Update:
2021-02-10 05:23 AM -0500
TIL
Grammar of the Burman Language
CareyGram02.htm
From Grammar of the Burman Language,
by F. Carey, 1814.
-
https://books.google.co.nz/books?id=mmEOAAAAQAAJ&pg=PA1&redir_esc=y#v=onepage&q&f=false
201102
Downloaded copy in TIL HD-PDF and SD-PDF Libraries, and in TIL Bk-Cndl Online
Library
-
FCarey-GrammBurmanLang<Ô> /
Bkp<Ô> /
BkCnd<OL> (link chk 201103)
There are are 351 printed pages in the downloaded copies, but no TOC.
However, in -
https://books.google.fr/books?id=mmEOAAAAQAAJ 210112,
there is a Table des matières, which gives the book divided into 26 sections.
Downloaded and set in html and edited
by U Kyaw Tun (UKT) (M.S., I.P.S.T., USA), and staff of Tun Institute of Learning
(TIL).
Not for sale. No copyright. Free for
everyone. Prepared for students and
staff of TIL Research Station, Yangon, MYANMAR :
http://www.tuninst.net ,
www.romabama.blogspot.com
index.htm |
Top
BG-indx.htm
UKT 210202: To find what Carey had found and what he had missed, I have
constructed the following TOC:
Rimes of Simple Codas :
 {a.} -->
{a.} -->
 {ak};
{ak};
 {i.}
-->
{i.}
-->
 {aik} ;
{aik} ;
 {u.} -->
{u.} -->
 {oak};
{oak};
 {é} -->
{é} -->
 {ék} ;
{ék} ;
 {au:} -->
{au:} -->
 {auk};
{auk};
 {o} -->
{o} -->
 {eik}
{eik}
Ch01 : Section 03 :
(i) Syllables without Onset consonant and a Coda
: CVÇ with C = 0 and Ç = 1
--------------------- (ii) Syllables with a basic
Consonant as Onset and a Coda: CVÇ with C = 1 and Ç = 1
-------------------- (iii) Syllables with a medial
Consonant as Onset and a Coda: CVÇ with C = 2, 3 and Ç = 1
Of Monosyllables with a final Consonant [ e.g.
 {k}]
{k}]
§070 §071 §072
§073 §074
§075 §076 §077
Rimes with vowel /æ/
: CVÇ, where C=0:
{a.} -->
{ak}
Of final Consonants following the Vowel
{a.}/
{a.}
§078 §079
§080 §081 §082
§083
Rimes with vowel /i/
: CVÇ, where C=0:
{i.}
-->
{aik}
Of final Consonants following the Vowel
 {I.}/
{i.}
{I.}/
{i.}
§084
Rimes with vowel /u/
: CVÇ, where C=0:
{u.} -->
{oak}
Of a final Consonant after the Vowel
 {U.}/
{u.}
{U.}/
{u.}
§085
Rimes with vowel /é/ : CVÇ, where C=0:
{é} -->
{ék}
[Of a final Consonant after the Vowel
 {É}/
{é} : - missing in Carey]
{É}/
{é} : - missing in Carey]
Rimes with vowel /ɔ/
: CVÇ, where C=0:
{au:} -->
{auk}
Of final Consonants following Vowel
 {AU}/
{au}
{AU}/
{au}
§086
Rimes with vowel /o/
VÇ, where C=0:
{o} -->
{eik}
Of final Consonants following the Vowel
{o}
§087
Codas of row#1
§088
Controversial approximant w
§089
UKT notes
• Uvular Consonants
in Burmese, English, and Roman
Contents of this page
Chapter 01
Rimes of Simple Codas
{a.} -->
{ak};
{i.}
-->
{aik} ;
{u.} -->
{oak};
{é} -->
{ék} ;
{au:} -->
{auk};
{o} -->
{eik}
UKT210203: The following section is on Bur-Myan Syllable of canonical
structure CVÇ , where
C = Onset which can have values 0, 1, 2, 3,
V =
Nuclear vowel which may be the inherent vowel of Onset (never be 0, can be
1, 2), and,
Ç = Coda having values 0, 1 (for native Bur-Myan syllables), 2
(for imported syllables.
