text with phonation contrasts


 [{p23end}]
[{p23end}]

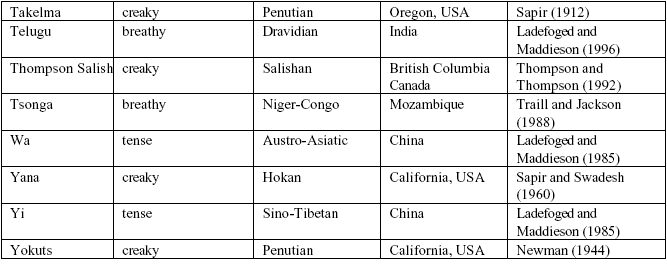
[{p24end}]
End of article.
Contents of this page
UKT note
From Wikipedia
http://en.wikipedia.org/wiki/Mpi_people 071214
The Mpi are an ethnic group of Thailand. There are about 1,500 Mpi in
the Nan and Phrae Provinces of Thailand. The Mpi came to Laos during the 18th
century from the Yunnan Province of China. They migrated shortly afterwards to
Thailand. They are of Lolo descent. Approximately 900 of the Mpi still
speak their Mpi language. Nearly all of the Mpi speak fluent Northern
Thai. Religion: Theravada Buddhism
Go back Mpi-lang-note-b
Contents of this page
From: Hyperphysics,
http://hyperphysics.phy-astr.gsu.edu/hbase/sound/loud.html 071214
Sound loudness is a subjective term describing the strength of the
ear's perception of a sound. It is intimately related to sound
intensity but can by no means be considered identical to intensity. The
sound intensity must be factored by the ear's sensitivity to the particular
frequencies contained in the sound. This is the kind of information contained in
equal
loudness curves for the human ear. It must also be considered that the ear's
response to increasing sound intensity is a "power of ten" or logarithmic
relationship. This is one of the motivations for using the decibel
scale to measure sound intensity. A general "rule of thumb"
for loudness is that the power must be increased by about a factor of ten to
sound twice as loud. To more realistically assess sound loudness, the ear's
sensitivity curves are factored in to produce a
phon
scale for loudness. The factor of ten rule of thumb can then be used to
produce the
sone
scale of loudness. In practical
sound
level measurement,
filter
contours such as the A, B, and C contours are used to make the measuring
instrument more nearly approximate the ear.
From: Hyperphysics,
http://hyperphysics.phy-astr.gsu.edu/hbase/sound/intens.html#c1 071214
Sound intensity is defined as the sound power per unit area. The usual
context is the measurement of sound intensity in the air at a listener's
location. The basic units are watts/m2 or watts/cm2 . Many
sound intensity measurements are made relative to a standard threshold of hearing intensity I0 :
I0 = 10-12 watts/m2 = 10-16
watts/cm2
The most common approach to sound intensity measurement is to use the decibel
scale:

Decibels measure the ratio of a given intensity I to the threshold of hearing
intensity , so that this threshold takes the value 0 decibels (0 dB). To assess
sound loudness, as distinct from an objective intensity measurement, the
sensitivity of the ear must be factored in.
Go back ntensity-note-b
Contents of this page
From: Wikipedia,
http://en.wikipedia.org/wiki/!X%C3%B3%C3%B5_language 071215
ǃXóõ is a Khoisan language with a very large number of phonemes, the
most of any known language. These include many clicks and vowel
phonations.
As of 2002 ǃXóõ is spoken by about 4,200 people worldwide. These are mainly
in Botswana (approximately 4,000 people), but some are in Namibia.
Go back Xoo-note-b
Contents of this page
End of TIL file
{kind=link}
{kind=link}