Section 03 :
(i) Syllables without Onset consonant and a Coda
: CVÇ with C = 0 and Ç = 1
--------------- (ii) Syllables with a basic
Consonant as Onset and a Coda: CVÇ with C = 1 and Ç = 1
-------------- (iii) Syllables with a medial
Consonant as Onset and a Coda: CVÇ with C = 2, 3 and Ç = 1
Of
Monosyllables with a final Consonant [ e.g.
{k}]
 UKT 210111: Carey did not realized that there is a fundamental difference
in syllables of English and Burmese. English syllables are of CVC type,
where the Onset C and Coda C are both mute letters.
UKT 210111: Carey did not realized that there is a fundamental difference
in syllables of English and Burmese. English syllables are of CVC type,
where the Onset C and Coda C are both mute letters.
The English syllable is pronounceable because of the nuclear V

 {Ñu-ka·li-þa·ra.}.
Eng-Latin belongs to script-to-speech
writing system known as Alphabet-Letter system. The basic unit of
this system is the mute Letter. e.g. K·T·P·N·M are: the letters k
/k/, t /t/, p /p/, n /n/, m /m/ - none of which
are associated with any vowels and hence mute.
{Ñu-ka·li-þa·ra.}.
Eng-Latin belongs to script-to-speech
writing system known as Alphabet-Letter system. The basic unit of
this system is the mute Letter. e.g. K·T·P·N·M are: the letters k
/k/, t /t/, p /p/, n /n/, m /m/ - none of which
are associated with any vowels and hence mute.
 To make the
English syllable pronounceable
you have to couple it with vowels such as short vowel «a» and long
vowel «ā».
To make the
English syllable pronounceable
you have to couple it with vowels such as short vowel «a» and long
vowel «ā».
With short vowel «a» we have: e.g. short syllables
«ka», «ta»,
«pa», «na», «ma» - which are known as tenuis-voiceless or simply tenuis
consonants. Unfortunately - unknown to most English speakers, English speech
lacks these tenuis sounds. What it has is the ordinary-voiceless or simply
voiceless consonants, which has an element of /h/ sound and is written
in IPA as /kʰ/ , /tʰ/, /pʰ/ . Bur-Myan has both tenuis and voiceless
consonants. Carey had to suffer for this defect in English in his work.
The Bur-Myan belongs to the script-to-speech writing system
known as Abugida system which I prefer to call Akshara-syllable
system. Of course, Carey could not have known this because the term
Abugida was introduced into Linguistics only after two centuries later.
Burmese syllable is of the type CVÇ, where the Onset C
is pronounceable and Coda Ç is a mute letter. The Coda consonant, Ç, has lost its
inherent vowel
 {mwé-hkûn þa·ra} due to the A'thut
{mwé-hkûn þa·ra} due to the A'thut
 {a·þût} "the vowel killer" shown by a
{a·þût} "the vowel killer" shown by a
 {tän-hkûn} "flag" above it. Its equivalent in Skt-Dev is the
Virama identified by the sign ् . Thus Bur-Myan
{tän-hkûn} "flag" above it. Its equivalent in Skt-Dev is the
Virama identified by the sign ् . Thus Bur-Myan
 {t} = Skt-Dev त् «t»
{t} = Skt-Dev त् «t»
The nuclear V
{Ñu-ka·li-þa·ra.} of the Bur-Myan syllable may be or may not be the inherent
vowel
{mwé-hkûn þa·ra} of the Onset akshara.
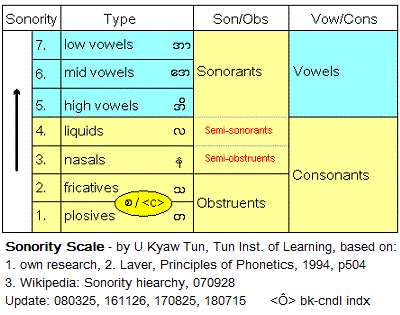 A second point Carey has missed is the two kinds of vowels of Bur-Myan:
except for the first pair
{a.}-
A second point Carey has missed is the two kinds of vowels of Bur-Myan:
except for the first pair
{a.}- {a}, all other pairs are different. They are Vowel-Letters, and Vowel-Signs
with
{a.}. The vowel V in CVÇ is always the vowel
{i},
{u.}
{é}
{au} - and not
{I.},
{a}, all other pairs are different. They are Vowel-Letters, and Vowel-Signs
with
{a.}. The vowel V in CVÇ is always the vowel
{i},
{u.}
{é}
{au} - and not
{I.},
 {U.}
{É}
{AU}. Native Bur-Myan syllables always use the short vowel and never long
vowels such as
{a},
{U.}
{É}
{AU}. Native Bur-Myan syllables always use the short vowel and never long
vowels such as
{a},
 {i},
{i},
 {u} .
{u} .
Whatever the case maybe, it is this nuclear V
{Ñu-ka·li-þa·ra.} that is "checked by the Coda Ç". Note the term "checking"
- it is not "killing".
Carey usually gives his example of "Of
Monosyllables with a final Consonant" as
{k} which is a poor example because its nasal consonant is semi-nasal
 {gna.}/
{gna.}/
 {ng.} with which English speakers as well as Sanskrit speakers are not
familiar. He should have chosen
{t} whose nasal is
{ng.} with which English speakers as well as Sanskrit speakers are not
familiar. He should have chosen
{t} whose nasal is
 {n} is a true-nasal with which both English and Sanskrit speakers are
familiar. Nasals are important because they stand between plosives
and vowels.
{n} is a true-nasal with which both English and Sanskrit speakers are
familiar. Nasals are important because they stand between plosives
and vowels.
Contents of this page
§070. A very great part of the Burman language
consists of monosyllables with a coda final consonant , which with its
preceding vowel is pronounced differently from its natural sound. [This is due
to "checking".]. Ex.
-
{ak} as in
 {kak} |
{kak} |
- [
 {ût} as in {kût} ]
{ût} as in {kût} ]
- [
 {ûp} as in
{ûp} as in
 {kûp} ]
{kûp} ]
UKT 210203: The Burmese syllable of the type CVÇ can have C = 0, 2, 3, Ç
= 0, 1 (for native syllables), or 0, 1, 2, (for imported syllables,
especially from English. The coda has a strong effect on the nuclear vowel
which becomes evident when P·T·K stop-consonants and M·N nasals, are compared:
-
{ûp} as in
{kûp};
-
{ût} as in
 {kût};
{kût};
-
{ak} as in
{kak}
-
 {ûm.} as in
{ûm.} as in
 {kûm};
{kûm};
 {ûn.
} as in {kûn.}
{ûn.
} as in {kûn.}
-
 {ûm} as in
{ûm} as in
 {kûm};
{kûm};
 {ûn} as in {kûn}
{ûn} as in {kûn}
-
 {ûm:} as in
{ûm:} as in
 {kûm};
{kûm};
 {ûn:} as in {kûn:}
{ûn:} as in {kûn:}
§071. These monosyllables consist either of a vowel
followed by a coda final consonant, or
of an onset
initial consonant (base simple or medial
compound [- not a conjunct] combined with a vowel and followed by a
final consonant. Ex.
-
{ût} or
{ûp};
-
 {kait} [or
{kait} [or
 {kaip}]
{kaip}]
-
 {kyoat},
{kyoat},
 {krwoat} .
{krwoat} .
UKT 210111: I've to ignore Carey's transcriptions, because he
seems to be following the pronunciation which he heard [with his L1 English
interfering what he heard]. For
{ût} or
{ûp}, he gives at meaning they are the same : they are
slightly different. To us spelling is more important than pronunciation.
UKT 210203: When the following §072 is analyzed using the Rimes of
Simple Codas
{a.} -->
{ak};
{i.}
-->
{aik} ;
{u.} -->
{oak};
{é} -->
{ék} ;
{au:} -->
{auk};
{o} -->
{eik}
we found that Carey has missed
{é} -->
{ék}.
§072. When the initial of
the monosyllable is a vowel, it is always combined
with the vowel
{a.} in the same manner as with a consonant. In this case the initial
{a.} is mute [Carey's mistake is based on "silent
letters" of English: as far as I know, Burmese
has no silent letters.], as may be seen in the following
sounds as:
[
{a.} -->]
{ak} [ Carey gives aet - saying a is mute],
 {ín},
{ín},
-
 {íc},
{íc},
 {æÑ},
{æÑ},
-
{ût},
{ûn},
{ûp},
{ûm},
 {èý},
{èý},
 {auO},
{auO},
[ {i.}
-->]
 {ait},
{ait},
 {ain}, (p017end-p018begin)
{ain}, (p017end-p018begin)
 {aip},
{aip},
 {aim}.
{aim}.
[
{u.} -->]
 {oat},
{oat},
 {oan},
{oan},
 {oap},
{oap},
 {oam}.
{oam}.
[
{é} -->]
[
{au:} -->]
{auk},
 {aún}.
{aún}.
[
{o} -->]
{eik},
 {eín}
{eín}
- {o},
 {oäm}. This last is the same as
{oam} noticed before.
{oäm}. This last is the same as
{oam} noticed before.
§073. These combinations are termed by the phrase

 {ka.ré
ka.þût} -
{kak},
viz. a final
{k} following
{ka.ré
ka.þût} -
{kak},
viz. a final
{k} following
 {ka.}, because the first of them is
thus formed.
{ka.}, because the first of them is
thus formed.
UKT 210206: I opine that the phrase "
{ka.ré
ka.þût}" is wrong. It should have been " {ka.kri: a·þût}"
or something else.
{ka.kri: a·þût}"
or something else.
UKT 210113: You'll see a continuation in §076 below
Below in §074, Carey has made a grave mistake. He seems to think that when
we check the vowels, it is the vowel-letter that is being checked. It is
not. For example, it is not
{I.} इ that we are checking. It is
{i.}
अि , which Arial-MS rendering engine would not accept. However changing अ to
क, we get कित् =
{kait} . Romabama, like IPA, does not use what is commonly called "Magic E"
by English kindergarten teachers. If only Romabama would accept the magic-e,
the transcription would be kate .
§074. The simple combinations may be divided into 5
sorts, viz.
- first, coda final consonants following [the vowel]
{a.} [
/a/ ]
- secondly, those [coda] following the vowel
{I.} [
{i.}
/i/ ]
- thirdly, those [coda] following the vowel
{U.} [
{u.} /ʌ/ ]
[Carey has missed the vowel
{É}/
{é} /e/ which would have made 5 sorts into 6]
- fourthly, those [coda] following the vowel
{AU} [
{au} /ɑ/ ], and
- fifthly, those [coda] following [the vowel - not diphthong]
{o} [ /o/ ]
These constitutes the first table.
UKT 210113: Because F. Carey has used the word "table", I was expecting a
tabular form. It is not so: his "table" meant something else.
§075. The other six tables are formed by insertion
of the symbols
-
 {ya.pín.}
{ya.pín.}
 ,
,
 {ra.ric}
{ra.ric}
 /
/ ,
,
 {wa.hswè:}
{wa.hswè:}

-
{ya.pín.wa.hswè:}
 ,
{ra.ric-wa.hswè:}
,
{ra.ric-wa.hswè:}
 /
/ and
and
-
 {ha.hto:}
{ha.hto:}
 immediately after the initial consonant.
immediately after the initial consonant.
§076. [The killed consonants which are the
same as Letters of the Alphabet-Letter system ]
------------------- c1
------------ c5
codas of
r1 -
{k} /k/,
-----
{ng} /ŋ/
codas of
r2 -
 {c} /c/, -----
{c} /c/, -----
 {Ñ} /ɲ/,
{Ñ} /ɲ/,
codas of
r4 -
{t} /t/, -----
{n} /n/
codas of
r5 -
 {p} /p/, -----
{p} /p/, -----
 {m} /m/
{m} /m/
codas of
r6 -
 {ý} /j/, and
{ý} /j/, and
 {w} /o/,
{w} /o/,
viz. 'the first [c1] and last [c2] letters of the first [r1], second [r2],
fourth [r4], and fifth [r5] rows classes, and {ya.} and {wa.}
of the approximants miscellaneous (p018end-p019begin)
letters are properly termed
 -
- {þût ak~hka.ra.} which means akshara
{þût ak~hka.ra.} which means akshara letters "killed" or
"destroyed ", viz. deprived of their inherent vowel
{mwé-hkän þa.ra.} . [see
§073]
UKT 210114: It seems that Carey has noticed that in regular Bur-Myan it
is only the tenuis and nasal can be killed. However it is not the case in
Pali-Myan.
§077. The above final consonants [coda]
are affixed in regular order to all the base simple consonants,
and to all those medials compounded with the following symbols
-
{ya.pín.}
,
{ra.ric}
/
,
{wa.hswè:}
-
{ya.pín.wa.hswè:}
,
{ra.ric-wa.hswè:}
/
and
-
{ha.hto:}
;
and also when they are combined with the vowels [UKT: It is unfortunate that
Carey had not realized that in Bur-Myan, unlike Skt-Dev, Vowel-Letters do not
appear as nuclear vowel V, of the syllable CVÇ.
-
{a.} [
/a/ ]
-
{I.} [
{i.}
/i/ ]
-
{U.} [
{u.} /ʌ/ ]
[ -
{É} or
{é} /e/ - missing in Carey]
-
{AU} [
{au} /ɔ/ or /ɑ/ ]
-
{o} [ /o/ ]
which union occasions the following changes in the coda final
consonant and the preceding [nuclear} vowel
{Ñu-ka.li þa·ra.}.
Contents of this page
TABLE I. Base consonants as Onsets
I could not find where Carey began his TABLE I.
This place is only my assumption.
Rimes with Vowel /æ/
{a.}
Of final
Consonants following the Vowel
{a.}
UKT 210118: Carey in 1814 did not know the idea of rime and the syllable.
I can imagine how difficult it must have been to study Burmese Grammar.
"A distinction between the spellings is also sometimes made in the study of
linguistics and
phonology
for which rime/rhyme is used to refer to the
nucleus and
coda of a
syllable.
"- https://en.wikipedia.org/wiki/Rhyme 210117
and
"A syllable is a unit of organization for a sequence of
speech sounds. It is typically made up of a syllable nucleus (most often a
vowel) with
optional initial and final margins (typically,
consonants).
Syllables are often considered the
phonological
"building blocks" of words.
[1] "-
https://en.wikipedia.org/wiki/Syllable#Rime 210117
If only he had,
the above caption would be Rimes with Vowel
{a.}. Since, from the examples given by Carey,
{a.} is the inherent vowel of the Onset consonants, the vowel he meant must
have been the short English a or /æ/. Below, he treats the Codas row
by row. It is unfortunate that in the first example below his Onset is
{ka.} and the Coda
{k} of the same row. He should have chosen the Onset and Coda from different
rows, e.g.
 {tak} - Onset from row#4 and Coda from row#1.
{tak} - Onset from row#4 and Coda from row#1.
Codas of r1 -
{k} /k/ and
{ng} /ŋ/
§078. [The killed consonant
{ka.} which has become]
{k} /k/ after another consonant, thus,
{kak} <ket> , occasions the inherent vowel of the onset initial consonant to
take the sound of the short e in < let >, and the final
{k} to assume the of t in <et>, which is sounded but very slightly.
UKT 210114: Carey's observation above is wrong. The word
{kak} is pronounced with an "open" vowel as in a . Secondly, he has
given the wrong coda: it is k and not t :
{kût}. Notice the influence of coda on the nuclear vowel.
§079. [The killed r1c5
{gna.} which has become]
{ng}
placed after another consonant, thus,
 {kín}, occasions the vowel of the initial
akshara
{kín}, occasions the vowel of the initial
akshara letter to take (p019end-p020begin)
the sound of e in <pen>. No material alteration takes place in the
sound of the final
{ng},
except what is occasioned by the absence of the inherent vowel.
Codas of r2 -
{c} /c/ and
{Ñ} /ɲ/
§080. [The killed r2c1
 {sa.} which has become]
{c} placed after a consonant [
{ka.}], thus
{sa.} which has become]
{c} placed after a consonant [
{ka.}], thus
 {kic} <keet> [wrong pronunciation] occasions the preceding vowel
[nuclear /a/] to take the sound of ee [/i/] and the coda
{kic} <keet> [wrong pronunciation] occasions the preceding vowel
[nuclear /a/] to take the sound of ee [/i/] and the coda final
to take the sound of t as in <sheet>.
§081. [The killed r2c5
 {Ña.} which has become]
{Ñ}, thus
<kee>, causes the preceding vowel to take the sound of ee in <see>. In
this instance the sound of coda
{Ña.} which has become]
{Ñ}, thus
<kee>, causes the preceding vowel to take the sound of ee in <see>. In
this instance the sound of coda final consonant is sometimes
retained, and sometimes suppressed. Examp.
 {kræÑ} <kree>, or popularly <kėe> "bright", "clear",
<kreen>, or popularly <keen>
"see", "behold"'
{kræÑ} <kree>, or popularly <kėe> "bright", "clear",
<kreen>, or popularly <keen>
"see", "behold"'
UKT 210116: Carey's pronunciations in the above
Examp. are totally wrong.
Codas of r4 -
{t} /t/ and
{n} /n/
[UKT: dentals]
Codas of
r5 -
{p} /p/ and
{m} /m/
[UKT: bilabials - Eng-Lat has no bilabials but only labio-dentals
which must have lead to wrong pronunciations.]
Codas of
r6 -
{ý} /j/, and
{w} /o/,
[UKT: approximants - traditionally IE speakers used to rhotic
accent are familiar with /r/ but not with /j/. So Carey's judgment of /j/ would
tend to be wrong. Moreover, English speakers are not well-versed in /w/: they
cannot pronounce the Welsh names right!]
§082. [The following are
codas Ç of syllables CVÇ] -
codas of r4 -
{t} /t/ and
{n} /n/;
codas of r5 -
{p} /p/ and
{m} /m/;
codas of r6 -
{ý} /j/, and
{w} /o/,
placed after a consonant [onset and its
inherent vowel: Carey has taken the Onset as
{ka.}], thus,
-
{kût} <kat>,
 {kûn} <kan> ;
{kûn} <kan> ;
-
{kûp} <kat>,
{kûm} <kam>, and
-
 {kèý} <kay>,
{kèý} <kay>,
occasion the inherent vowel of the onset initial consonant, to
assume the sound of a in <pan>. [UKT: I've given the Romabama
transcription: Carey's statement is in doubt. He has no idea of rime, VÇ, of a
syllable CVÇ. See below.]
The codas final consonants retain their proper
sound, except
{p}, which is sounded like t in <cat-gut>, and
{m}, which is sounded like n in <can>.
(p020end-p021begin)
§083. When
{w} is put after a preceding consonant, the symbol of the vowel
{AU.} is affixed
to the initial, as
 {kauO} <kau>.
{kauO} <kau>.
In this case the vowel
{AU.}
has a long sound resembling au as in <fraud>, <caught>. The
{w} is mute, and in writing is generally dropped.
UKT 210117: In my young days what caught my attention was the phrase "May
Devas and Men call out Tha'du"

 {nût-lu-þa-du. hkau-sé-þauO", spelled with
{w}, in inscriptions commonly found on works of merit on walls and places of
prominence. I didn't find any
{kauO}:
the present spelling is
{nût-lu-þa-du. hkau-sé-þauO", spelled with
{w}, in inscriptions commonly found on works of merit on walls and places of
prominence. I didn't find any
{kauO}:
the present spelling is
 {kau}.
{kau}.
N.B. The inherent vowel
{mwé-hkän þa.ra.}
{a.} [of
 {wa.}]
when followed by
{n} or
{m}, is also sometimes pronounced like
{U.}, as in
{wa.}]
when followed by
{n} or
{m}, is also sometimes pronounced like
{U.}, as in
 {wûn}
<a burden>, and
{wûn}
<a burden>, and
 {wûm-pè:}
<a duck>.
{wûm-pè:}
<a duck>.
UKT 210118: Carey has given <duck> as
{wûm-pè:}
in 1814. But 200 years later, we are spelling
 {wûm:Bè:}. If at present, if somebody were to say
{wûm-pè:},
we would still understand that he meant
{wûm:Bè:}. This shows we regularly use disyllables instead of monosyllables.
{wûm:Bè:}. If at present, if somebody were to say
{wûm-pè:},
we would still understand that he meant
{wûm:Bè:}. This shows we regularly use disyllables instead of monosyllables.
Contents of this page
Rimes with vowel /i/
{i.}
Of final Consonants after the Vowel
{I.}
§084. [The filled consonants]
{t},
{n};
{p},
{m}, placed after a consonant combined with the vowel
{I.}, thus
 {ki.}, occasion the vowel
{a.} to take the sound of i in <thine>. Ex.
{ki.}, occasion the vowel
{a.} to take the sound of i in <thine>. Ex.
-
 {kait} <kit>,
{kait} <kit>,
 {kain} <king>
{kain} <king>
-
{kaip} <kit>, and
 {kaim} <king}
{kaim} <king}
The sound of the final consonants is very short and abrupt, as to be scarcely
discerned.
Frequently however
{p} is sounded like
{t}, and
{n} like
{m}.
(p021end-p022begin)
Contents of this page
Rimes with vowel
/u/
{u.}

Of a final Consonant after the Vowel
{U.}
UKT 210118, 210128: Carey is a very careful observer:
yet he is giving
{U.} in the caption, and below
{U.}. He must be getting inputs from Mon-Myan vowels shown on the right.
As a side note, notice Mon-Myan /i/ pair is
- which is not logical; it should be
which is not logical; it should be
 -
. Bur-Myan on the other hand has
-
-
. Bur-Myan on the other hand has
- -
- which is also strange. Why is there no
?
Then we could have the pair
-
which would be logical. I suspect - suspect - there was another
circularly-rounded script which might be older.
which is also strange. Why is there no
?
Then we could have the pair
-
which would be logical. I suspect - suspect - there was another
circularly-rounded script which might be older.
§085. [The killed consonants of row#4 and row#5]
{t},
{n};
{p},
{m}, placed after a consonant combined with the vowel
{U.}, thus
 {ku.} <koo>, occasion the vowel <oo> to assume the sound of o
in <yoke>. Ex.
{ku.} <koo>, occasion the vowel <oo> to assume the sound of o
in <yoke>. Ex.
-
 {koat} <kok> ,
{koat} <kok> ,
 {koan} <kong>
{koan} <kong>
-
 {koap} <kok> ,
{koap} <kok> ,
 {koam} <kong>
{koam} <kong>
Here the final
{t} and
{p} acquire the sound of k in <yoke>, and
{n} and
{m} have the sound of ng . [What does he mean by "sound of ng"
?]
Contents of this page
Rimes with vowel
/ɔ/
{au.}
Of final Consonants following Vowel
{AU}
§086. [The Codas of row#1]
{k} /k/ and
{ng} /ŋ/ placed after an Onset
a consonant, combined with
{AU} /ɔ/ thus,
{kau} <kau>, occasion the sound of the
short digraph diphthong
<au> to be changed to that of ou
in <lounge>. Ex.
-
 {kauk} <kouk>,
{kauk} <kouk>,
 {kaún} <koung>.
{kaún} <koung>.
Contents of this page
Rimes with vowel
/o/
{o}
Of final Consonants following the Vowel
{o}
UKT 210119: The vowel
{o}, is a monophthong, yet most scholars think it is a diphthong. Their mistake
comes from how its spelling is described:
- {a. loän: tín} "place a circle over
{a.}" - but you don't make the sound
{i.}
-
and then you are asked to
{a. loän: tín} "place a circle over
{a.}" - but you don't make the sound
{i.}
-
and then you are asked to
 {hkaún: gnín} "draw a line to it". You don't "glide" from
{i.}
to
{u.}, and then to
{o}.
{hkaún: gnín} "draw a line to it". You don't "glide" from
{i.}
to
{u.}, and then to
{o}.
It is said that there are 4 diphthongs <ei> <ai> <au> and <ou> in
Bur-Myan language, which I dispute. They are all "digraphs". See also my
paper, dated 2011-12-31, "English Phonetics and Phonology for
Burmese-Myanmar speakers", which is based on English Phonetics
and Phonology, by Peter Roach, 2nd ed., 4th printing 1993. -
https://www.tuninst.net/ENG-PHON/Eng-diphth/diphth.htm#Diphthongs (link
chk 210119)
§087. [The vowel]
{o} is a compound vowel formed by the union of the symbols of
{I.} and
{U.}, and may be joined with any one of the basic simple
consonants, or medials those compounded with
[Ya'pin]
, and [Ra'ric]
/
, [Carey's examples are shown below]
[Wa'hsè]
, [Ya'pin-wa'hswè]
, and [Ra'ric-wa'hswè]
/
[Carey does not give examples]
thus [with basic consonants]
 {ko},
{ko},
 {hko}
{hko}
[with medials
 {kyo} ,
{kyo} ,
 {hkyo} ,
{hkyo} ,
 {kro} ]
{kro} ]
This vowel diphthong has the power of o in <yoke>.
(p022end-p023begin)
Contents of this page
§088. When
{k} and
{ng} are placed after the above vowel diphthong combined with a
consonant, thus,
 {keik} <kaik>,
{keik} <kaik>,
 {keín} <kaing>, the sound of o is changed to that of <ai>.
{keín} <kaing>, the sound of o is changed to that of <ai>.
Contents of this page
UKT 210206: The letter w is controversial in English as a Germanic
language. The English w is German v . This is reflected in
Bur-Myan and Skt-Dev. Bur-Myan
{wa.} (bi-labial) is Skt-Dev (and also in International Pali) «va»
{labio-dental). Moreover in Bur-Myan {wa.} becomes more controversial as a
coda
{w} or
 {wa.þût} .
{wa.þût} .
§089. When
{w} is placed after the above diphthong, it occasions no difference in the
sound, and in writing may be retained or dropped at pleasure.
UKT 210119: In the sequence
{o} -->
 {bo} -->
{bo} -->
 {bol}, the 2 words
{bo} and
{bol} have the same pronunciation, yet they have different meanings.
{bo} - "an astrological term";
{bol} "chief, army officer". In Bur-Myan "spelling" is more important than
pronunciation.
{bol}, the 2 words
{bo} and
{bol} have the same pronunciation, yet they have different meanings.
{bo} - "an astrological term";
{bol} "chief, army officer". In Bur-Myan "spelling" is more important than
pronunciation.
UKT 210119: Note that though Engl-Lat has the bilabial
{wa.}/
{w}, other IE languages may or may not have it. Thus what the Hindi-Dev and
Skt-Dev have is labio-dental
 {va.}/
{va.}/
 {v}, and Romabama has to include it for studying BEPS languages.
{v}, and Romabama has to include it for studying BEPS languages.
N.B. For the sake of conveying a better idea of these combinations, the
first table with its powers, is here inserted at large, a clear idea of which
being obtained, the rest may be easily understood.
UKT 210128: Each of the following tables has two parts.
The first part describes the Medials modified by various medials, /æ/, /i/,
/u/, /é/, /ɔ/, /ɑ/, /o/
The second part gives Onsets of syllables with Medial and its
modified forms
- the "inherent vowel" of the medial behaving as the Nuclear vowel of
the Syllable.
Contents of this page
UKT 210130:

See also:
https://en.wikipedia.org/wiki/Uvular_consonant 210201
"English has no uvular consonants (at least in most major dialects), and
they are unknown in the indigenous languages of Australia and the Pacific,
though uvular consonants separate from
velar consonants are believed to have existed in the Proto-Oceanic
language and are attested in the modern Formosan languages of Taiwan. Uvular
consonants are however found in many African and Middle-Eastern languages,
most notably Arabic, and in Native American languages. In
parts of the Caucasus mountains and north-western North America, nearly every
language has uvular stops and fricatives. Two
uvular R phonemes are found in various languages in north-western Europe
including French, some Occitan dialects, a majority of German dialects, some
Dutch dialects, and Danish.
The voiceless uvular stops
 {kwa.} (1 eye-blink) and
{kwa.} (1 eye-blink) and
 {kwa} (2 blnk) are transcribed as
[q] in both the IPA and
SAMPA. It is
pronounced somewhat like the
voiceless velar stop
[k], but with the middle of the tongue further back on the
velum, against or near the uvula. The most familiar use will doubtless
be in the transliteration of Arabic place names such as Qatar and
Iraq into English, though, since English lacks this sound, this is
generally pronounced as
[k], the most similar sound that occurs in English.
{kwa} (2 blnk) are transcribed as
[q] in both the IPA and
SAMPA. It is
pronounced somewhat like the
voiceless velar stop
[k], but with the middle of the tongue further back on the
velum, against or near the uvula. The most familiar use will doubtless
be in the transliteration of Arabic place names such as Qatar and
Iraq into English, though, since English lacks this sound, this is
generally pronounced as
[k], the most similar sound that occurs in English.

See also
LINGVA LATINA, by Hans H. Ørberg, 1998
in TIL HD-PDF and SD-PDF libraries: -
HHOrberg-LingvaLatinaVocab<Ô> / Bko<Ô>
On the right are shown some Roman-Latin
words from p030 of LINGVA LATINA, by Hans H. Ørberg. Notice how Latin <quā> sounds like
Bur-Myan
{kwa}, and <quam> like {kwûm}. The POA (place
of articulation) of letter < q > is
uvular which is produced with the back
of the tongue touching the uvula, i.e.
further back in the mouth than the velar
consonants.
Go back Uvular-consonants-note-b
Contents of this page
End of TIL file